予測の作成¶
予測 > 予測を作成タブを使用して、バッチ予測を作成してデプロイ済みモデルによってデータセットを効率的にスコアリングします。
備考
To make predictions with a model before deployment, select the model from the Models list in an experiment and then click Model actions > Make predictions.
バッチ予測とは、大規模なデータセットで予測を作成する方法で、入力データを渡すと各行の予測結果が得られます。 DataRobotは、これらの予測を出力ファイルに書き出します。 以下を行うこともできます。
-
予測データのソースと宛先を指定し、予測が実行される時期を決定することで、バッチ予測ジョブをスケジュールします。
-
バッチ予測APIを使って予測します。
Select a prediction dataset¶
デプロイされたモデルでバッチ予測を行うには、デプロイの予測 > 予測を作成タブに移動し、予測ソースをアップロードします。
-
Drag a file into the Prediction dataset box.
-
ファイルを選択をクリックし、以下のいずれかを選択します。
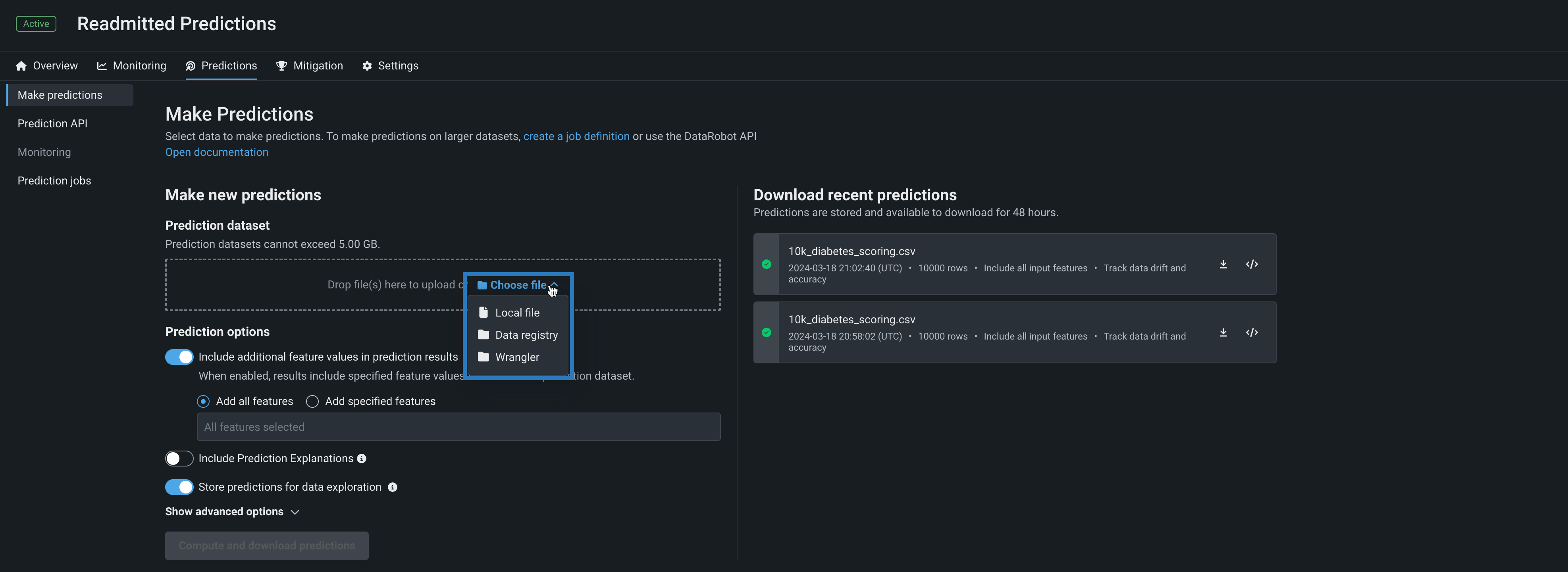
アップロード方法 説明 ローカルファイルをアップロード Select a file from your local file system to upload that dataset for predictions. データレジストリ Select a file previously uploaded to the data registry. ラングラー (Preview) If you have enabled the wrangler batch predictions preview feature, select a file wrangled in Workbench. In your local filesystem, select a dataset file, and then click Open.
