AutoML(V7.1)¶
2021年6月14日
DataRobot v7.1.0リリースには以下に示す多くの新しいUIとAPI機能が含まれています。詳細については、時系列の新機能も参照してください。
DataRobotの有効期限切れが近い古い機能に関するサポート変更については、廃止に関する重要な告知を参照してください。このドキュメントには、DataRobotの修正された問題も記載されています。
リリースv7.1.0では、以下の言語のUI文字列の翻訳が更新されています。
- 日本語
- フランス語
- スペイン語
機能のハイライト¶
リリース7.1の主な新機能には以下が含まれます。
新しいドキュメントエクスペリエンス¶
このリリースでは、DataRobotプラットフォームアプリケーションユーザー向けの新しいドキュメントエクスペリエンスが導入されています。

新しい外観に加えて、エンドツーエンドのモデリングワークフローをより適切に反映するように組織を変更しました。コンテンツが追加され、ドキュメントリソースへより簡単にアクセスできるよう移動されました。以下に具体例を示します。
-
コンテンツの変更:
- DataRobot Data Prepドキュメントは、従来の場所でも入手できますが、プラットフォームサイトからもアクセスできるようになりました。
- DataRobot用語集が利用可能です。これの内容は今後も追加される予定です。
- APIドキュメント(クイックスタートとREST API、Pythonクライアント、およびR クライアントのドキュメント)は、サイト内から起動できます。
-
画像をズームして詳細を確認します。画像にカーソルを合わせると、拡大鏡が表示されます。画像を1回クリックして画面内で拡大し、もう一度クリックすると先程のページに戻ります。

-
ブック(左側)およびページ固有(右側)の目次により、ナビゲーションが容易になります。

このサイトは拡張を続け、ノートブックとチュートリアルのコンテンツが間もなく追加される予定です。ご質問、コメント、ご提案はdocs@datarobot.comまでメールでお送りください。
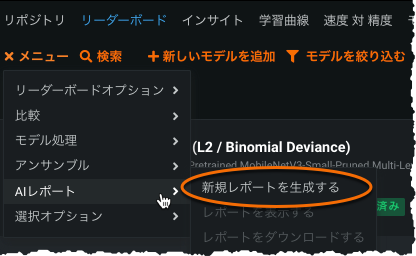
自動化されたAIレポート¶
このリリースでは、DataRobotのAIレポート(モデリング構築プロセスの高度な概要を説明するドキュメント)を作成してダウンロードすることができるようになりました。

このレポートにより、プロジェクトの最も重要な調査結果のサマリーを取得し、簡単に利用できる形式で利害関係者に提示できるようになります。速度や交差検定スコアなど、最高のパフォーマンスを発揮するモデルの精度に関するインサイトを提供します。また、最高のパフォーマンスを発揮するモデルの特徴量のインパクトヒストグラムから解釈可能性のインサイトもキャプチャします。AIレポートで生成された詳細なモデルの説明、パフォーマンス指標、および倫理のインサイトは、AIプロジェクトに対する全体的な信頼を構築し、主要な利害関係者に価値を証明するのに役立ちます。
特徴量探索Snowflakeインテグレーション¶
DataRobotとSnowflakeのインテグレーションにより、共同ユーザーは、有益な場合に、Snowflakeで計算を実行しながら、DataRobotで特徴量探索プロジェクトを実行できます。このインテグレーションにより、データの移動が最小限に抑えられ、より迅速で精度が高く、費用対効果も高い新しいモデル特徴量の計算を実現できます。DataRobotは、プロジェクト用に設定されたすべてのセカンダリーデータセットが動的であり、Snowflakeのテーブルを参照しているかどうかを検出します。そうである場合、DataRobotは結合とフィルタリング操作をSnowflakeに自動的にプッシュし、小さな結果セットをDataRobotにロードします。より小さなデータセットから特徴量探索が開始されるようになったので、DataRobotプロジェクトのランタイムが短縮されます。

