NVIDIA GPUでNeMo Guardrailsを使用した生成AI¶
本機能の提供について
NVIDIAとNeMo Guardrailsの連携はプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
DataRobotでNVIDIAを使用して、パフォーマンスの高速化を実現し、最高のオープンソースモデルとガードレールを活用することで、エンドツーエンドの生成AI (GenAI) 機能をすばやく構築できます。 DataRobotとNVIDIAの連携により、完全なエンドツーエンドの生成AI機能を提供する推論ソフトウェアスタックが構築されます。重要な機能がすぐに使えることで、パフォーマンス、ガバナンス、安全性が確保されます。
NVIDIAリソースでのGenAIモデルの作成¶
レジストリでは、DataRobotモデル、カスタムモデル、外部モデルのバージョン履歴にアクセスできます。これには、プロンプトインジェクション監視、センチメント・毒性分類、PII検出などに使われるガードモデルも含まれます。
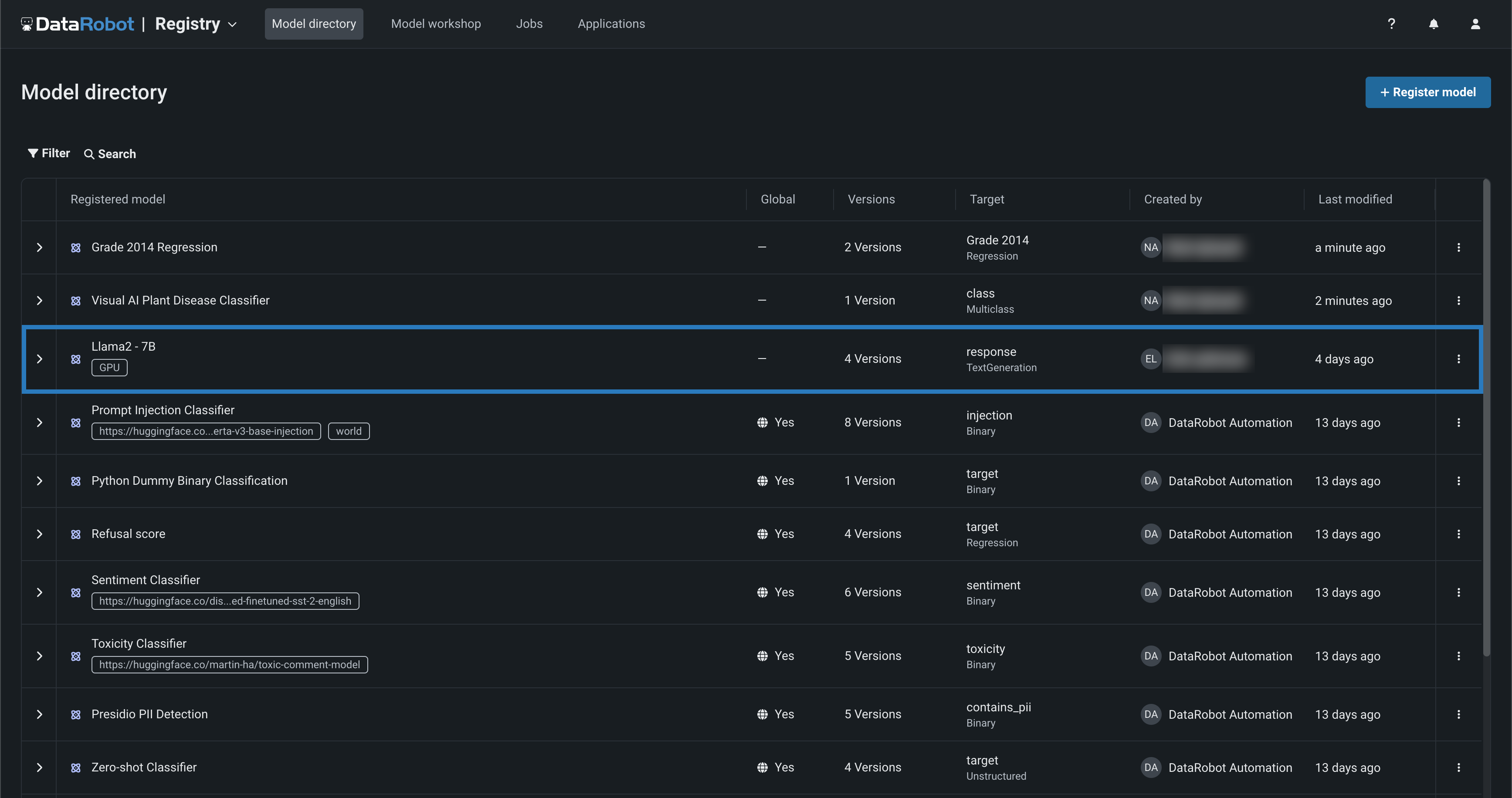
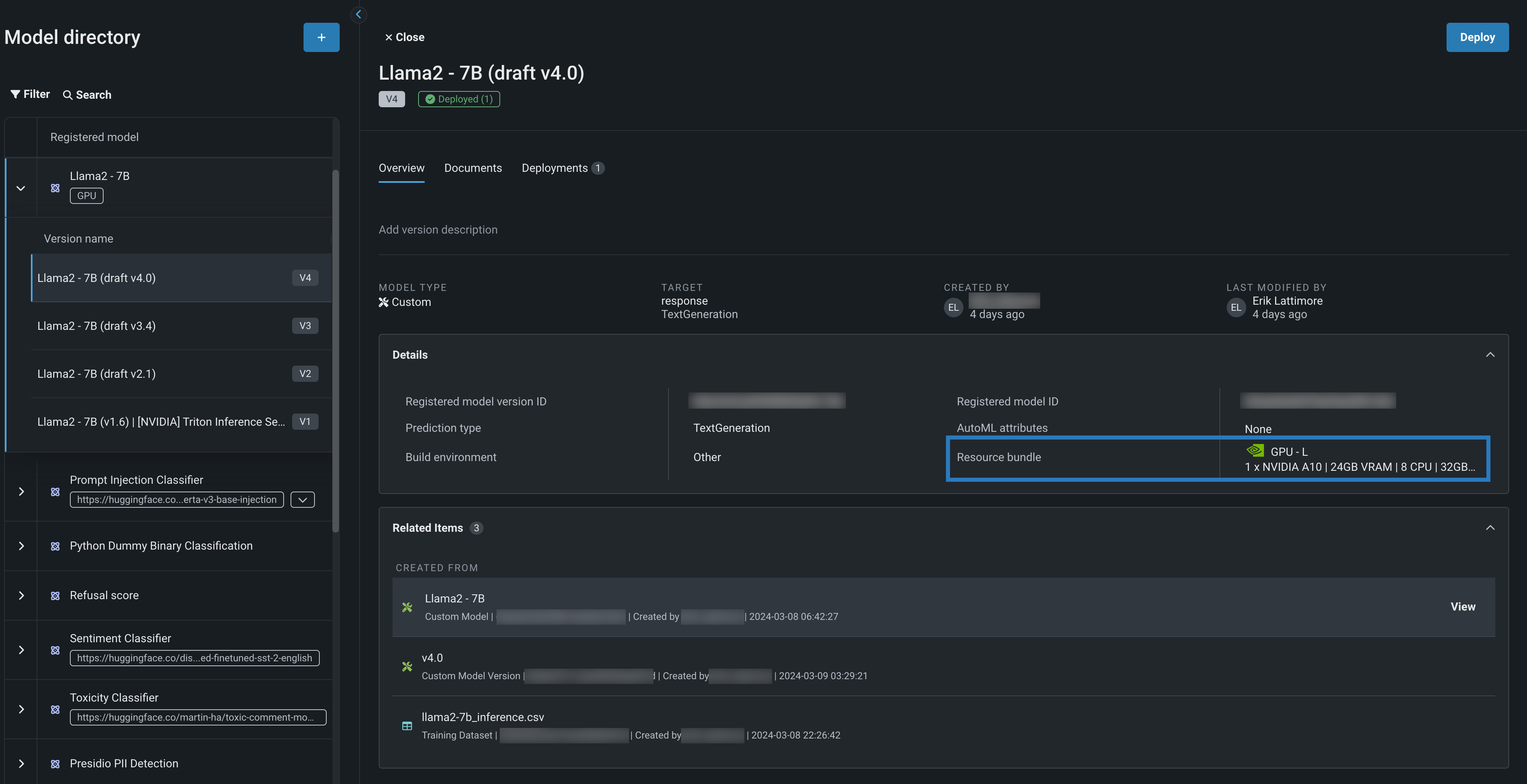