予測データセットをアップロードすると、完全にアップロードされた後にAIカタログに自動的に保存されます。 アップロードが完了する前にページから移動しないようにしてください。そうしないと、データセットがカタログに保存されません。 アップロードした後まだデータセットが処理中の場合、使用可能になる前に、データセットに対してDataRobotが EDAを実行中であることを意味します。
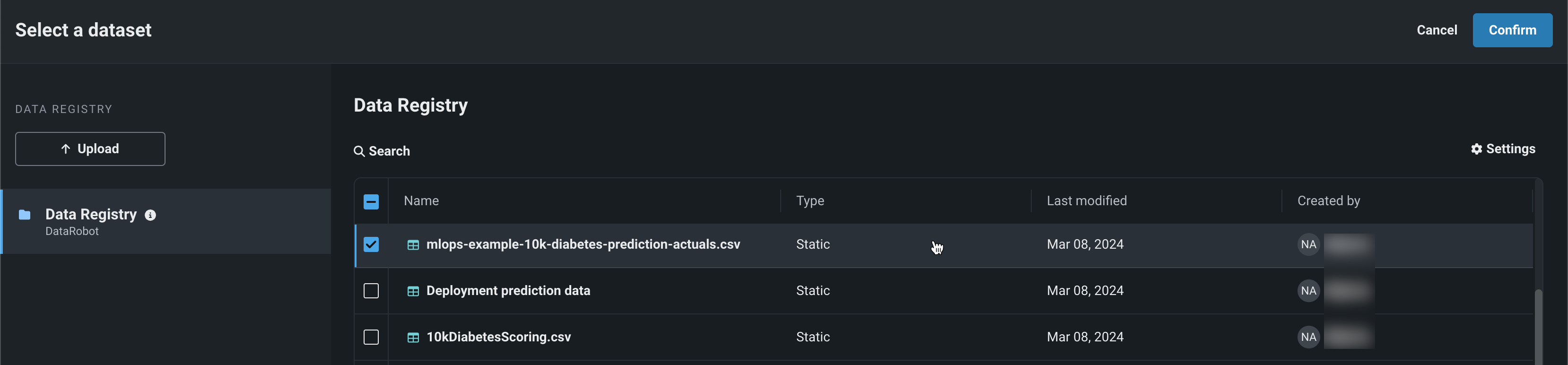
In the Select a dataset panel, click a dataset, and then click Confirm.
本機能の提供について
バッチ予測ジョブのラングラーレシピはデフォルトではオフになっており、Snowflakeのデータ接続からラングリングされたデータのみをサポートします。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:バッチ予測ジョブでラングラーレシピを有効にする、ワークベンチでのレシピ管理を有効にする
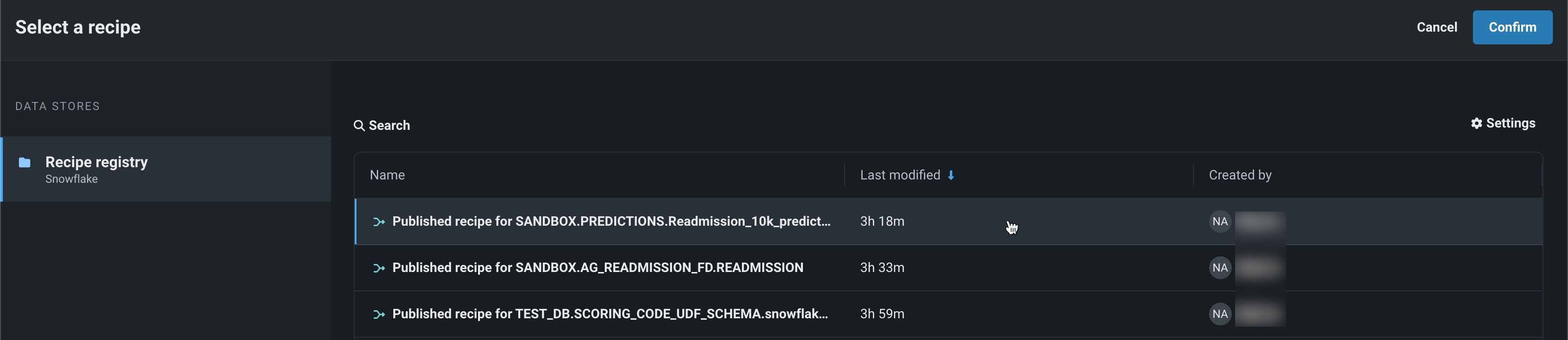
In the Select a recipe panel, click a dataset wrangled from a Snowflake data connection, and then click Confirm.
