最適化指標¶
最適化指標ドロップダウンから使用できる全ての指標と短い説明を次の表に示します。 このセクションの表にインターネットの情報に基づく詳細な説明を示します。
ヒント
スコアリングモデルで選択される指標は、通常、最良の選択オプションです。 指標の変更は高度な機能なので、指標およびその背後にあるアルゴリズムが十分に理解されている場合にのみ推奨されます。 推奨方法については、推奨される指標を参照してください。
加重指標の場合、加重はスマートダウンサンプリングおよび高度なオプションの加重パラメーターの値の指定に基づきます。これによって、評価指標の計算において、それらのウェイトが考慮されるようになります。 使用する指標はプロジェクトタイプに応じて異なります。 プロジェクトタイプは、R(連続値)、C(二値分類)、またはM(多クラス)です。
真陰性/偽陰性(true/False Negatives)および真陽性/偽陽性(true/False Positives)とは。
以下の定義について考えてみましょう。
- Trueは予測が正しかったことを意味し、Falseは予測が間違っていたたことを意味します。
- Positiveはモデルが陽性と予測したことを意味し、Negativeは陰性と予測されたことを意味します。
これらの定義に基づくと:
- True Positivesとは、陽性として正しく予測された観測値です。
- True negativesは、陰性として正しく予測された観測値です。
- False Positivesとは、陽性として間違って予測された観測値です。
- False Negativesは、陰性として間違って予測された観測値です。
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| 精度 | 精度 | サブセットに対する正解率を計算します。サンプルに対して予測されたラベルのセットは、y_trueのラベルの対応するセットに完全に一致する必要があります。 | 二値分類、多クラス |
| AUC/加重AUC | (ROC)曲線下の領域 | 正例と負例を識別する能力を測定します。多クラスの場合、AUCは各クラスについて一対多で計算された後にクラスの出現頻度に基づいた加重平均を行います。 | 二値分類、多クラス、多ラベル |
| PR曲線の下の領域 | PR(プレシジョン–リコール)曲線の下の領域 | プレシジョン-リコール曲線下の領域の近似。陽性的中率とリコールを1つのスコアにまとめます。 不均衡なターゲットに適しています。 | 二値分類、多ラベル |
| 均衡正解率 | 均衡正解率 | クラスごとにone-vs-allで計算された正解率の平均を提供します。 | 多クラス |
| FVE Binomial/加重FVE Binomial | 分散の割合の説明 | 二項分布のフィッティングに基づいて尤離度を測定します。 | 二値分類 |
| FVE Gamma/加重FVE Gamma | 分散の割合の説明 | Gamma Devianceの場合、FVEを提供します。 | 連続値 |
| FVE多項/加重FVE多項 | 分散の割合の説明 | 多項分布のフィッティングに基づいて尤離度を測定します。 | 多クラス |
| FVE Poisson/加重FVE Poisson | 分散の割合の説明 | Poisson Devianceの場合、FVEを提供します。 | 連続値 |
| FVE Tweedie/加重FVE Tweedie | 分散の割合の説明 | Tweedie Devianceの場合、FVEを提供します。 | 連続値 |
| Gamma Deviance/加重Gamma尤離度 | Gamma Deviance | ターゲットがひずみ、Gamma分布している場合に予測された平均値の不正確性を測定します。 | 連続値 |
| ジニ/加重ジニ | ジニ係数 | ランク付けする能力を測定します。 | 連続値、二値分類 |
| 正規化ジニ/加重正規化ジニ | 正規化ジニ係数 | ランク付けする能力を測定します。 | 連続値、二値分類 |
| KS | Kolmogorov-Smirnov | 2つのノンパラメトリック分布の間の最大距離を測定します。 二値分類子の格付けに使用されるKSは、True PositiveとFalse Positive分布の間の乖離度に基づいてモデルを評価します。 KS値はROC曲線に表示されます。 | 二値分類 |
| LogLoss/加重LogLoss | 対数損失 | 予測確率の誤差を測定します。 | 二値分類、多クラス、多ラベル |
| MAE/加重MAE* | 平均絶対誤差 | 予測された中央値の不正確性を測定します。 | 連続値 |
| MAPE/加重MAPE | 平均絶対パーセント誤差 | 平均値のパーセント不正確性を測定します。 | 連続値 |
| MASE | 平均絶対スケールエラー | ベースラインモデルに関する相対パフォーマンスを測定します。 | 連続値(時系列のみ) |
| 最大MCC/加重最大MCC | 最大マシューズ相関係数 | 予測クラスラベルと実測クラスラベルの間のマシューズ相関係数の最大値を測定します。 | 二値分類 |
| Poisson Deviance/加重Poisson Deviance | Poisson Deviance | カウントデータの予測された平均値の不正確性を測定します。 | 連続値 |
| R二乗/加重R二乗 | R二乗 | モデルで説明される結果の合計変動の割合を測定します。 | 連続値 |
| Rate@Top5% | Rate@Top5% | 最上位5%の最高予測の応答率を測定します。 | 二値分類 |
| Rate@Top10% | Rate@Top10% | 最上位10%の最高予測の応答率を測定します。 | 二値分類 |
| Rate@TopTenth% | Rate@TopTenth% | 最上位0.1%の最高予測の応答率を測定します。 | 二値分類 |
| RMSE/加重RMSE | 二乗平均平方根誤差 | ターゲットが正規分布している場合の予測された平均値の不正確性を測定します。 | 連続値、二値分類 |
| RMSLE/加重RMSLE* | 対数二乗平方誤差 | ターゲットがひずみ、正規対数分布している場合の予測された平均値の不正確性を測定します。 | 連続値 |
| シルエットスコア | シルエットスコアは、シルエット係数とも呼ばれます。 | クラスタリングモデルを比較します。 | クラスタリング |
| SMAPE/加重SMAPE | 対称平均絶対パーセント誤差 | 平均値のパーセント誤差(制限付き)を測定します。 | 連続値 |
| 合成AUC | 曲線の下の合成領域 | AUCを計算します。 | 教師なし |
| Theil's U | Henri Theil's U Index of Inequality | ベースラインモデルに関する相対パフォーマンスを測定します。 | 連続値(時系列のみ) |