上の例では、モデルディレクトリにあるLlama 2モデルにGPUタグが付いています。 この登録されたモデルを開くと、NVIDIAのリソースバンドルにデプロイするために構築およびテストされたLlama 2モデルの4つのバージョンが、以下に表示されます。
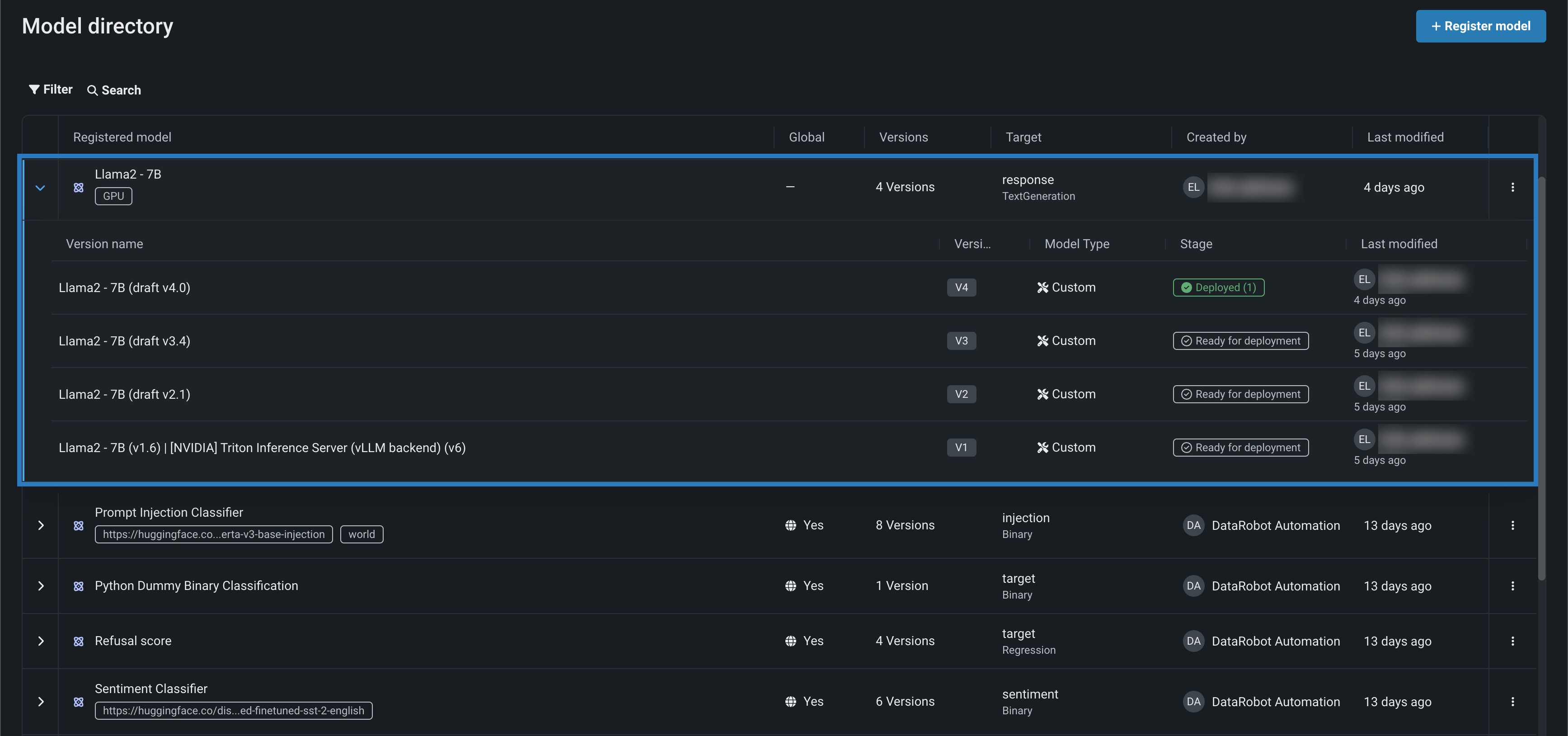
登録モデルのバージョンから、モデルの詳細を確認します。ここで、リソースバンドルは、モデルによって使用されるNVIDIAリソースに関する情報を示します。 関連アイテムパネルを開き、表示をクリックすると、モデルワークショップでLlama 2カスタムモデルが開きます。
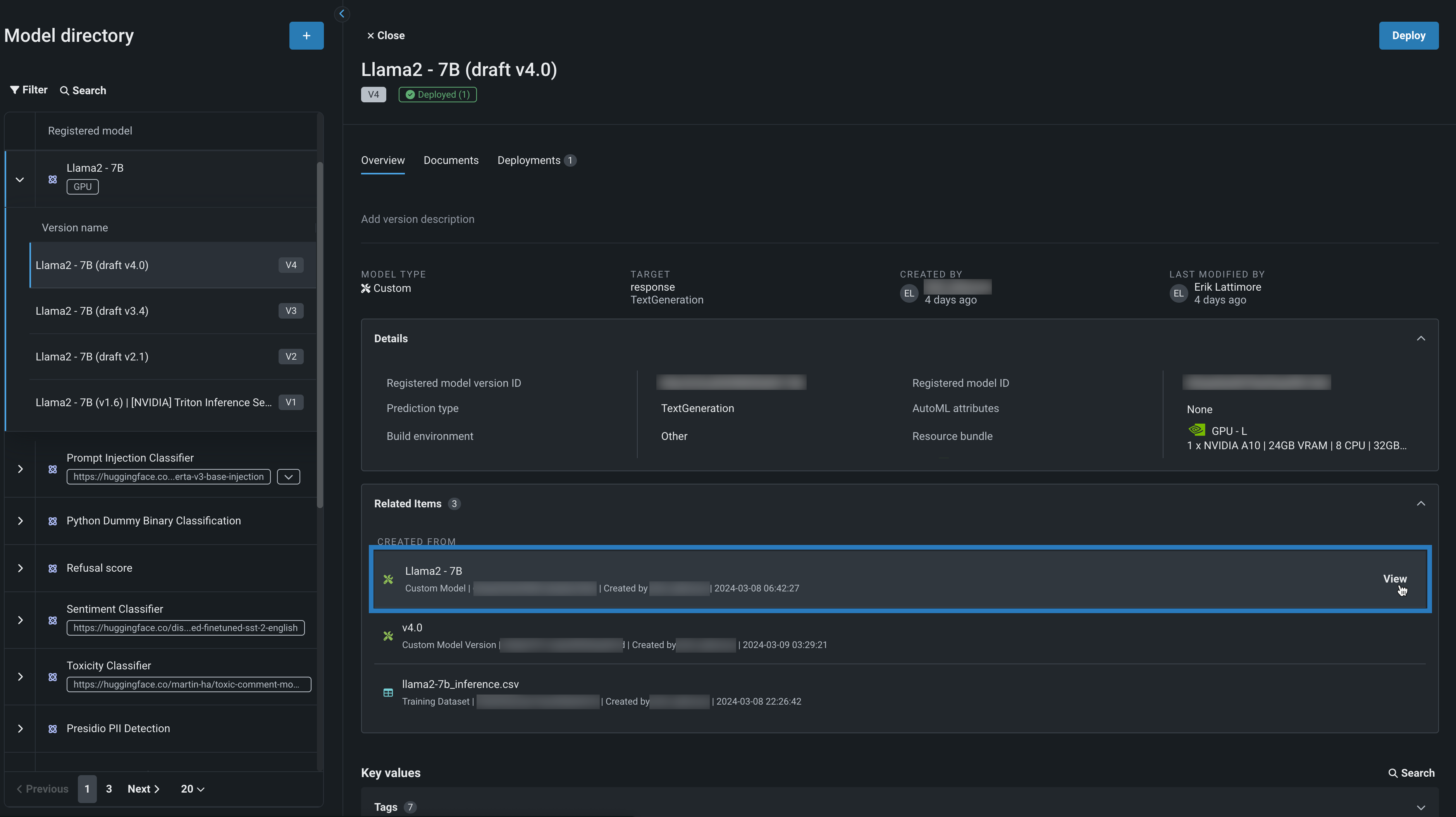
モデルワークショップから、Llama 2カスタムモデルのアセンブルタブを開いて表示し、モデルがどのように構築されたかを確認します。 このモデルでは、DataRobotのバージョンが構築され、テストされていることがわかります。 環境セクションでは、モデルが[NVIDIA] Triton Inference Serverの基本環境で動作していることがわかります。 DataRobotにはNVIDIA Triton Inference Serverがネイティブに組み込まれており、GPUベースのモデルをNVIDIAデバイスに構築・デプロイする際に、特別なアクセラレーションを提供します。
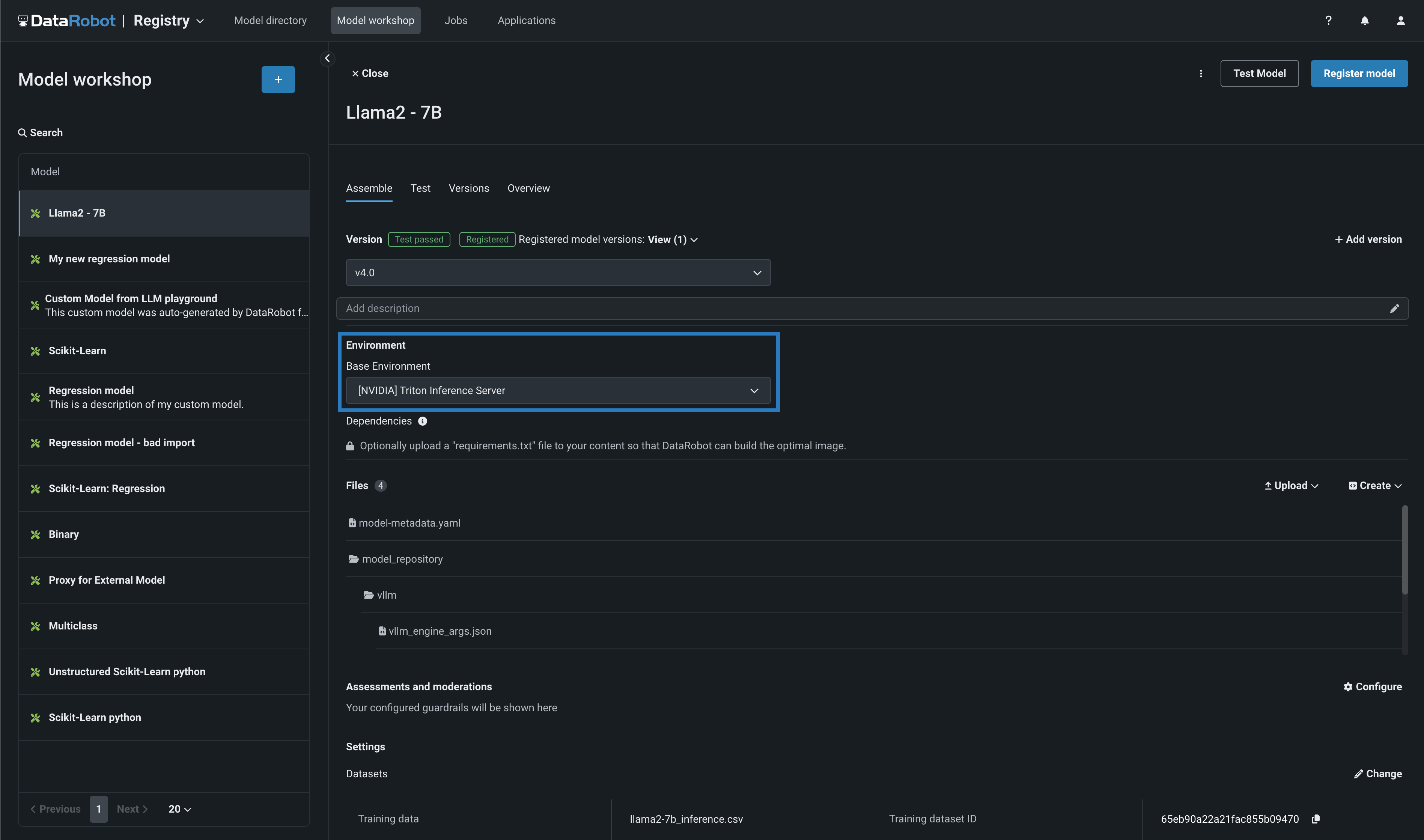