時系列データ要件
時系列モデルで予測を作成するには、特定の形式のデータセットが必要です。 形式は時系列プロジェクトの設定に基づきます。 予測データセットに正しい履歴行、予測行、および事前に既知の特徴量が含まれていることを確認します。 さらに、DataRobotが時系列データを確実に処理できるようにするには、次の要件を満たすようにデータセットを設定してください。
- 予測行をタイムスタンプでソートします。最も古い行が最初に表示されます。
- 複数系列では、予測行を系列IDでソートし、さらにタイムスタンプでソートして、古い順に表示します。
DataRobotがサポートする系列の数には制限はありません。 制限に記載されているように、唯一の制限はジョブのタイムアウトです。 データセットの例については、スコアリングデータセットの要件をご覧ください。
デプロイでの予測の作成¶
このセクションでは、予測を作成タブを使用して、標準的なデプロイと時系列デプロイでバッチ予測を行う方法を説明します。
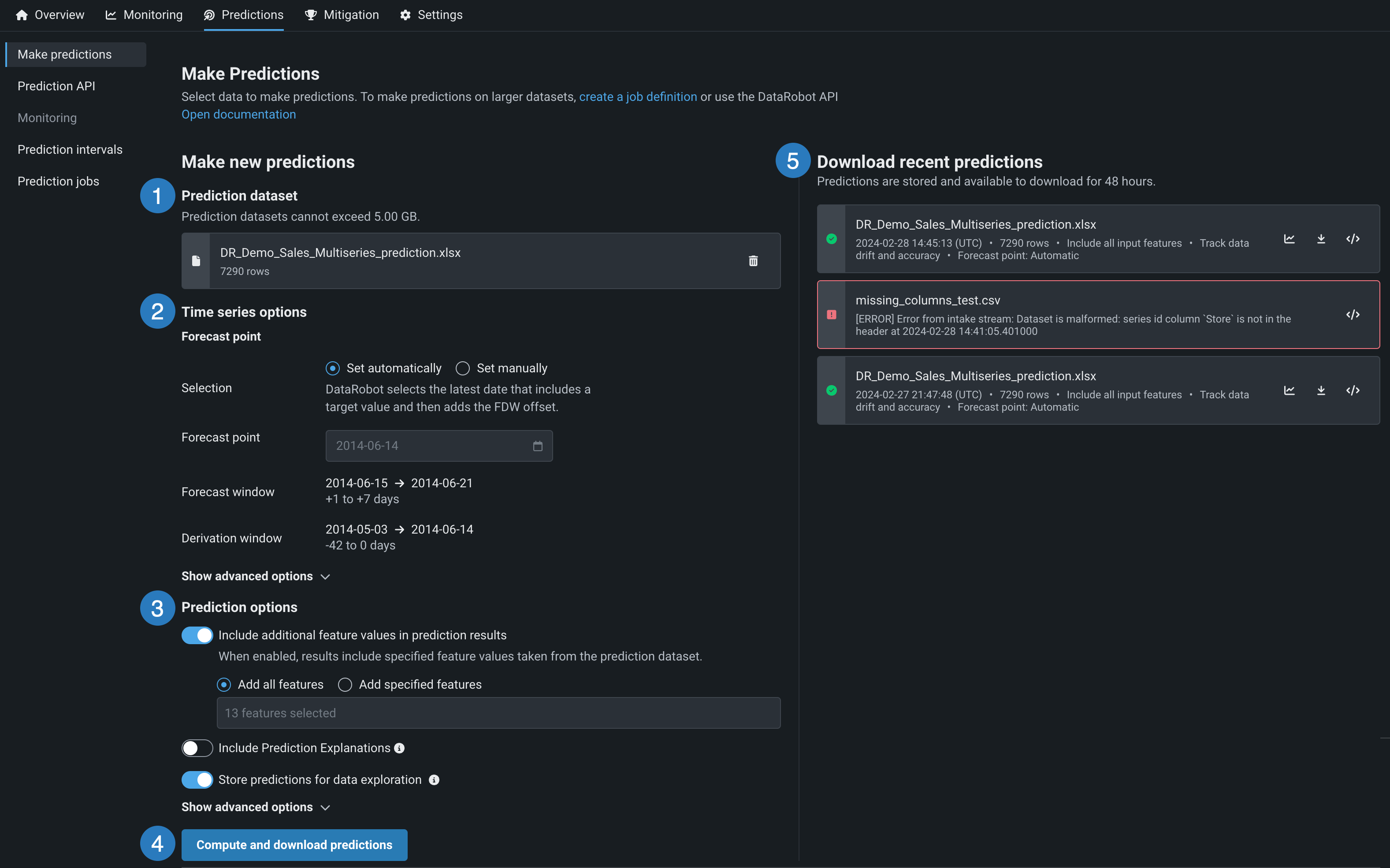
| フィールド名 | 説明 | |
|---|---|---|
| 1 | 予測データセット | ローカルファイルをアップロードするか、データレジストリからデータセットをインポートして、予測データセットを選択します。 |
| 2 | 時系列オプション | 時系列予測の方法を指定および設定します。 |
| 3 | 予測オプション | 予測オプションを設定します。 |
| 4 | 予測を計算およびダウンロード | データをスコアリングし、予測をダウンロードします。 |
| 5 | 最近の予測をダウンロード | 最近のバッチ予測を表示し、結果をダウンロードします。 予測のダウンロードは48時間有効です。 |
時系列オプションの設定¶
時系列データ要件
時系列モデルで予測を作成するには、特定の形式のデータセットが必要です。 形式は時系列プロジェクトの設定に基づきます。 予測データセットに正しい履歴行、予測行、および事前に既知の特徴量が含まれていることを確認します。 さらに、DataRobotが時系列データを確実に処理できるようにするには、次の要件を満たすようにデータセットを設定してください。