| Tweedie Deviance/加重Tweedie Deviance | Tweedie Deviance | ターゲットがゼロ過剰でひずんでいる場合の予測された平均値の不正確性を測定します。 | 連続値 |
* これらの指標は平均値に対して最適化されないので、(平均値を表示する)リフトチャートの結果は、それを指標として使用するほとんどのモデルにおいて誤解を招くものになります。
推奨される指標¶
DataRobotは、モデルのスコアリングに使用する最適化指標を推奨しています。推奨される指標は、通常、特定の状況に最良の選択オプションとなります。 指標の変更は高度な機能であり、他の指標(およびその背後にあるアルゴリズム)が十分に理解されている場合にのみ、分析に使用すべきです。
次の表は、指標を推奨する際にDataRobotが従う一般的なガイドラインの概要を示しています。
| プロジェクトタイプ | 推奨される指標 |
|---|---|
| 二値分類 | LogLoss |
| 多クラス分類 | LogLoss |
| 多ラベル分類 | LogLoss |
| 連続値 | DataRobotは、パーセンタイル、平均、分散、歪み、ゼロカウントなど、ターゲット分布のプロパティから情報を得たヒューリスティックを適用することで、RMSE、Tweedie Deviance、Poisson Deviance、Gamma Devianceの最適化指標のいずれかを選択します。 |
EDA 1サンプルのうち*。
DataRobot指標¶
このセクションでは、DataRobot最適化指標について詳細に説明します。
備考
DataRobotの最適化指標とEureqaエラー指標には、いくつかの類似点があります。 しかし、指標式が別の形で表現される場合があります。 たとえば、予測がy^と表される場合とf(x)と表される場合があります。 これは両方とも正しい表示で、ニュアンスとして、y^は過程にかかわらず一般的な予測を示し、f(x)は基となる方程式を表すことのある関数を示します。
正解率/均衡正解率¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| 精度 | 精度 | サブセットに対する正解率を計算します。サンプルに対して予測されたラベルのセットは、y_trueのラベルの対応するセットに完全に一致する必要があります。 | 二値分類、多クラス |
| 均衡正解率 | 均衡正解率 | クラスごとにone-vs-allで計算された正解率の平均を提供します。 | 多クラス |
正解率指標は分類問題に適用され、指定したしきい値に基づいて、すべての予測の総数に対する正しい予測の総数の割合を取得します。 True Positives(TP)およびTrue Negatives(TN)が正しい予測で、False Positives(FP)およびFalse Negatives(FN)が間違った予測です。 以下に式を示します。
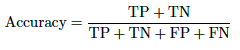
クラスごとのTrue PositivesとTrue Negativesの予測数を調べる正解率とは異なり、均衡正解率は、リコールとも呼ばれる、各クラスのTrue Positives(TP)とFalse Negatives(FN)を調べます。 これは、各クラスのリコール値の合計をクラスの総数で割ったものです。 (この式はTPR式と一致します。)
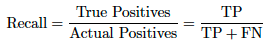
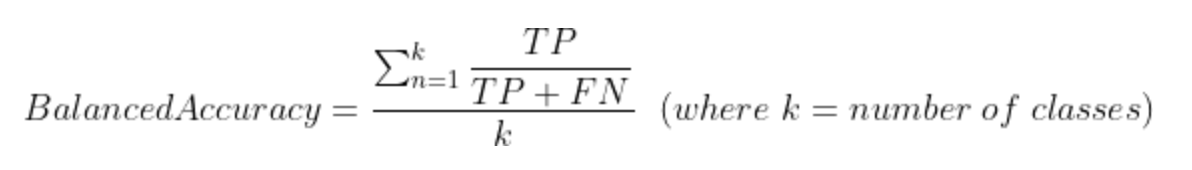
たとえば、以下の3x3行列の例では次のようになります。
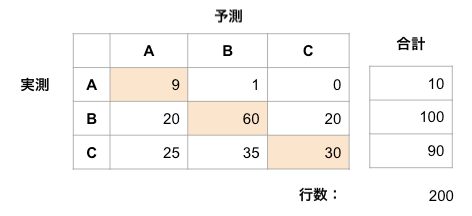
正解率 = (TP_A + TP_B + TP_C) / Total prediction countまたは、上の画像から、(9 + 60 + 30) / 200 = 0.495
均衡正解率 = (Recall_A + Recall_B + Recall_C) / total number of classes
Recall_A = 9 / (9 + 1 + 0) = 0.9
Recall_B = 60 / (20 + 60 + 20) = 0.6
Recall_C = 30 / (25 + 35 + 30) = 0.333
均衡正解率 = (0.9 + 0.6 +0.333) / 3 = 0.611
正解率と均衡正解率は、バイナリ分類と多クラス分類の両方に適用されます。
加重の使用:混同行列のすべてのセルは、そのセルのサンプルの加重の合計になります。 加重が指定されない場合、暗黙の重みは1なので、重みの合計は観測値の数でもあります。
バランスの悪いデータセットでは、正解率はあまり高くありません。 たとえば、Negative95個、Positive5個のサンプルがあった場合、すべてをNegativeと分類すると、正解率スコアは0.95になります。 均衡正解率(bACC)を使用すると、True PositivesおよびTrue Negativesの予測をそれぞれPositiveおよびNegativeのサンプルの数で正規化し、その合計を2で割ることによって、この問題が解決されます。 これは、次の方程式と同等です。

AUC/加重AUC¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| AUC/加重AUC | (ROC)曲線下の領域 | 正例と負例を識別する能力を測定します。多クラスの場合、AUCは各クラスについて一対多で計算された後にクラスの出現頻度に基づいた加重平均を行います。 | 二値分類、多クラス、多ラベル |
ROC曲線のAUCは、分類問題のパフォーマンス指標です。 ROCは確率曲線で、AUCは可分性の程度や指標を表します。 指標範囲は0~1で、モデルでクラスを区別することのできる能力を示します。 AUCが高いほど、モデルでのNegative(0を0として判別)およびPositive(1を1として判別)の予測が高くなります。 ROC曲線は、可能な各しきい値においてY軸の真陽性率 (リコール)とX軸のFalse Positivesレート(特異度)がどれだけ異なるかを示します。
多クラスまたは多ラベルモデルでは、「1対その他」のやり方で、n個のクラスに対してn個のAUC/ROC曲線をプロットできます。 たとえば、X、Y、およびZという名前の3つのクラスがある場合、YとZから区別されたXに1つのROCがあり、XとZから区別されたYに別のROCがあります。さらに、YとXから区別されたZに3番目のROCがあります。 ROC曲線とAUCを多クラスまたは多ラベル分類に適用するには、出力を二値化する必要があります。