ファイルセクションでは、モデルファイルの表示、変更、追加を行うことができます。 ランタイムパラメーターセクションでは、実行時に動的に構築プロセスに渡す重要な情報を指定できます。 このタブでカスタムモデルに変更を加えると、新しいマイナーバージョンが作成されます。
カスタムモデルの設定セクションに移動し、リソース設定を確認します。これは、モデルに提供されたリソースに関する情報を表示するセクションです。 この例では、Llama 2モデルがNVIDIA A10デバイスでテストおよびデプロイされるように構築されていることがわかります。
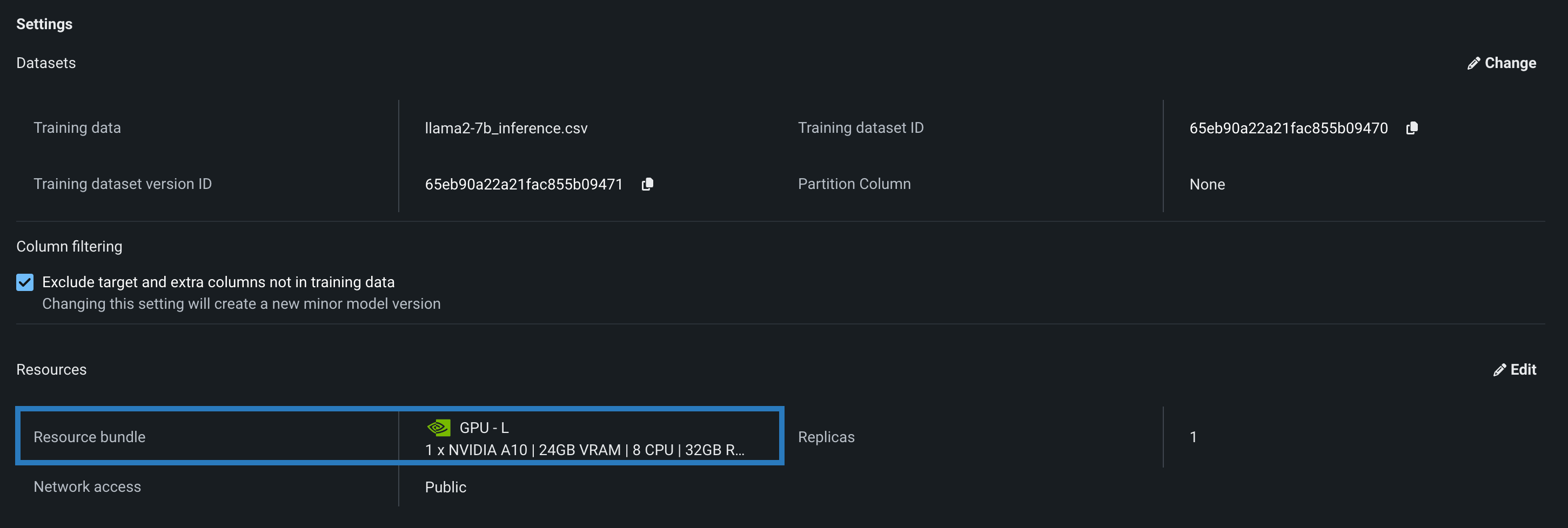
編集をクリックしてリソース設定の更新ダイアログボックスを開き、リソースのバンドル設定で、DataRobotの構築環境として使用可能な NVIDIAデバイスの範囲を確認します。
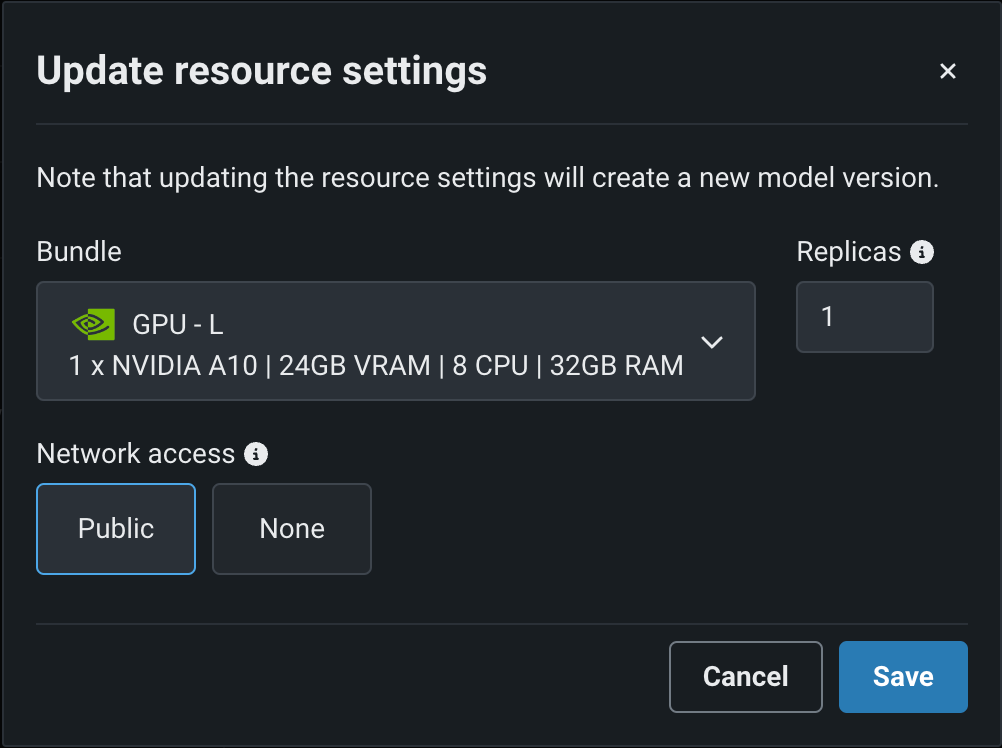
DataRobotは、これらのNVIDIAリソースバンドルのいずれにもモデルをデプロイできます。
| バンドル | GPU | VRAM | CPU | RAM |
|---|---|---|---|---|
| GPU - S | 1 x NVIDIA T4 | 16GB | 4 | 16GB |