ベータ:AIアプリビルダーを使用した専用のAIアプリケーション¶
AIアプリビルダーは、コーディングの経験がないユーザーが、視覚的でインタラクティブなインターフェイスでAIを利用したアプリケーションを起動、設定、共有できるようにします。予測の共有および利用を簡単に行うことができ、機械学習のユースケースの意思決定を最適化して、データからより多くの価値を提供します。
アプリケーションギャラリーからデプロイされたアプリと同様に、各アプリケーションはアプリケーションタイプとデータソース(AIカタログ内のデプロイまたはデータセットのいずれか)で始まります。ただし、アプリビルダーでは、追加のウィジェット、カスタム機能、およびページを設定して、特定のユースケースに合わせてアプリケーションを調整することができます。
アプリケーション > 現在のアプリケーションで、既存のアプリケーションのリストを表示し、+アプリケーションを作成するをクリックして、AIアプリビルダーで新しいアプリケーションを作成します。

編集モードで、ページを作成し、インサイトを整理してから、ヘッダーとチャートウィジェットをドラッグアンドドロップします。特定のユースケースに合わせてアプリケーションを調整します。
AutoMLの新機能と機能強化¶
以下に、リリースv7.1.0の新しいAutoMLの機能を示します。
- Keras固有のトレーニングダッシュボード
- 特徴量探索で異常検知がサポートされるようになりました
- イメージデータセットの新しいブループリントと高度なチューニングパラメーター
- 特徴量探索でのDynamic Spark SQLのサポート
- Tiny BERTの事前トレーニング済みフィーチャライザーの実装によるNLPの拡張
- 多クラスプロジェクトのモデルコンプライアンスドキュメント
- Eureqaトレーニング動作の改善
- ベータ:特徴量探索の関係性の品質評価
Keras固有のトレーニングダッシュボード¶
トレーニングダッシュボードタブは、実行された候補モデルごとに、時間の経過に伴うさまざまなハイパーパラメーターの視覚化を提供します。つまり、モデルのトレーニング中に何が起こったか、モデルがデータにどの程度適合しているかを理解するのに役立ちます。このタブでは、すべての反復にわたるトレーニングとテストの損失、精度、学習率、およびモーメンタムの領域を視覚化できます。候補モデルを選択して比較します。設定を変更して表示を変更し、解釈しやすくします。
このタブにある情報を使用し、最終モデルを改善するためにチューニングするパラメーターについて情報に基づく決定を行うことができます。ダッシュボードから、各パラメーターがモデルのパフォーマンスに与える影響を評価できます。また、高度なチューニングタブへの直接リンクをクリックすると、モデルをさらにチューニングしてテストできます。

特徴量探索で異常検知がサポートされるようになりました¶
一般提供:現在利用可能な機能として、特徴量探索のセカンダリーデータセット機能を利用して異常を検知できるようになりました。教師なし学習(ターゲットなし)が有効な状態でセカンダリーデータセットを追加した場合、特徴量探索では、セカンダリーデータセットから特徴量を抽出して異常が検知され、DataRobotの外部で特徴量エンジニアリングをスクリプト化する必要がなくなります。

イメージデータセットの新しいブループリントと高度なチューニングパラメーター¶
このリリースでは、事前にトレーニングされたアーキテクチャのブループリントを使用して、ディープラーニング畳み込みニューラルネットワーク(CNN)のファインチューニングを利用できるようになります。小さなデータセットでCNNをトレーニングすると、ディープ畳み込みネットワークの一般化能力に大きな影響を与え、過剰適合を引き起こすことがあります。ファインチューニングは、事前にトレーニングされたネットワークモデルを取得し、それを2番目の類似するタスクに適用する一方で、レイヤーのトレーニング可能な範囲と学習率をさらにカスタマイズできるプロセスです。プロジェクトが大きく、事前にトレーニングされたデータセットとコンテキストが大幅に異なる場合、ファインチューニングによりCNNのパフォーマンスと精度が向上することがよくあります。場合によっては、事前にトレーニングされたデータセットのコンテキストに近ければ、小さなデータセットでも基本の事前トレーニングされたCNNフューチャライザーよりもパフォーマンスが優れていることもあります。トレーニングダッシュボードから、指標スコア、各レイヤーの学習率、および各反復の一般的な学習率を調査できます。
特徴量探索でのDynamic Spark SQLのサポート¶
一般提供:特徴量探索セカンダリーデータセットの場合、DataRobotはAIカタログ内からSpark SQLクエリーを使用して、スナップショットデータセットの強化、変換、整形、およびアンサンブルを行う機能を提供します。ベータ機能として最初に導入され、現在は一般提供されていますが、DataRobotは特徴量探索プロジェクトのセカンダリーデータセットで、動的Spark SQLのサポートを追加します。この新機能により、基本的なデータ準備を実行するときの柔軟性が向上します。認証要件は同じままです。
Tiny BERTの事前トレーニング済みフィーチャライザーの実装によるNLPの拡張¶
一般提供:BERT(Transformersからの双方向エンコーダー表現)は、自然言語処理(NLP)転移学習に関するトランスフォーマーに基づくGoogleのデファクトスタンダードです。Tiny BERT(または、蒸留して軽量化した任意のBERTバージョン)が、DataRobotリポジトリの特定のブループリントで利用できるようになりました。これらのブループリントは、ファインチューニングを必要としないVisual Artificial Intelligence (AI)フィーチャライザーと同様に、NLPフィールドで事前にトレーニングされた特徴量抽出を提供します。ただし、最大限の柔軟性を実現するために、DataRobotの実装には2つの調整可能な追加のプーリングパラメーター(最大プーリングと平均プーリング)が用意されています。Tiny BERTブループリントは、UIユーザーとAPIユーザーの両方が利用できます。