多クラスプロジェクトの場合、AUCスコアは、各単一クラスの平均AUCスコア(マクロ平均)で、サポートによって加重されます(各クラスのTrueインスタンスの数)。 加重AUCスコアは、各クラスのサンプル加重平均AUCスコア(マクロ平均)で、各クラスのサンプル加重に従って加重されますsum(sample_weights_for_class)/sum(sample_weights)。
多ラベルプロジェクトの場合、AUCスコアは、各単一クラスの平均AUCスコア(マクロ平均)となります。 加重AUCスコアは、各単一クラスのサンプル加重平均AUCスコア(マクロ平均)です。
PR曲線の下の領域¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| PR曲線の下の領域 | PR(プレシジョン–リコール)曲線の下の領域 | プレシジョン-リコール曲線下の領域の近似。陽性的中率とリコールを1つのスコアにまとめます。 不均衡なターゲットに適しています。 | 二値分類、多ラベル |
プレシジョン-リコール(PR)曲線は、モデルのプレシジョンとさまざまな確率しきい値でのリコールとの間のトレードオフをキャプチャします。 プレシジョンとは、Positiveのラベルが設定されたTrue Positivesの割合です(TP / (TP + FP))。リコールは、モデルによって回復されたPositiveラベル付きケースの割合です(TP/ (TP + FN))。
PR曲線の下の領域は常に正確に計算できるとは限らないため、各しきい値でのプレシジョンの加重平均を使用して、前のしきい値からのリコールの改善によって加重された近似が使用されます。
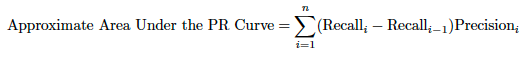
PR曲線の下の領域は、マイノリティークラスが対象の「Positive」クラスである不均衡クラスの問題に非常に適しています(そのようにエンコードされていることが重要です)。プレシジョンとリコールは両方ともPositiveクラス抽出に関する情報のサマリーを提供し、True Negativesからの通知は行われません。
領域の補間とは対照的に、上記のアプローチを使用することの相対的なメリットの詳細については、以下を参照してください。
多ラベルプロジェクトの場合、報告されたPR曲線下面積スコアは、各単一クラスの平均PR曲線下面積スコア(マクロ平均)となります。
尤離度指標¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| Gamma Deviance/加重Gamma尤離度 | Gamma Deviance | ターゲットがひずみ、Gamma分布している場合に予測された平均値の不正確性を測定します。 | 連続値 |
| Poisson Deviance/加重Poisson Deviance | Poisson Deviance | カウントデータの予測された平均値の不正確性を測定します。 | 連続値 |
| Tweedie Deviance/加重Tweedie Deviance | Tweedie Deviance | ターゲットがゼロ過剰でひずんでいる場合の予測された平均値の不正確性を測定します。 | 連続値 |
尤離度はモデルの適合度の尺度であり、モデルがデータにどの程度適合しているかを示します。 技術的には、これは、適合した予測モデルと観測値の完璧な(飽和済み)モデルの比較です。 通常、これは対数尤度関数(最尤推定から決定されたパラメーター)の2倍として定義されます。 したがって、逸脱度は、適合モデルと飽和モデルの間の尤度差として定義されます。 その後、逸脱度は常に0以上になります(0は適合が完璧である場合にのみ出現します)。
逸脱度指標は、Generalized Linear Modelの原則に基づきます。 したがって、尤離度は、ターゲット値と予測値の誤差のある種の測定です。この場合の予測値は、次に示されるリンク関数を介して実行されます。
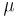
リンク関数としては、線形モデルの予測を0~1の確率に変換するためにlogistic regressionで使用されるロジット関数が挙げられます。つまり、各乖離方程式は、ターゲットデータに適用可能と見なされる分散のタイプで機能することを意図した誤差指標です。
たとえば、ターゲットの通常の分布では、二乗誤差の合計が使用されます。
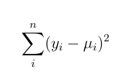
およびPythonの実装:np.sum((y - pred) ** 2)
この場合、逸脱度指数は二乗誤差の合計です。
データが一方に偏っているGamma分布の場合(顧客の店舗滞在時間の分布などで右すそが長い場合など)、尤離度は次のようになります。
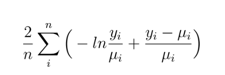
Python2 * np.mean(-np.log(y / pred) + (y - pred) / pred)
対象が予測数または発生数であるPoisson分布の場合、関数は次のようになります。
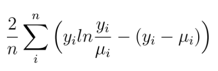
Python2 * np.mean(y * np.log(y / pred) - (y - pred))
Tweedieの場合、関数は少し複雑になります。 Tweedie乖離度は、ターゲットにTweedie分布があると仮定し、モデルがデータにどれだけ適合するかを測定します。 Tweedieは、比較的多くの0があり、残りは連続値であるゼロ過剰の回帰問題で一般的に使用されます。 乖離の値が小さいほどモデルの精度が高くなります。 Tweedie乖離は非常に複雑な指標なので、FVE(説明された尤離度の割合)Tweedieを使用してモデルを説明する方が簡単な場合があります。 この指標はR^2と同等ですが、正規分布ではなくTweedie分布用です。 1のスコアは完全な説明です。
Tweedie Devianceでは、正規、Poisson、Gammaを始めとするさまざまな分布族を区別することを意図しています。 これには、ゼロでPositiveになり、その他の値でNegativeになるPoissonとGammaの混合分布のクラス(ゼロ過剰分布など)が含まれます。 この場合、関数は次のようになります。
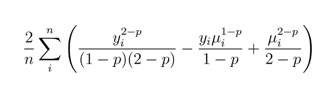
Python2 * np.mean((y ** (2-p)) / ((1-p) * (2-p)) - (y * (pred ** (1-p))) / (1-p) + (pred ** (2-p)) / (2-p))