| GPU - M | 1 x NVIDIA T4 | 16GB | 8 | 32GB |
| GPU - L | 1 x NVIDIA A10 | 24GB | 8 | 32GB |
NVIDIA Triton Inference Serverのモデルを構築したら、テストタブを開くことができます。 そこから、DataRobotは、コンテナがスタートアップテストと予測エラーテストに合格しているかどうかを確認できます。 DataRobotには、さまざまなカスタムモデルテスト機能が用意されています。
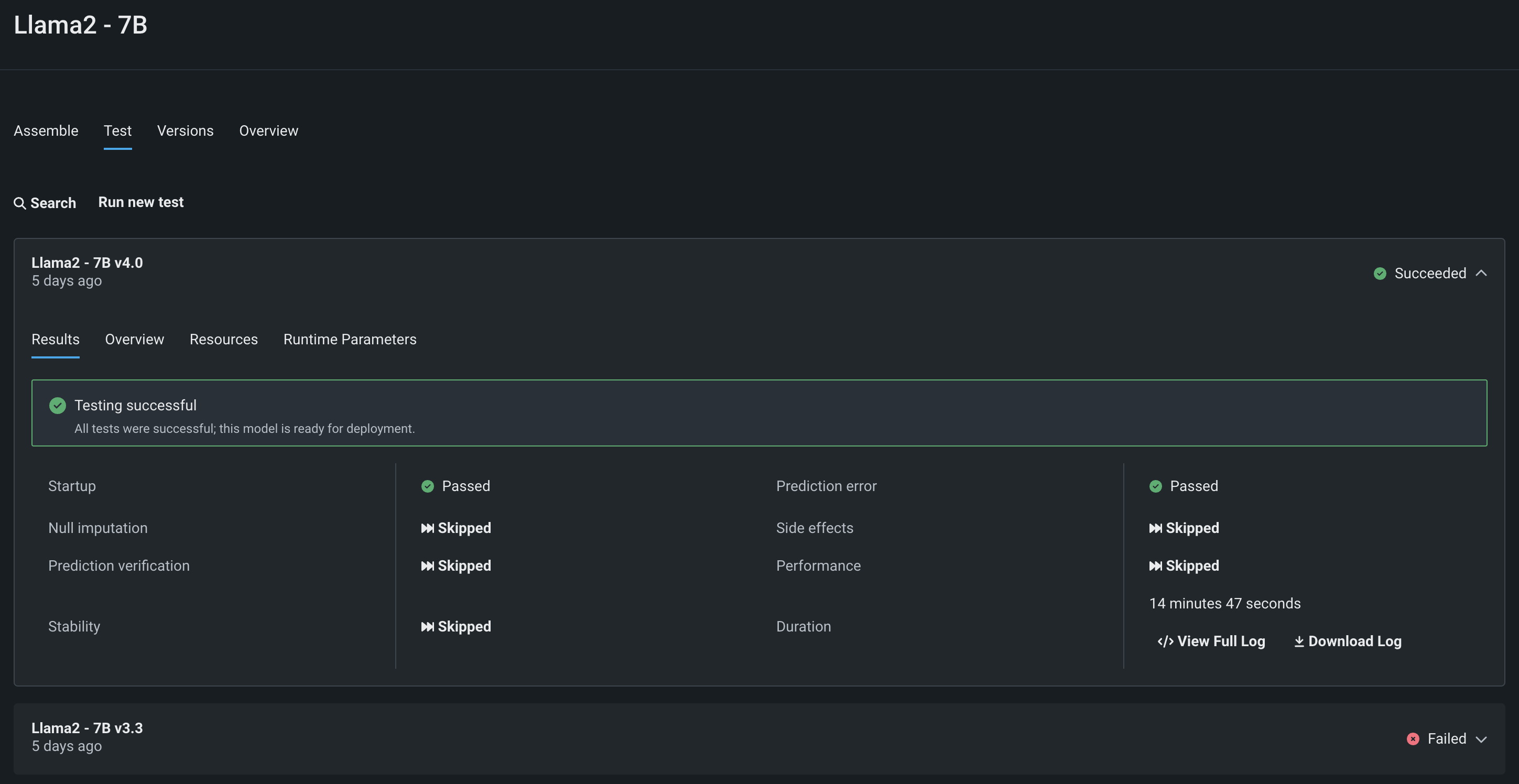
さらに、ランタイムパラメータータブでは、本番環境と同じように、実行時のモデルにパラメーターを渡してテストすることで、NVIDIA Triton Inference Serverに構築されたこの新しいモデルコンテナが正しく設定され、本番環境で使用できるか確認できます。
本番環境へのモデルのデプロイ¶
Llama 2モデルがNVIDIAのリソースバンドルで構築およびテストされたので、モデルを登録することができます。 この例では、モデルはすでに登録されており、カスタムモデルは登録モデルのバージョンにリンクされています。 DataRobotでは、レジストリのモデルディレクトリタブに直接接続し、そこでモデルを確認できます。
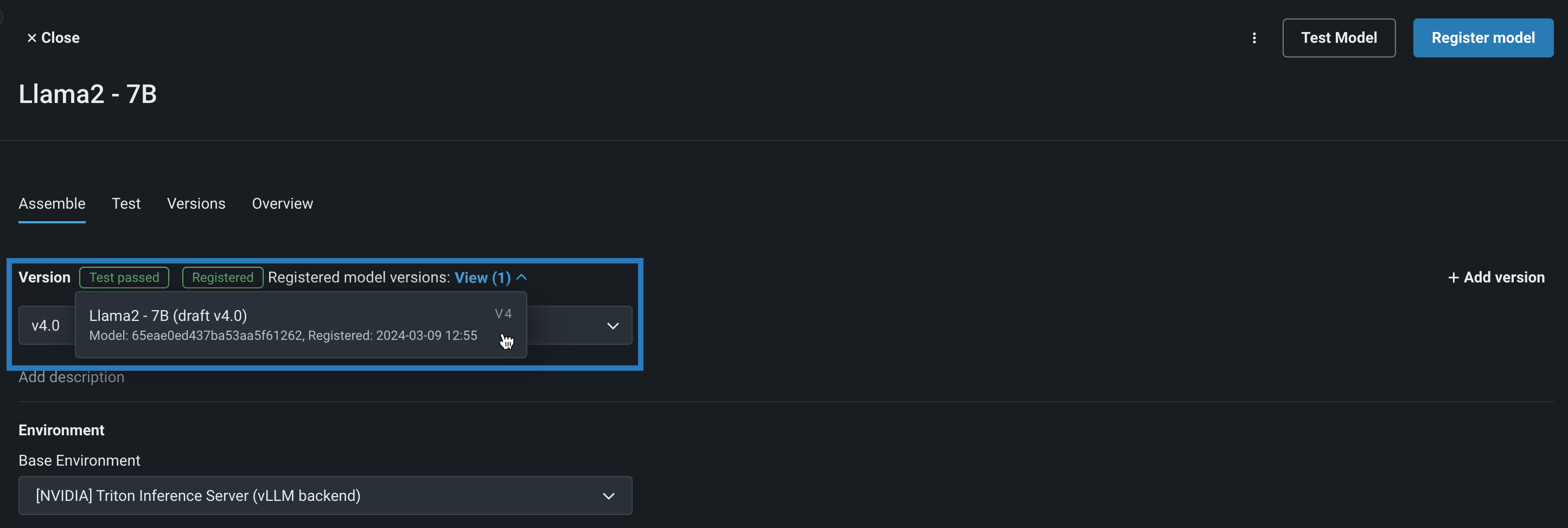