多クラスプロジェクトのモデルコンプライアンスドキュメント¶
モデルコンプライアンスドキュメントが多クラスモデルをサポートするようになりました。ユーザーは、規制の厳しい業界でのモデルのデプロイを支援するドキュメントを自動的に生成およびダウンロードできます。組織で利用できる場合は、各モデルに対して個々のドキュメントを生成し、効果的なモデルリスク管理に関する包括的なガイダンスを提供できます。レポートは、編集可能なMicrosoft Wordドキュメント(.docx)としてダウンロードできます。以前は連続値と分類でのみ利用可能でしたが、最大100クラスのプロジェクトにこのドキュメントを含めることができるようになりました。モデルのプロジェクトリーダーボードのコンプライアンスタブからモデルコンプライアンスドキュメントを作成するオプションにアクセスします。

Eureqaトレーニング動作の改善¶
このリリースでは、GAMおよび従来のEureqaモデルに250世代(1000世代に匹敵する精度を提供)を使用する新しいEureqaブループリントが追加されています。これらの250世代のブループリントを追加すると、オートパイロットの一部(クリックではなく、フルの一部として利用可能)としてEureqaが自動的に含むプロジェクトの種類が増えます。他のEureqa世代数モデルは、引き続きリポジトリから入手できます。AutoMLおよび時系列プロジェクトでいつどのモデルを使用できるかについての詳細は、Eureqaのドキュメントを参照してください。
ベータ:特徴量探索の関係性の品質評価¶
このリリースでベータ機能として導入された特徴量探索は、関係性設定の品質を自動的に評価するツールが導入されていて、作成プロセスの早い段階で潜在的な問題がユーザーに警告されます。このツールは、結合キー、データセットの選択、および時間認識設定を検証します。EDA2が開始する前:

設定を確認ボタンをクリックして、関係性の品質評価をトリガーします。進行状況インジケーター(スピナーの読み込み)が各データセットと無効になっている[設定を確認]ボタンに表示され、評価が現在実行中であることを示します。評価が完了すると、DataRobotはテストされたすべてのデータセットにマークを付けます。問題が特定されたものには黄色の注意アイコンが表示され、問題が特定されていないものには緑色のチェックマークが表示されます。