ここで、パラメーターpは各分布族を区別する指標値です。 たとえば、0は正規分布で、1はPoisson分布、1.5はTweedie,そして2はGamma分布です。
これらの指標スコアの解釈はあまり直感的ではありません。 yおよびpredの値はターゲットの単位(ドルなど)ですが、上述のとおり、ログ関数とスケーリングにより解釈は複雑になります。
これは、加重乗数を使用することにより加重逸脱度関数に変換できます。たとえば、Poissonの場合は次のようになります。
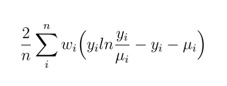
備考
いくつかの計算でのログ関数と予測の分母が原因で、これが機能するのは正の応答だけです。 したがって、予測は厳密に正の(max(pred, 1e-8))になり、実測値は乖離度関数に応じて、負でない(max(y, 0))または厳密に正の(max(y, 1e-8))になります。
FVE尤離度指標¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| FVE Binomial/加重FVE Binomial | 分散の割合の説明 | 二項分布のフィッティングに基づいて尤離度を測定します。 | 二値分類 |
| FVE Gamma/加重FVE Gamma | 分散の割合の説明 | Gamma尤離度のFVEを測定します。 | 連続値 |
| FVE多項/加重FVE多項 | 分散の割合の説明 | 多項分布のフィッティングに基づいて尤離度を測定します。 | 多クラス |
| FVE Poisson/加重FVE Poisson | 分散の割合の説明 | Poisson尤離度のFVEを測定します。 | 連続値 |
| FVE Tweedie/加重FVE Tweedie | 分散の割合の説明 | Tweedie尤離度のFVEを測定します。 | 連続値 |
FVEは 分散説明率(「説明された尤離度の割合」とも呼ばれる)です。 これは、総逸脱度(誤差)のうちでモデルでキャプチャされた部分を示します。これは次のように定義されます。
分散説明率を計算するには、次の3つのモデルが適合します。
- 「分析されたモデル」、またはDataRobot内で実際に構築されたモデル。
- 「最悪な適合」モデル(予測なしで適合され、切片のみに適合されるモデル)。
- すべての観測値を正確に予測する「完璧な適合」モデル(「完全飽和」モデルとも呼ばれます)。
「Null Deviance」は、「最悪な適合」モデルと「完璧な適合」モデルの間で計算された総尤離度です。 「Residual Deviance」は、「分析されたモデル」と「完璧な適合」モデルの間で計算された総尤離度です。 (詳細については尤離度方程式を参照してください。)
「説明のつかない尤離度の割合」は、Residual Deviance(残差尤離度:「完璧な適合」モデルと使用しているモデル間の誤差の尺度)をNull Deviance(Null尤離度:「完璧な適合」モデルと「最悪な適合」モデル間の誤差の尺度)で割ったものとして考えることができます。 説明された尤離度の割合は、1から説明のつかない尤離度の割合を引いたものです。 R二乗スタイルの統計である分散の割合(FVE)を計算することにより、「最悪適合」モデルと比較したモデルのパフォーマンスの改善を測定します。

次のように概念的に示します。
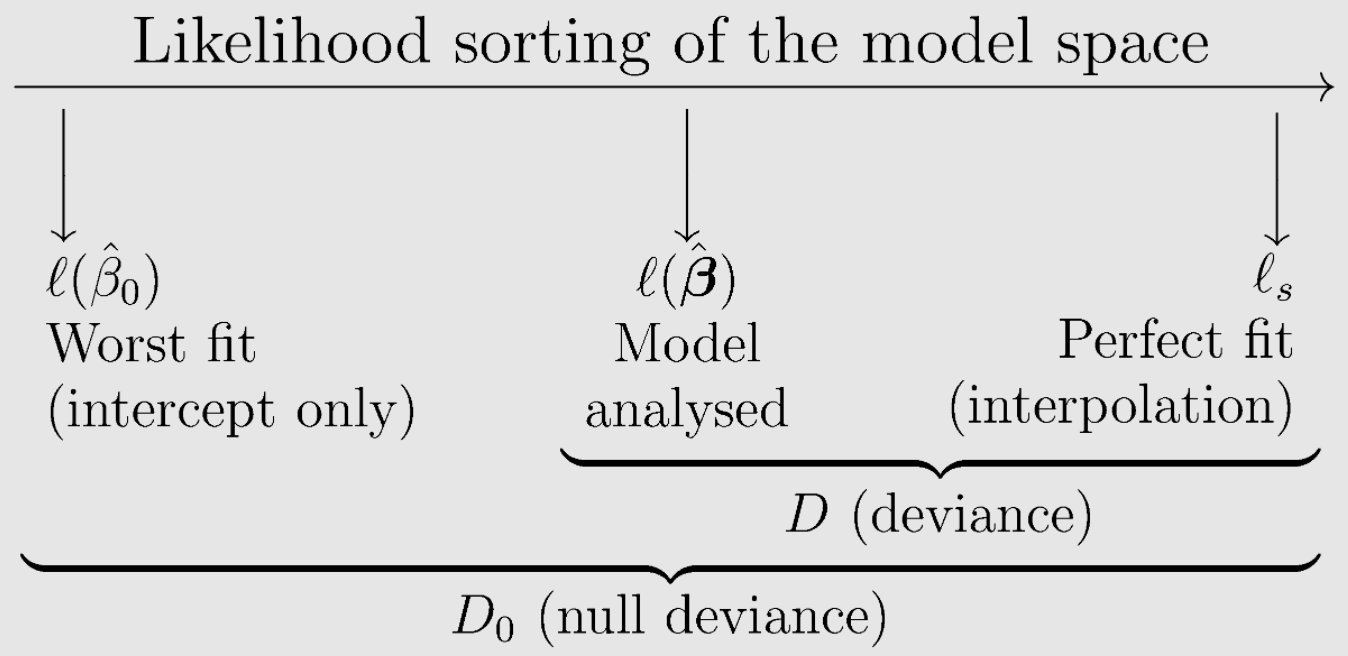
* 図版提供:EduardoGarcía-Portugués、 予測モデリングに関する備考。
したがって、説明された逸脱度の分数は、線形回帰モデルの従来のR二乗に等しくなります。しかし、従来のR二乗とは異なり、指数型回帰モデルに一般化されます。 差分をNull Deviance(Null尤離度)でスケールすることによって、FVEの値は0~1になりますが、常にそうであるとは限りません。 モデルでの応答の予測が悪く、新しい観測値および交差検定済みアウトオブサンプルデータが大きく異なる場合に0以下になることがあります。
多クラスプロジェクトの場合、FVE多項式ではloss = logloss(act, pred)およびloss_avg = logloss(act, act_avg)が計算されます。
act_avgはone-hot encodedの「実測」データです。- 各クラス(列)は
N個のデータポイントで平均化されます。
基本的に、act_avgは、各クラスに属するデータの割合(%)を含むリストです。 次に、1 - loss / loss_avg経由でFVEが計算されます。
ジニ係数¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| ジニ/加重ジニ | ジニ係数 | ランク付けする能力を測定します。 | 連続値、二値分類 |
| 正規化ジニ/加重正規化ジニ | 正規化ジニ係数 | ランク付けする能力を測定します。 | 連続値、二値分類 |
機械学習では、ジニ係数またはジニ指数は、予測を正確にランク付けするモデルの能力を測定します。 ジニは実質的にAUCと同じですが、-1~1のスケールです(0はランダム分類子のスコアです)。 正規化ジニが1の場合、モデルは入力を完璧ににランク付けします。 ジニは、予測値自体ではなく、予測のランク付けを重視する場合に役立ちます。
ジニは0~1の正規化された値の割合として定義されます。(分子は後述するローレンツ曲線と45度の均等分布線の間の面積です。)

したがって、ジニ係数は、青い面積を下側の三角形の面積で除したものとして定義されます。
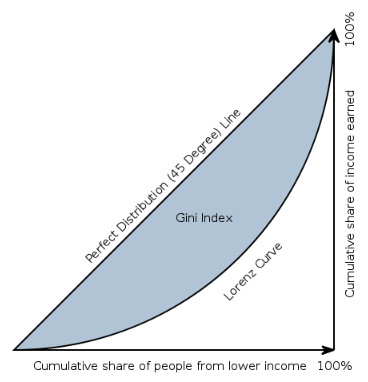
ジニ係数は、完全均等の線(定義により0.5)の下の面積からローレンツ曲線の下の面積を引いたものを完全均等の線の下の面積で割ったものに等しくなります。 つまり、ローレンツ曲線と完全均等の線の間の面積の2倍です。 したがって、45度の線は完全均等を表します。 ジニ係数は、均等の線とローレンツ曲線の間の面積(A)と均等の線の下のすべての面積(A + B)の割合と考えることができます。 したがって、次のことが言えます。
Gini = A / (A + B)
ジニ係数は2Aと1 − 2Bにも等しい。これはA + B = 0.5という事実に基づきます(軸のスケールは0から1です)。
ジニ係数は、受信者動作特性(ROC)曲線とその対角線の間の面積の2倍としても定義できます。この場合、パフォーマンスのAUC(ROC曲線下の面積)測定はAUC = (G + 1)/2によって示されるか、2 * AUC-1として要因に含められます。

ジニ係数の目的はAUCを正規化することなので、ランダムな分類子のスコアは0で、完璧な分類子のスコアは1です。最後に、ジニ係数スコアの範囲は[-1, 1]ですが、実際には0が下限です。 完全な45度線とローレンツ曲線を統合して同じジニ値を得ることもできますが、先に説明した方法の方が簡単です。