このレジストリに戻ると、複数のビルドが表示され、組織内でこのモデルを共有してソーシャル化し、デプロイの承認を求めることができます。 登録されたモデルから、このモデルがテストされ、デプロイされるべきリソースバンドルがはっきりとわかります。
モデルディレクトリによって提供されるバージョン管理に加えて、レジストリは関連アイテムパネルによってモデルの系統を明確にし、登録されたモデルの作成に使用されたカスタムモデル、カスタムモデルバージョン、トレーニングデータセットを確認できます。 トレーニングデータは、モデルがデプロイされたときのドリフト監視のベースラインとなります。 組織では、特定のビジネスニーズと各カテゴリーに必要な特定のコントロールに基づいて、カスタムメタデータを追加してレジストリ内のモデルを分類および識別することもできます。
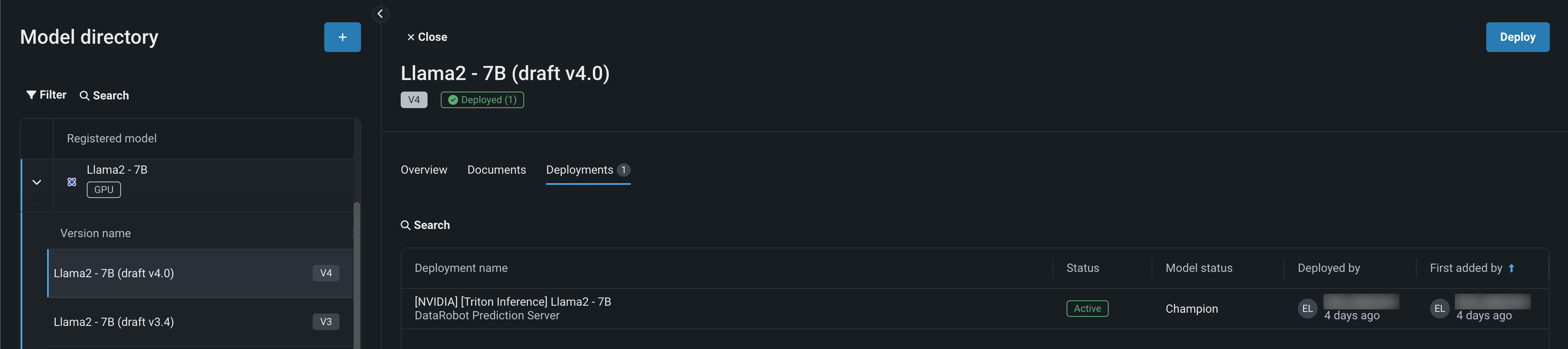
Llama 2モデルの構築、登録、確認が終了したので、適切なNVIDIA A10デバイスにデプロイします。 (この例のLlama 2モデルのように)登録されたモデルがデプロイされると、モデルバージョンのデプロイタブで、レジストリからデプロイを表示およびアクセスできます。
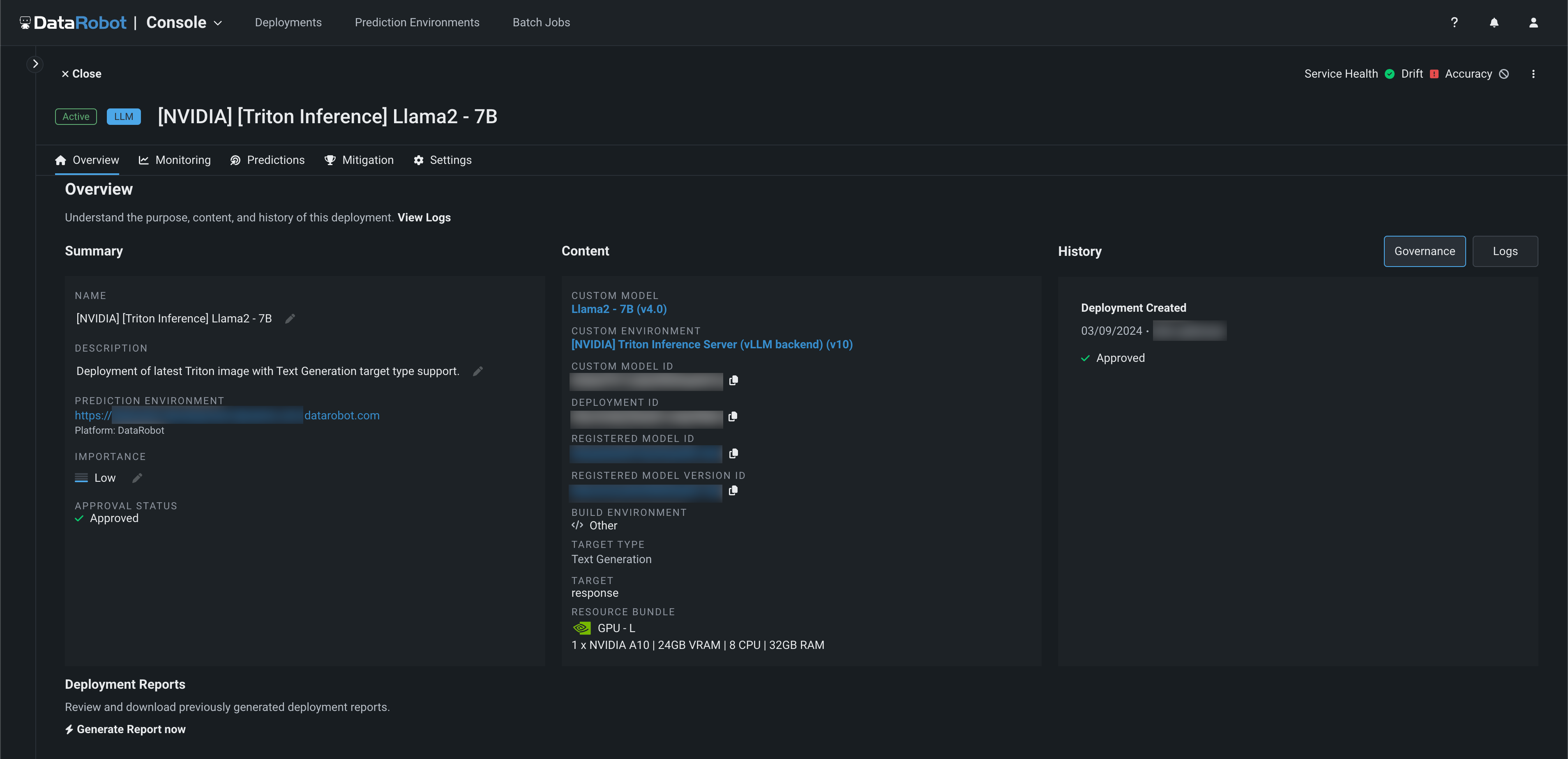