- 予測行をタイムスタンプでソートします。最も古い行が最初に表示されます。
- 複数系列では、予測行を系列IDでソートし、さらにタイムスタンプでソートして、古い順に表示します。
DataRobotがサポートする系列の数には制限はありません。 制限に記載されているように、唯一の制限はジョブのタイムアウトです。 データセットの例については、スコアリングデータセットの要件をご覧ください。
時系列オプションを設定するには、時系列予測法で予測ポイント設定を定義します。
-
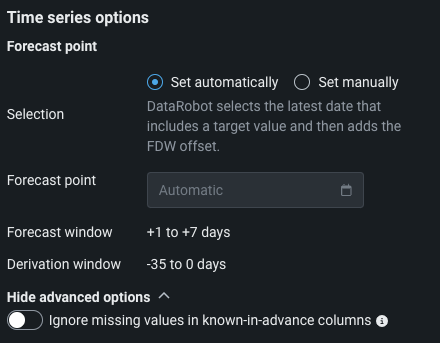
自動的に設定:DataRobotは、スコアリングデータに基づいて、予測ポイントを自動的に設定します(通常は、可能な限り最新の日付タイムスタンプが、有効な予測ポイントです)。
-
手動で設定:日付セレクターを使用して開始および終了の日付を手動で指定し、特定の日付範囲を設定します。
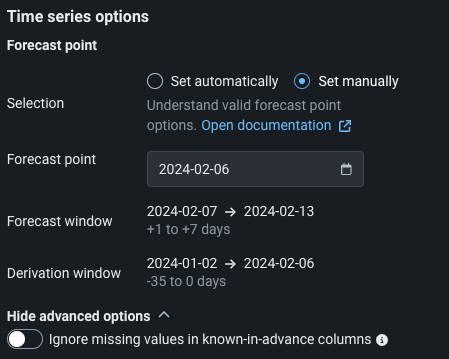
さらに、高度なオプションを表示をクリックし、事前に既知の列の欠損値を無視するを有効にすると、指定されたソースデータセットの事前に既知の列で欠損値があっても、予測を行うことができます。ただし、これは計算された予測に悪影響を及ぼす可能性があります。
予測オプションの設定¶
ファイルがアップロードされたら、予測オプションを設定します。 高度なオプションを表示をクリックし、追加のオプションを設定します。(オプション)
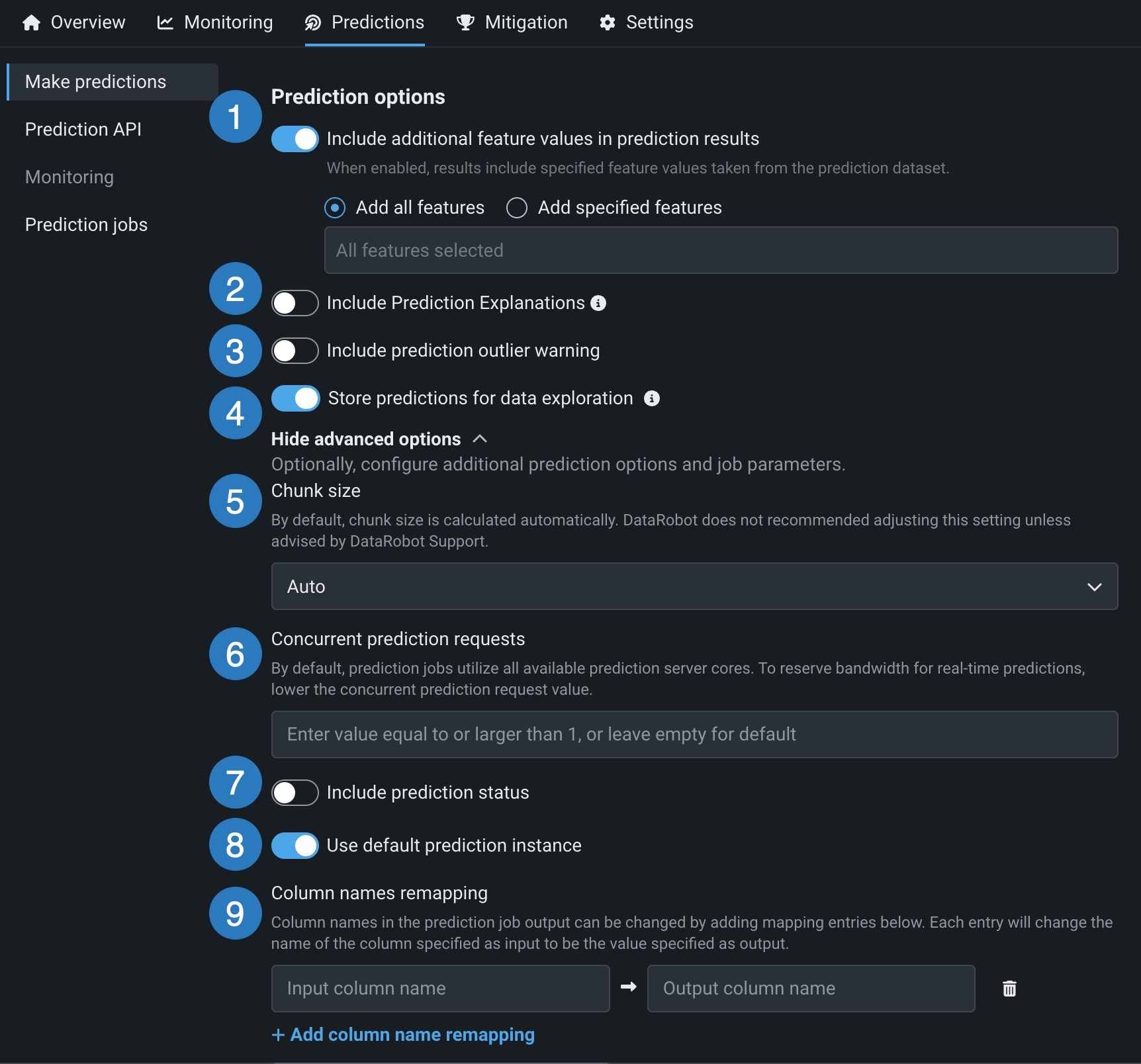
| 要素 | 説明 | |
|---|---|---|