経済学の分野では、ジニ係数は、国民の所得分布を表す統計的ばらつきの基準で、最も広く使用されている不平等の基準です。 0のジニ係数は完全な平等を表し、すべての値は同じになります(全員の所得額が同じである場合など)。 このコンテキストでは、1のジニ係数(100%)はすべての値の中での最大の不平等を表します(大勢の中ですべての所得または消費が1人にだけ集中し、その他全員の所得や消費がゼロの場合、ジニ係数は限りなく1に近くなります)。 一部の人の全体に対する貢献がNegativeの場合(所得がマイナスの場合など)、1よりも大きい値が発生することがあります。 この経済学の例を使用すると、ローレンツ曲線は、人口パーセンタイルを所得ごとに水平軸にプロットし、累積所得を直線軸にプロットすることによって所得分布を示します。
正規化ジニ係数は、理論的最大値を使用してスコアを調整するので、最大スコアは1になります。スコアは正規化されるので、値をランク付けできるようなエンティティのジニ係数値を比較することが可能です。 たとえば、国ごとの経済的不平等は一般的にジニ係数に関連付けられ、国のランク付けを行うために使用されています。
| ランク | 国 | 家計所得の分布 — ジニ係数 | 情報の日付 |
|---|---|---|---|
| 1 | レソト | 63.2 | 1995 |
| 2 | 南アフリカ | 62.5 | 2013年推測。 |
| 3 | ミクロネシア連邦 | 61.1 | 2013年推測。 |
| 4 | ハイチ | 60.8 | 2012 |
| 5 | ボツワナ | 60.5 | 2009 |
機械学習のコンテキストでのジニ係数指標の使用例としては、個々のサンプルではなく、実測値と予測値を使用してジニ係数を計算することが考えられます。 上記の例では国内人口の個々の所得のサンプルからジニ係数を生成した場合、ローレンツ曲線は所得の累積合計ごとの人口割合の関数になります。 機械学習のコンテキストでは、実測値と予測値からジニ係数を生成できます。 実測地と予測値をペアにして、予測値でソートするアプローチが考えられます。 この場合、ローレンツ曲線は、実測値の累積合計(クラス1値の1のある時点までの合計)ごとの予測値の関数です。 次に、上記の方程式の1つを使用してジニを計算します。
加重ジニ指標は、実測値と予測値の配列に重みを乗じたものを使用し、予測値でソートします。 この指標は(2*AUC - 1)として計算されます。AUCの計算はactual * weightの累積和と重みの累積和に基づいています。 加重Gini Normは、予測値が実測値と等しい場合に、加重ジニを加重ジニ値で割ったものです。
ジニ指標の使用例については、Porto Seguro's Safe Driver Kaggle competitionとそれに対応する説明をご覧ください。
Kolmogorov–Smirnov(KS)¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| KS | Kolmogorov-Smirnov | 2つのノンパラメトリック分布の間の最大距離を測定します。 二値分類子の格付けに使用されるKSは、True PositiveとFalse Positive分布の間の乖離度に基づいてモデルを評価します。 KS値はROC曲線に表示されます。 | 二値分類 |
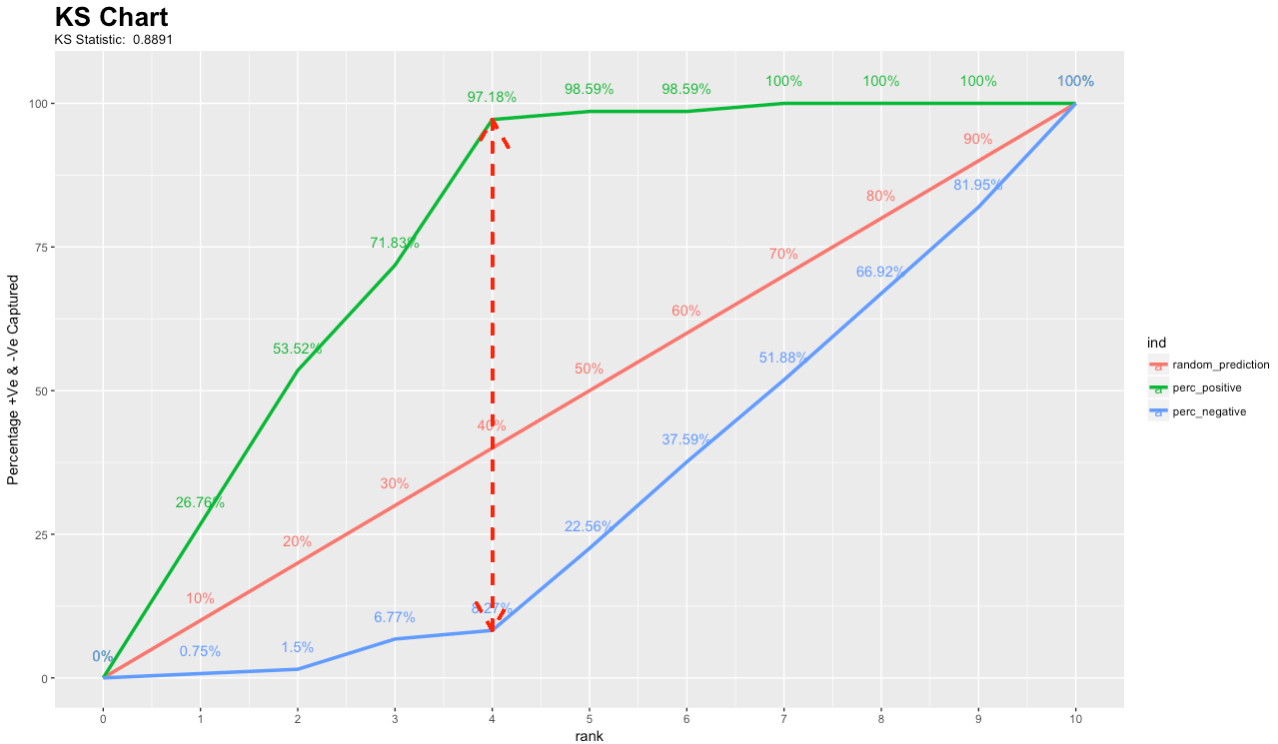
KS(Kolmogorov-Smirnov)チャートは、分類モデルのパフォーマンスを測定します。 具体的に言うと、KSは、Positive分布とNegative分布の分離度の指標です。 スコアによってグループが2つに分割され、1つのグループにすべてのPositiveが含まれ、もう一方のグループにすべてのNegativeが含まれる場合、KSは1になります。 一方、モデルでPositiveとNegativeを区別できない場合、人口からランダムにケースを選択した場合と同じに結果になります。 その場合、KSは0になります。ほとんどの分類モデルでは、KSは0~1の値です。値が高いほど、モデルにおけるPositiveケースとNegativeケースの分離のパフォーマンスが優れています。
二値分類に関するこの論文では、KSは、2つのデータクラス(この目的では2つのサンプルを意味するものとしてKS2と呼ばれます)に関してスコアによって生成される累積分布関数(CDF)間の距離を測定する分類子の判別能力を評価する相違指標として使用されています。 両方の目的における通常の指標は、スコア範囲に対して不変のCDF(Max_KS)とそれを分類子比較に適応させるスケールの間の(最大垂直差(MVD)です。 MVDは、X軸上の1点における2つの曲線の間の垂直距離です。 Max_KSは、この距離が最大となる単一の点です。
LogLoss/加重LogLoss¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| LogLoss/ 加重LogLoss | 対数損失 | 予測確率の誤差を測定します。 | 二値分類、多クラス、多ラベル |
クロスエントロピーLoss(Log Loss)は、出力が0~1の間の確率値である分類モデルのパフォーマンスを測定します。LogLossは、予測された確率が実測値から乖離するにしたがって増加します。 この例では、実測の観測値ラベルが1のときに0.12の確率の予測である場合、または実測観測値ラベルが0のときに0.91が予測された場合、結果は「不良」で、誤分類の確率は真のラベル値に近い高いLoss値になります。 完璧なモデルのLogLossは0になります。
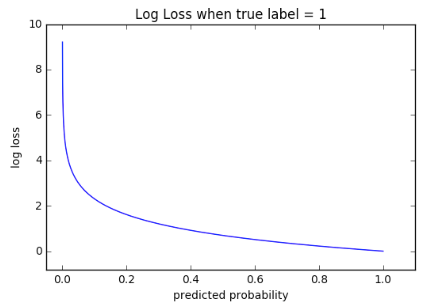
上のグラフは、真の観測値(true = 1)の場合のLoss値の範囲を示します。 予測された確率が1に近くなると、LogLossはゆっくりと減少します。 しかし、予測された確率が増加すると、LogLossは急激に増加します。 LogLossでは両方のタイプの誤差にペナルティが科せられますが、信頼度が高く間違っている予測に対して特にペナルティが科せられます。
クロスエントロピーとLogLossはコンテキストに応じて若干異なりますが、機械学習では、0~1の誤差率を計算する場合、解決する対象は同じです。
二値分類では、方程式は-(ylog(p) + (1 - y)log(1 - p))または
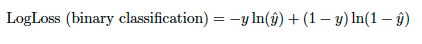
ここで、pはyの予測値です。
多クラスと多ラベルについても同様に、観測値の各クラス予測にLogLoss値の合計を取ります。

これは、クラスに加重を加えることによって加重Loss関数に変換できます。