デプロイを開くと、概要タブから、DataRobotがこのモデルのデプロイの承認プロセスをガバナンスしていることがわかります。 モデルの履歴セクションのガバナンスタブには、デプロイが承認されたことを示す永続的な記録があります。 ログタブでは、モデルが置き換えられたかどうか、置き換えられた場合は置き換えの理由があったかどうかを確認できます。 この例では、このモデルはつい最近デプロイされたばかりなので、まだ置き換えられていません。しかし、長期にわたって、DataRobotはこのデプロイされたモデルの履歴と、このエンドポイントの後にデプロイされた追加のモデルの履歴を記録し続けます。 さらに、Llama 2モデルがデプロイされているリソースバンドル、モデルの系統に関する情報、レジストリ内のモデルアーティファクトへのリンクを一緒に確認できます。
デプロイ済みモデルの監視¶
モデルがデプロイされると、DataRobotは、IT指標を始めとするさまざまな監視ツールを提供します。 情報統計(タイル値)は、モデルと時間枠(スライダーで選択)の現在の設定に基づいています。 スライダーの間隔値が週の場合、表示されるタイル指標は週に対応します。 指標タイルをクリックすると、タイルの下のチャートが更新されます。
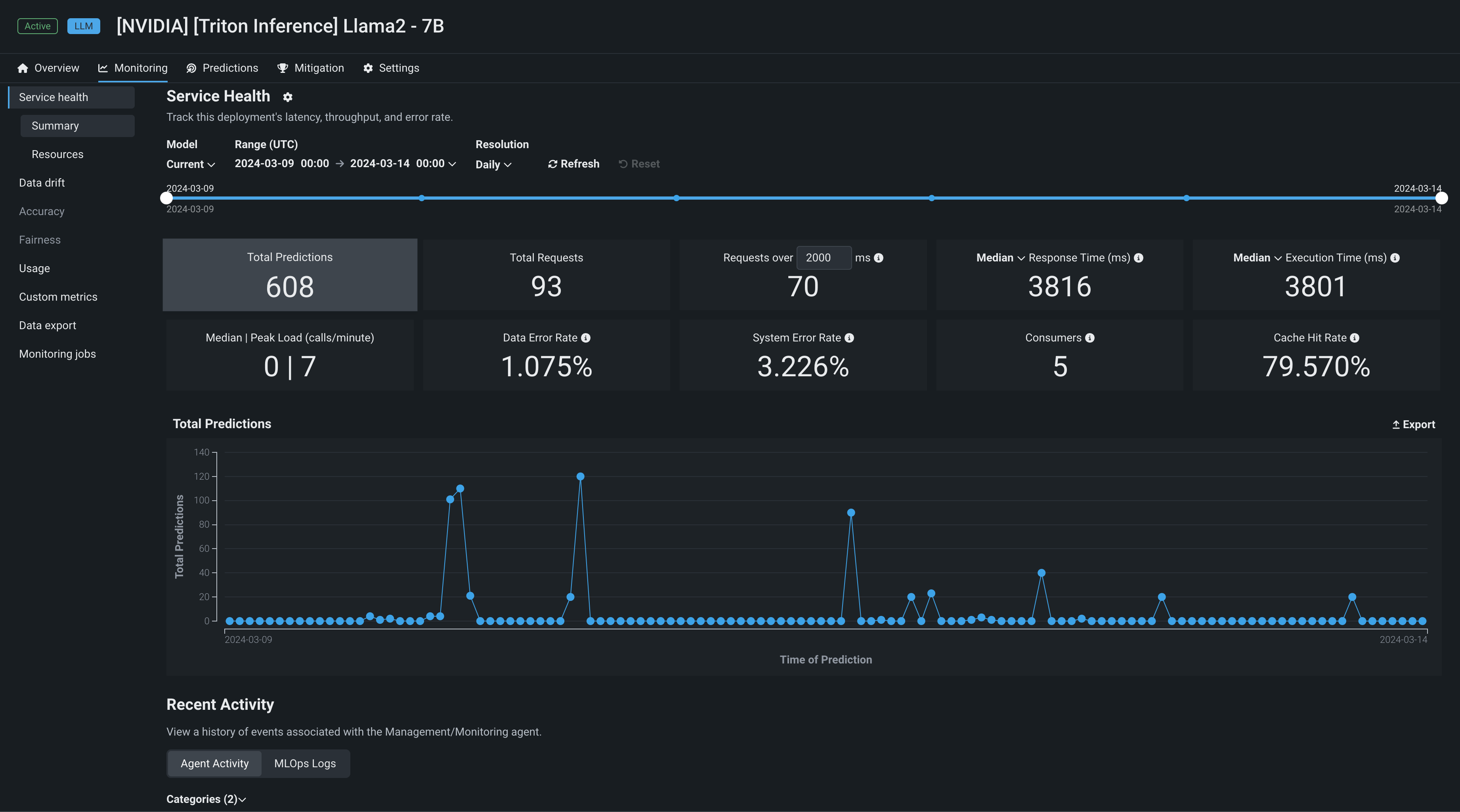
モニタリング > サービスの正常性には、以下の指標がレポートされます。