| 1 | 予測結果に追加の特徴量値を含める | 予測値と一緒に入力特徴量を予測結果ファイルに書き込みます。 特定の特徴量を追加するには、予測結果に追加の特徴量値を含めるをオンに切り替えて、指定された特徴量を追加を選択し、フィルターする特徴量名を入力して、特徴量を選択します。 データセットのすべての特徴量を含めるには、すべての特徴量を追加を選択します。 追加できるのは元のデータセットに存在する特徴量(列)だけですが、その特徴量は、モデルの構築に使用した特徴量セットの一部である必要はありません。 派生した特徴量は含まれません。 |
| 2 | 予測の説明を含める | 予測の出力結果に 予測の説明のための列を追加します。
|
| 3 | 予測外れ値警告を含める | 外れ値の予測値に対する警告を含めます(連続値モデルデプロイでのみ使用可能)。 |
| 4 | データ探索のために予測を保存 | データドリフト、精度、データ探索、公平性を追跡します(デプロイで有効になっている場合)。 |
| 5 | チャンクサイズ | チャンクサイズの選択方法を調整します。 デフォルトでは、チャンクサイズは自動的に計算されます。この設定は、DataRobotの担当者から勧められた場合にのみ変更してください。 詳細については、チャンクサイズとは?を参照してください。 |
| 6 | 予測リクエストの同時実行 | 予測リクエストの同時実行数を制限します。 デフォルトでは、予測ジョブは利用可能な予測サーバーコアをすべて使用します。 リアルタイム予測用に処理能力を確保するには、同時予測リクエストの最大数に上限を設けます。 |
| 7 | 予測ステータスを含める | 予測のステータスを含む列を追加します。 |
| 8 | デフォルトの予測インスタンスを使用 | 予測インスタンスを変更できます。 トグルをオフにして、予測インスタンスを選択します。 |
| 9 | 列名の再マッピング | 予測ジョブの出力の列名を、このフィールドに追加されたエントリーにマッピングして変更します。 + 列名の再マッピングを追加をクリックし、入力列名を予測出力で指定された出力列名に置き換えるように定義します。 列名マッピングの追加を間違えた場合は、削除アイコン をクリックして削除できます。 |
予測の説明を有効にできないのはなぜですか?