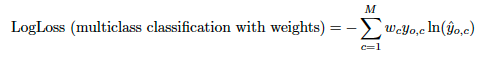
多ラベルで報告されたLogLossスコアは、1/number_of_unique_classesによってスケーリングされることに注意してください。
MAE/加重MAE¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| MAE/加重MAE | 平均絶対誤差 | 予測された中央値の不正確性を測定します。 | 連続値 |
DataRobotでは、中央値を使用して絶対偏差を測定する「MAE」指標が実装されています。これは、より精度の高い絶対偏差(絶対誤差)の計算です。 これは、絶対誤差に関するLoss関数の最適化における派生した最良値は系列の中央値であるという事実に基づいています。
予測である最適値(x1,x2,…,xn)に要約する数値の系列があるとします。 これを単一の数値(s)に要約する場合、どのようにsを選択すれば予測(x1,x2,...,xn)を効果的に要約できるでしょうか。 個々のxiのxiとsの間の誤差偏差をsの提案値の品質の単一のサマリーに集計します。 この集計を実行するには、個々のxiの偏差を合計して結果Eを求めます。
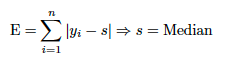
最少誤差になるsに解決すると、E Loss関数は平均値ではなく中央値に最適化されます。 同様に、平方誤差Loss関数の最良値は平均値に最適化されます。 したがって、これは平均平方誤差になります。
MAEは「平均絶対誤差」の略ですが、MAEは中央値を正しく予測するためにモデルを最適化します。 これは、RMSEが「二乗平均平方根誤差」であることと似ていますが、平均を正確に予測するために最適化しています(平均を二乗しているわけではありません)。
DataRobotでは、MAEに最適化する場合に興味深い不一致が見られます。 ほとんどのインサイトでは平均値がレポートされます。 したがって、モデルでは、分布の各ポイントにおいて過小予測または過大予測が行われるので、すべてのリフトチャートは「オフ」に見えます。 リフトチャートでは平均値が計算されますが、MAEは中央値に最適化されます。
これは、観測値に加重を加えることによって加重Loss関数に変換できます。

残念ながら統計学の文献では、平均値周辺の平均絶対偏差(MAD)と平均絶対誤差(DataRobotでは「MAE」と表記)は、頭文字をとって両方ともMADと表記されることがあり、表記が統一されていません。通常これらの値は大きく異なる可能性があるため、混乱を招く恐れがあります。
MAPE/加重MAPE¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| MAPE/加重MAPE | 平均絶対パーセント誤差 | 平均値のパーセント不正確性を測定します。 | 連続値 |
MAEには、誤差の相対サイズが常に明らかでないという問題があり。 大きい誤差と小さい誤差を見分けることが困難なことがあります。 この問題に対処するために、平均絶対誤差をパーセントで求めます。 平均絶対パーセント誤差(MAPE)を使用すると、さまざまなスケールでさまざまな系列の予測を比較できます。 たとえば、2つの店舗の販売量が異なる場合でも、1つの店舗の販売予測の精度を同じような別の店舗の販売予測と比較することができます。
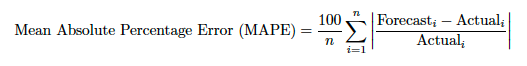
MASE¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| MASE | 平均絶対スケールエラー | ベースラインモデルに関する相対パフォーマンスを測定します。 | 連続値(時系列のみ) |
MASEは予測の精度の指標で、ナイーブベースラインモデルに対するモデルの比較(ベールラインモデルに対するMAEのシンプルな比率)です。 MASEには、相対的な精度ゲインの観点から容易に解釈および説明できるという利点があるので、モデルを比較する際に推奨されます。 DataRobot時系列プロジェクトでは、ベースラインモデルは、最長の周期性に一致する最新の値を使用するモデルです。 プロジェクトには異なる周期性のある複数のナイーブ予測がある場合がありますが、DataRobotは最長のナイーブ予測を使用してMASEスコアを計算します。
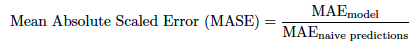
または、さらに詳しく示します。
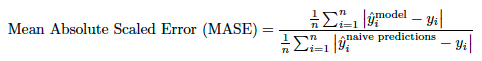
ここで、分子は対象のモデルで、分母はナイーブベースラインモデルです。
最大MCC/加重最大MCC¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| 最大MCC/加重最大MCC | 最大マシューズ相関係数 | 予測クラスラベルと実測クラスラベルの間のマシューズ相関係数の最大値を測定します。 | 二値分類 |
マシューズ相関係数は二値分類の均衡指標で、混同行列の4つのエントリすべてが考慮に入れられます。 これは次のように計算されます。
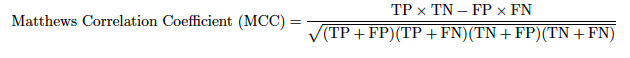
各パラメーターについて説明します。
| 出力 | 説明 |
|---|---|
| True Positive (TP) | モデルは陽性のインスタンスを正しく陽性として分類する。 |
| False Positive (FP) | モデルは陰性のインスタンスを誤って陽性として分類する。 |
| True Negative (TN) | モデルは陰性のインスタンスを正しく陰性として分類する。 |
| False Negative (FN) | モデルは陽性のインスタンスを誤って陰性として分類する。 |
値の範囲は[-1, 1]で、1が完璧な予測を表します。
混同行列のエントリは予測しきい値に依存するので、DataRobotでは、可能な予測しきい値よりもMCCの最大値が優先されます。
R二乗(R2)/加重R二乗¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| R二乗/加重R二乗 | R二乗 | モデルで説明される結果の合計変動の割合を測定します。 | 連続値 |
R二乗は予実の精度の統計的指標(データが予実回帰線にどれだけ近いか)です。 R二乗は、決定係数(複数連続値の複数決定の係数)とも呼ばれます。 分散の説明が示すように、R二乗は、線形モデルで説明される応答特徴量偏差のパーセンテージです。 R二乗は一般的に0~100%です。 0%は、平均値の周辺の応答データのいずれの変動もモデルで説明されないことを示します。 100%は、平均値の周辺の応答データのすべての変動がモデルで説明されることを示します。