データセットを選択して、提案された潜在的な修正を含む問題のサマリーを表示します。
APIの強化¶
以下は、APIの新しい機能と強化のサマリーです。各クライアントのAPIドキュメント用のAPIサポートページを参照してください。
新機能¶
次の新機能がAPIリリースv2.25.0に追加されました。
異常評価のインサイトへの変更¶
Shapley値の計算をサポートする時系列教師なしプロジェクトの異常評価のインサイトを計算、取得、および削除する機能を追加します。
-
指定されたサブセットの異常評価のインサイトを初期化します。
POST /api/v2/projects/(projectId)/models/(modelId)/anomalyAssessmentInitialization/ -
異常評価レコード、SHAPの説明、予測のプレビューを取得します。
GET /api/v2/projects/(projectId)/anomalyAssessmentRecords/GET /api/v2/projects/(projectId)/anomalyAssessmentRecords/(recordId)/explanations/GET /api/v2/projects/(projectId)/anomalyAssessmentRecords/(recordId)/predictionsPreview/ -
異常評価レコードの削除:
DELETE /api/v2/projects/(projectId)/anomalyAssessmentRecords/(recordId)/
Sparkデータセットのベースとなるエンティティのカスケード共有¶
次のエンドポイントを使用して、Sparkデータセットのベースとなるエンティティのカスケード共有を追加します。
PATCH /api/v2/datasets/(datasetId)/sharedRoles/
時間経過に伴う異常の各プロットの計算と取得¶
教師なしの日付/時刻パーティショニングされたモデルの時間経過に伴う異常の各プロットを計算および取得する機能を追加します。
-
時間経過に伴う異常の各プロットの計算:
POST /api/v2/projects/(projectId)/datetimeModels/(modelId)/datetimeTrendPlots/ -
時間経過に伴う異常のメタデータの取得:
GET /api/v2/projects/(projectId)/datetimeModels/(modelId)/anomalyOverTimePlots/metadata/ -
時間経過に伴う異常のプロットの取得:
GET /api/v2/projects/(projectId)/datetimeModels/(modelId)/anomalyOverTimePlots/ -
時間経過に伴う異常のプレビュープロットの取得:
GET /api/v2/projects/(projectId)/datetimeModels/(modelId)/anomalyOverTimePlots/preview/
機能強化¶
EDA中に計算されたisZeroInflatedプロパティが、次のエンドポイントに追加されました。
GET /api/v2/datasets/\(datasetId\)/allFeaturesDetails/
GET /api/v2/datasets/\(datasetId\)/versions/\(datasetVersionId\)/allFeaturesDetails/
GET /api/v2/projects/\(projectId\)/features/
GET /api/v2/projects/\(projectId\)/features/\(featurename:featureName\)/
GET /api/v2/projects/\(projectId\)/modelingFeatures/
GET /api/v2/projects/\(projectId\)/modelingFeatures/\(featurename:featureName\)/
変更点¶
ディレクトリとして解釈する必要がある場合、エンドポイントPOST /api/v2/batchPredictions/のバッチ予測(GCP、S3、Azure)用のクラウドアダプターのintakeSettingsおよびoutputSettingsは、入力および/または出力URLフィールドが「/」で終わることを公式に想定するようになりました。それ以外の場合は、単一のファイルとして解釈されます。
ヒント
PythonおよびRの最新のAPIクライアントに更新することが強く推奨されます。
廃止の通知¶
備考:新しいリリース移行への適切な計画を立てるために、次の点に注意してください。
使用非推奨スケールアウトモデル¶
スケールアウトモデルは将来のリリースで廃止される予定なので、新しいモデルのトレーニングには使用しないでください。
お客様から報告された問題の修正¶
7.0.2以降のリリースでは、以下の問題が修正されています。
特徴量探索¶
- SAFER-3632:環境変数からSpark設定をオーバーライドして、個々の顧客のデプロイ用にアプリをカスタマイズし、特徴量探索プロジェクトの問題を修正しました。
プラットフォーム¶
-
PLT-3052:名前に特殊記号を含むグループのLDAPグループマッピングを修正しました。
-
EP-872:「read_only_containers」がTrueの場合、「ワーカープロセス内のバイナリファイルの変換を有効化」によって、Parquetファイルの取込みができるようになりました。
-
EP-1062:HTTPSプロキシの背後でAWS CloudWatchに接続するときに、BotoライブラリのPython3の非互換性が原因で発生していた問題が修正されました。
-
EP-1307:サポートされている場合に新規インストールに対して適切に有効化できるよう
PYTHON3_SERVICESを含むクラスターインストールの設定例を追加し、コメントアウトしました。
予測¶
-
PRED-5919:デプロイページからデプロイのテストデータセットの予測リクエストを行うときに複数のダウンロードを引き起こしていた問題を修正しました。
-
PRED-5976:オンプレミスの仕様に一致するように設定可能な特徴量セットを更新しました。