予測の説明を含めることができない場合、次の理由が考えられます。
-
モデルの検定パーティションに、必要な行数が含まれていません。
-
統合されたモデルで、少なくとも1つのセグメントチャンピオンの検定パーティションに、必要な行数が含まれていません。 予測の説明を有効にするには、モデルパッケージやデプロイを作成する前に、再トレーニングしたチャンピオンを手動で置き換えてください。
チャンクサイズとは?
バッチ予測プロセスでは、データが小さな断片に分割され、それらの断片が1つずつスコアリングされるため、DataRobotは大量のバッチをスコアリングできます。 チャンクサイズの設定では、DataRobotがデータをチャンク化するために使用する方法を決定します。 DataRobotは、全体的に最もパフォーマンスが高いデフォルト設定の自動チャンク化をお勧めしますが、他のオプションも利用できます。
-
固定:DataRobotは、最初に有効なチャンクサイズを識別し、モデルのスコアリングプロセスの残りの部分でそのサイズを引き続き使用します。
-
動的:DataRobotは、モデルのスコアリング速度が許容範囲内である間はチャンクサイズを大きくし、スコアリング速度が低下するとチャンクサイズを小さくします。
-
カスタム:データサイエンティストがチャンクサイズを設定すると、DataRobotは残りのモデルスコアリングプロセスでそのチャンクサイズを使用し続けます。
予測を計算およびダウンロード¶
予測オプションを設定したら、予測を計算およびダウンロードをクリックしてデータのスコアリングを開始し、最近の予測をダウンロードでスコアリング結果を表示します。 完成した予測ジョブに対して以下のアクションを実行できます。

| アイコン | アクション |
|---|---|
| 時系列予測で、予測の視覚化を表示します。 | |
| 予測ファイルをダウンロードします。 | |
| ログにアクセスして、予測ジョブの実行の詳細を確認し、必要に応じてコピーします。 |
48時間以内であれば、予測 > 予測を作成ページから予測をダウンロードできます。
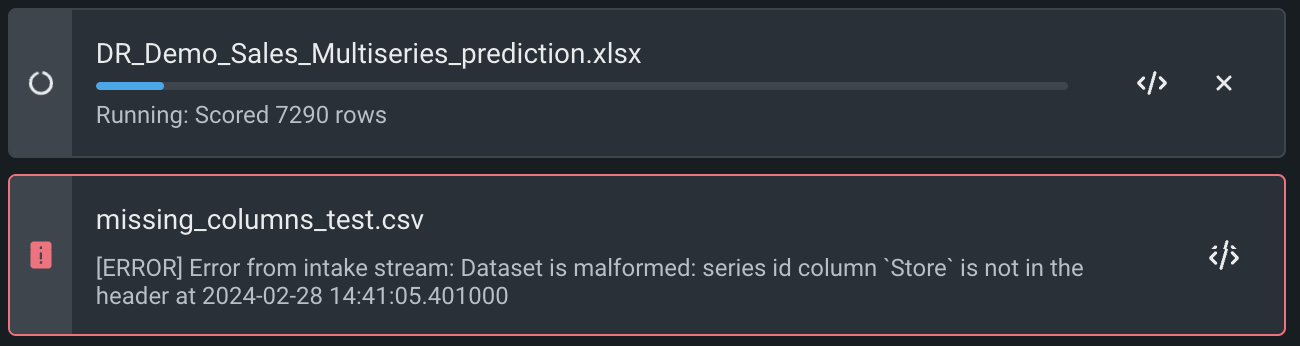
バッチ予測ジョブのキャンセル
ジョブの実行中に停止アイコン をクリックすると、ジョブがキャンセルされます。 For canceled or failed jobs, you can click the logs icon to view the logs for the job.