| 統計 | 選択した時間枠のレポート... |
|---|---|
| 予測の合計数 | デプロイで作成された予測の数。 |
| リクエストの合計数 | デプロイが受信した予測リクエストの数(単一のリクエストに複数の予測リクエストが含まれる場合があります)。 |
xミリ秒以上のリクエスト |
指定されたミリ秒よりもレスポンス時間が長かったリクエストの数。 デフォルトは2000msです。ボックスをクリックして10~100,000msの時間を入力するか、コントロールを使用して値を調整します。 |
| レスポンス時間 | DataRobotが予測リクエストの受信、リクエストの計算、およびユーザーへの応答に要した時間(ミリ秒)。 レポートにはネットワークレイテンシーの時間は含まれません。 予測リクエスト時間の中央値、あるいは90番目、95番目、または99番目のパーセンタイルを選択します。 リクエストがなかったデプロイや外部デプロイの場合は、ダッシュ(-)が表示されます。 |
| 実行時間 | DataRobotが予測リクエストの計算に要した時間(ミリ秒)。 予測リクエスト時間の中央値、あるいは90番目、95番目、または99番目のパーセンタイルを選択します。 |
| 負荷(コール数/分)の中央値 / 最高値 | 1分あたりの要求数の中央値と最大値。 |
| データエラーの割合 | 4xxエラーが発生したリクエストの割合(予測リクエスト送信の問題)。 |