結果が負のR値になることがあります。その場合、モデルの予測は平均値よりも悪いことを示します。 この状況は、問題のあるトレーニングデータなどが原因で発生することがあります。 時間認識プロジェクトの場合、時間の経過に伴う平均値の変化が原因で、R二乗の結果が負の値になる可能性が高くなります。高い平均周期でモデルをトレーニングし、低い平均周期でテストした場合、結果が大きな負のR二乗値になることがあります。 (ランダムサンプリングでパーティション分割を行った場合、トレーニングおよびテストセットのターゲット平均値は大体同じなので、負のR二乗値が発生する可能性は低くなります。) 一般的に、負のR二乗値のモデルは回避することをお勧めします。
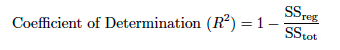
ここで、SS_resは残差平方和(説明可能な変動)です。
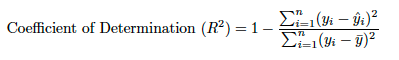
SS_totは全平方和です(データの分散に比例します)。
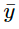
トレーニングデータから計算されたyのサンプル平均です。
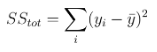
加重R二乗の場合、SS_resは次のようになります。
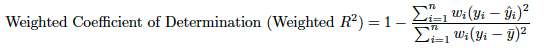
SS_totは次のようになります。
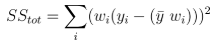
R二乗の主な制限:
-
R二乗では、係数推定および予測がバイアスされているかどうかが判断できないので、残差プロットを評価する必要があります。
-
R二乗は人為的に大きくすることが可能です。 独立した特徴量をモデルに追加していくだけで、R二乗の値を大きくすることができます。 つまり、独立した特徴量を追加してもR二乗の値が小さくなることはありません。 このような特徴量は顕著でなく、モデルにとって全く意味のない場合があります。
-
R二乗は、回帰モデルが適切であるかどうかを示しません。 良好なモデルでもR二乗の値が小さい場合があり、データに適合しないモデルでR二乗値が大きい場合もあります。 その結果、R二乗値を解釈する際には注意が必要です。
R二乗値が小さい場合でも、必ずしもモデルの適合性が悪いわけではありません。 分野によっては、全体的にR二乗の値が小さくなることがあります。 たとえば、心理学など、人の行動を予測しようとする分野では、R二乗の値は一般的に50%以下です。 この理由は、人の行動は物理的プロセスなどに比べて予測が困難であるからです。
同様に、R二乗の値が大きい場合でもモデルの適合性が高くない場合があります。 R二乗値が大きいからといって、必ずしもモデルの適合性が高いとは限りません。 たとえば、適合線プロットが良好な適合性を示し、大きなR二乗値を表すように見える場合でも、残差プロットで系統的に過大予測または過小予測が確認され、高いバイアスが見られることがあります。
DataRobotでは、アウトオブサンプルデータが計算され、特徴量を追加すると値が増加する、またはR2を非線形技法に適用できないなどの従来の批評が緩和されます。 アウトオブサンプルデータはRMSEのスケールされたバージョンとして扱われ、平均モデル(R2 = 0)との比較を行い、そのパフォーマンスが優れているか(R2 > 0)劣っているか(R2 < 0)を判断できます。
Rate@Top10%, Rate@Top5%, Rate@TopTenth%¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| Rate@Top5% | Rate@Top5% | 最上位5%の最高予測の応答率を測定します。 | 二値分類 |
| Rate@Top10% | Rate@Top10% | 最上位10%の最高予測の応答率を測定します。 | 二値分類 |
| Rate@TopTenth% | Rate@TopTenth% | 最上位0.1%の最高予測の応答率を測定します。 | 二値分類 |
Rate@Top5%、Rate@Top10%、Rate@TopTenth%は、これらの信頼領域(最高予測値の上位5%、上位10%、上位0.1%)のPositiveラベルの割合を計算します。 たとえば、次のような昇順に並べられた100の予測を考えてみます。[0.05, 0.08, 0.11, 0.12, 0.14 … 0.87, 0.89, 0.91, 0.93, 0.94 ]。 しきい値が0.87以下である場合、0.87から0.94までの上位5の予測がPositiveクラス(1)に割り当てられます。 上位5位の予測が[1, 1, 0, 1, 1]である場合、Rate@Top5%精度指標は80%になります。
RMSE、加重RMSEおよびRMSLE、加重RMSLE¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| RMSE/加重RMSE | 二乗平均平方根誤差 | ターゲットが正規分布している場合の予測された平均値の不正確性を測定します。 | 連続値、二値分類 |
| RMSLE/加重RMSLE* | 対数二乗平方誤差 | ターゲットがひずみ、正規対数分布している場合の予測された平均値の不正確性を測定します。 | 連続値 |
二乗平均平方根誤差(RMSE)は、実測値と予測値の違いを取るという点でMADに似た精度の指標です。 しかし、RMSEでは、絶対値を適用するのではなく、差分が二乗され、平方根が求められます。

したがって、RMSEは常に非Negativeで、0の値はデータに対する完全な適合性を示します。 一般的に、RMSEが低いモデルは、RMSE高いモデルよりもモデルの適合性は高くなります。 しかし、タイプの異なるデータの比較の場合、指標は使用された数値のスケールに依存するので、これは該当しません。
RMSEは二乗誤差の平均の平方根です。 RMSEの各誤差の影響は、二乗誤差のサイズに比例します。 したがって、誤差が大きい場合、RMSEに対して偏った大きい影響が生じます。 その結果として、RMSEは外れ値に対する感度が高くなります。
対数二乗平方誤差(RMSLE)は、ゼロの自然対数を取ることを避けるために、自然対数を取る前に実測値と予測値の両方に1を追加します。 したがって、実測値または予測値に0の値の要素がある場合に関数を使用できます。 ここで問題となるのは、実測値と予測値の間のパーセント差分だけです。 たとえば、P = 1000でA = 500の場合の誤差は、P = 100000でA = 50000の場合とほぼ同じになります。
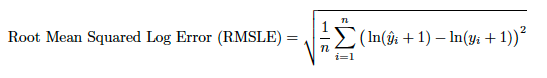
これは、加重乗数を使用することにより加重関数に変換できます。
備考
RMSLEの場合、多くのモデルブループリントログではターゲットが変換され、RMSEに最適化されます。 これは、RMSLEへの最適化と同等です。 その場合、モデルの構築情報には、「log transformed response」と表示されます。
シルエットスコア¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| シルエットスコア | シルエットスコアは、シルエット係数とも呼ばれます。 | クラスタリングモデルを比較します。 | クラスタリング |
シルエット係数とも呼ばれるシルエットスコアは、クラスタリングモデルの比較に使用される指標です。 平均クラスター内距離(クラスター内の各ポイントの平均距離)と平均最近傍クラスター距離(クラスター間の平均距離)を使って計算します。 つまり、クラスター間の距離を考慮しながらも、各クラスター内の分布も考慮するということです。 クラスターが凝縮された場合、インスタンス(ポイント)には高い類似性があります。 シルエットスコアの範囲は-1~+1です。+1に近いほど、クラスターが離れているということです。
大規模なデータセットのシルエットスコアの計算には非常に時間がかかります。クラスタリングモデルのトレーニングは数分ですが、指標の計算には数時間かかる場合があります。 これに対処するために、DataRobotは層化抽出法を実行してデータセットを50000行に制限し、モデルが妥当な時間枠で大規模なデータセットに対してトレーニングおよび評価され、実際のシルエットスコアの適切な推定値も提供されるようにします。
時系列におけるシルエットスコアは、異なる系列間のデータポイントの類似性を比較することで算出される、異なる系列間のシルエット係数の尺度です。 時系列以外のユースケースと同様に、距離は系列間の距離を使用して計算されます。ただし類似性を考慮する場合、シルエット係数の計算では時間内の位置が考慮されないという重要な違いがあります。
シルエットスコアは一般的に有用ですが、時系列では注意して検討してください。 シルエットスコアは、系列に含まれるポイントの類似度が高い系列を識別できますが、周期性や傾向、または時間の経過に伴う類似性は考慮されていません。
この影響を理解するために、次の2つのシナリオを検証してみましょう。
シルエット時系列シナリオ1¶
次の2つの系列を検討します。
-
最初の系列では、最初の10ポイントに大きなスパイクがあり、その後に90の小さな値~ゼロに近い値が続きます。
-
2つ目の系列には、70の小さな値~ゼロに近い値があり、その後に中程度のスパイクとさらにいくつかのゼロに近い値が続きます。
このシナリオでは、シルエット係数はこの2つの系列間で大きくなる可能性があります。 時間が考慮されていないことを考えると、この値は高度な数学的類似性を示しています。
シルエット時系列シナリオ2¶
次の3つの系列を検討します。
-
最初の系列は、大きさ1のSine(正弦)波です。
-
2つ目の系列は、大きさ1のCosine(余弦)波です。
-
3つ目の系列は、大きさ0.5のCosine(余弦)波です。
潜在的なクラスタリング手法:
-
最初の手法では、Sine(正弦)波とCosine(余弦)波(共に大きさ1)をクラスターに追加し、小さい方のCosine(余弦)波を2つ目のクラスターに追加します。
-
2つ目の手法では、2つのCosine(余弦)波を1つのクラスターに追加し、Sine(正弦)波を別のクラスターに追加します。
最初の手法は、2つ目の手法よりもシルエットスコアが高くなる可能性があります。 これは、シルエットスコアがデータの周期性を考慮していないことと、Cosine(余弦)波のピークが相互に意味を持っている可能性が高いためです。
セグメント化されたモデリングを実行することが目的である場合は、シルエットスコアを考慮に入れますが、次の点に注意してください。
- シルエットスコアが高いほど、セグメント化されたモデリングのパフォーマンスが優れているとは限りません。
- 周期性、ボラティリティ、その他の時間依存の特徴に基づいてグループ化された系列は、時間に依存しない値の大きさのみを考慮した場合、類似性が高い系列よりも低いシルエットスコアを返す可能性があります。
SMAPE/加重SMAPE¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| SMAPE/加重SMAPE | 対称平均絶対パーセント誤差 | 平均値のパーセント誤差(制限付き)を測定します。 | 連続値 |
平均絶対パーセント誤差(MAPE)を使用すると、さまざまなスケールでさまざまな系列の予測を比較できます。 しかし、ゼロ値がある場合MAPEは使用できず、MAPEにはパーセンテージエラーの上限がありません。 そのような場合、対称平均絶対パーセント誤差(SMAPE)を使用することをお勧めします。 SMAPEには上限と下限があり、その結果は0%から200%の間の値になるので、統計的な値の比較が容易になります。 これは、ゼロの値が存在するデータで使用する場合も適切な関数です。 したがって、Actual = Forecast = 0の行では、DataRobotではすべての行を合計する前に0/0 = NaNがゼロで置き換えられます。

Theil's U¶
| 表示 | 完全な名前 | 説明 | プロジェクトタイプ |
|---|---|---|---|
| Theil's U | Henri Theil's U Index of Inequality | ベースラインモデルに関する相対パフォーマンスを測定します。 | 連続値(時系列のみ) |
Theil’s U(MASEに類似)は、ナイーブモデル(予測に対して最長の周期性に一致する最新の値を使用するモデル)の予測に相対的に、予測の精度を評価する指標です。
MASEには、相対的な精度ゲインの観点から容易に解釈および説明できるという利点があるので、モデルを比較する際に推奨されます。 DataRobot時系列プロジェクトでは、ベースラインモデルは、最長の周期性に一致する最新の値を使用するモデルです。 プロジェクトには異なる周期性のある複数のナイーブ予測がある場合がありますが、DataRobotは最長のネイティブ予測を使用してTheil’s Uスコアを計算します。
ナイーブモデルに対する予測モデルの比較は、この2つのモデルの比率の関数です。 1よりも大きい値はナイーブモデルよりも劣ったモデルを示し、1よりも小さい値はナイーブモデルよりも優れたモデルを示します。
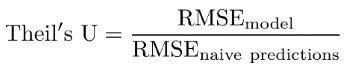
または、さらに詳しく示します。
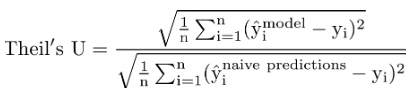
ここで、分子は対象のモデルで、分母はナイーブベースラインモデルです。