| システムエラーの割合 | 5xxエラーが発生した適切な形式のリクエストのパーセンテージ(DataRobot予測サーバーの問題)。 |
| コンシューマー数 | このデプロイに対して予測リクエストを行った個々のユーザー(APIキーによって識別)の数。 |
| キャッシュヒット率 | キャッシュされたモデルを使用したリクエストのパーセンテージ(その他の予測で最近使用されたモデル)。 キャッシュされていない場合、モデルのルックアップが行われるので、遅延が発生することがあります。 デフォルトで予測サーバーのキャッシュには16のモデルが保持され、制限に達した場合は最も使用頻度が低いモデルが破棄されます。 |
サービスの正常性に加えて、DataRobotはプロンプトと補完のデータドリフトを別個に追跡します。 プロンプトと回答のワードクラウドでは、モデルの構築時にアップロードされたトレーニングデータセットによって確立されたベースラインと比較したときに、どのトークンがドリフトに最も影響を及ぼしているかを特定できます(登録済みのモデルバージョンで表示可能)。
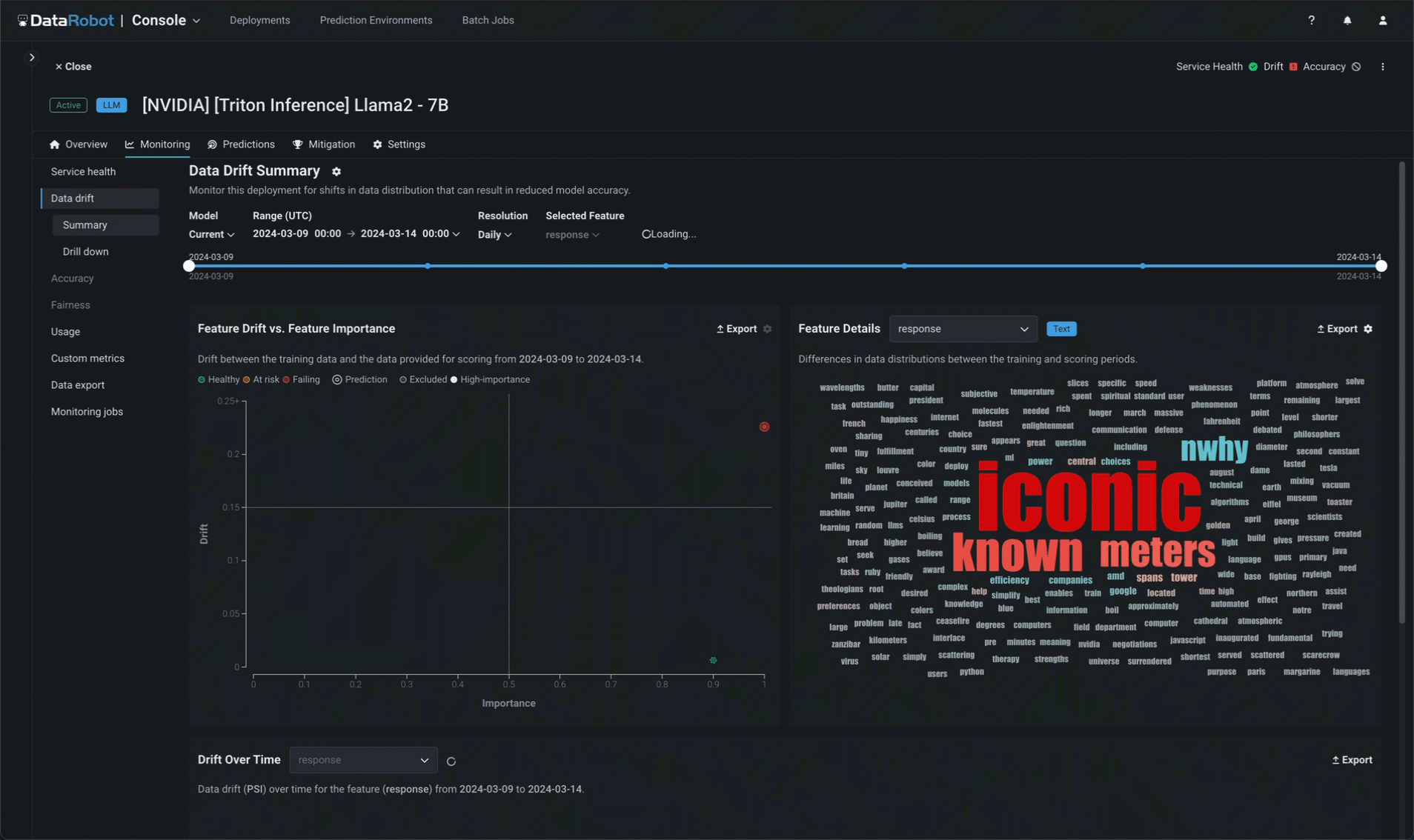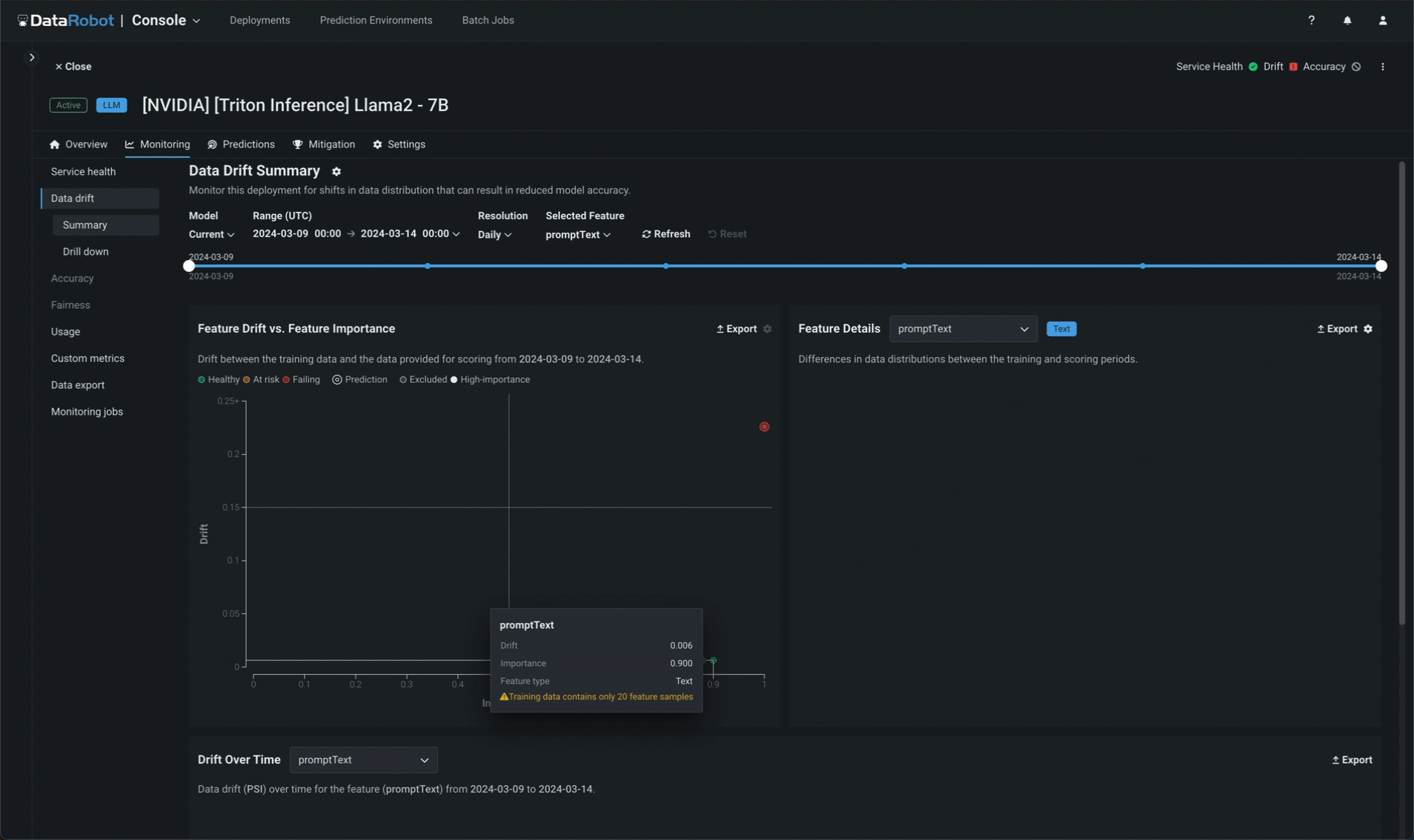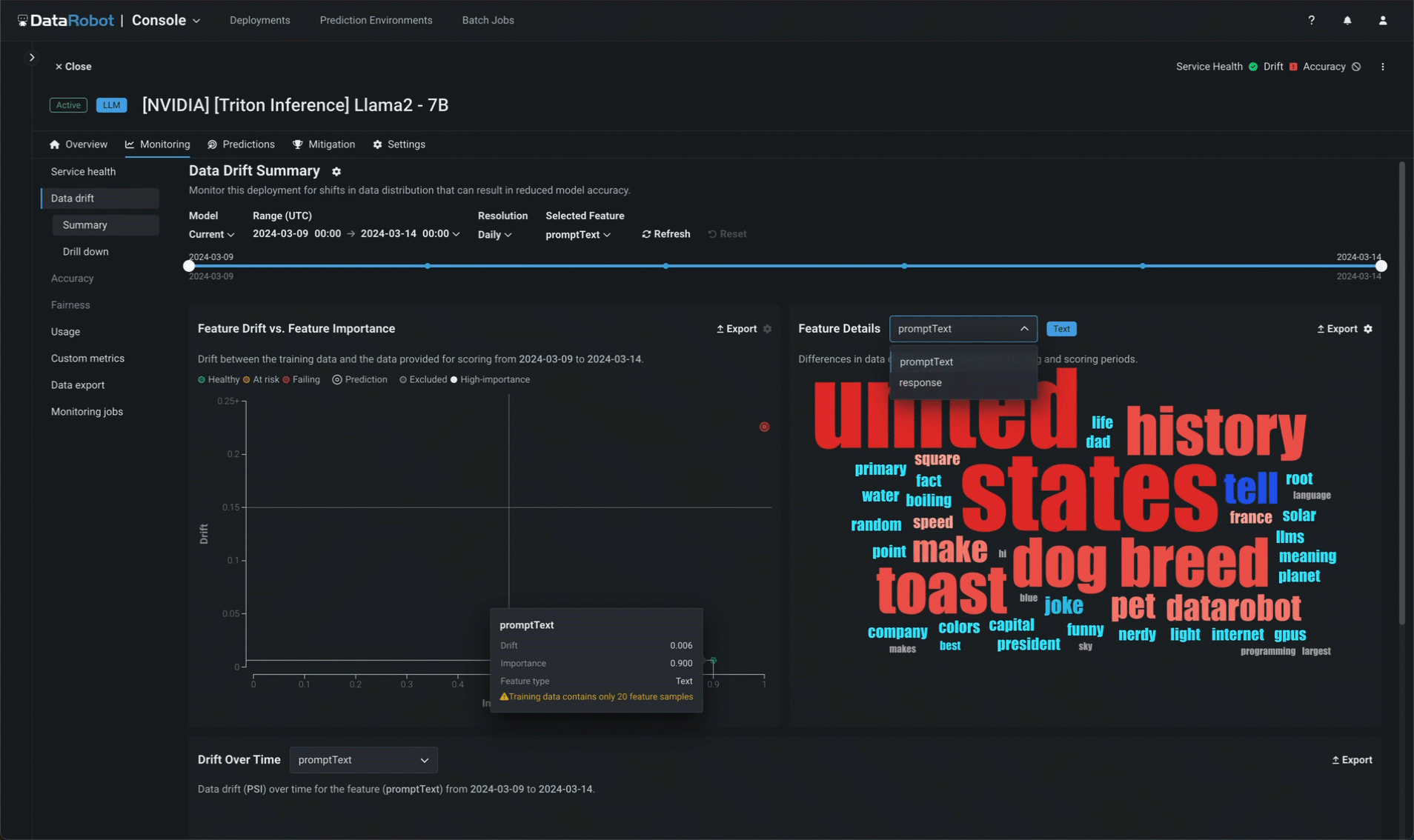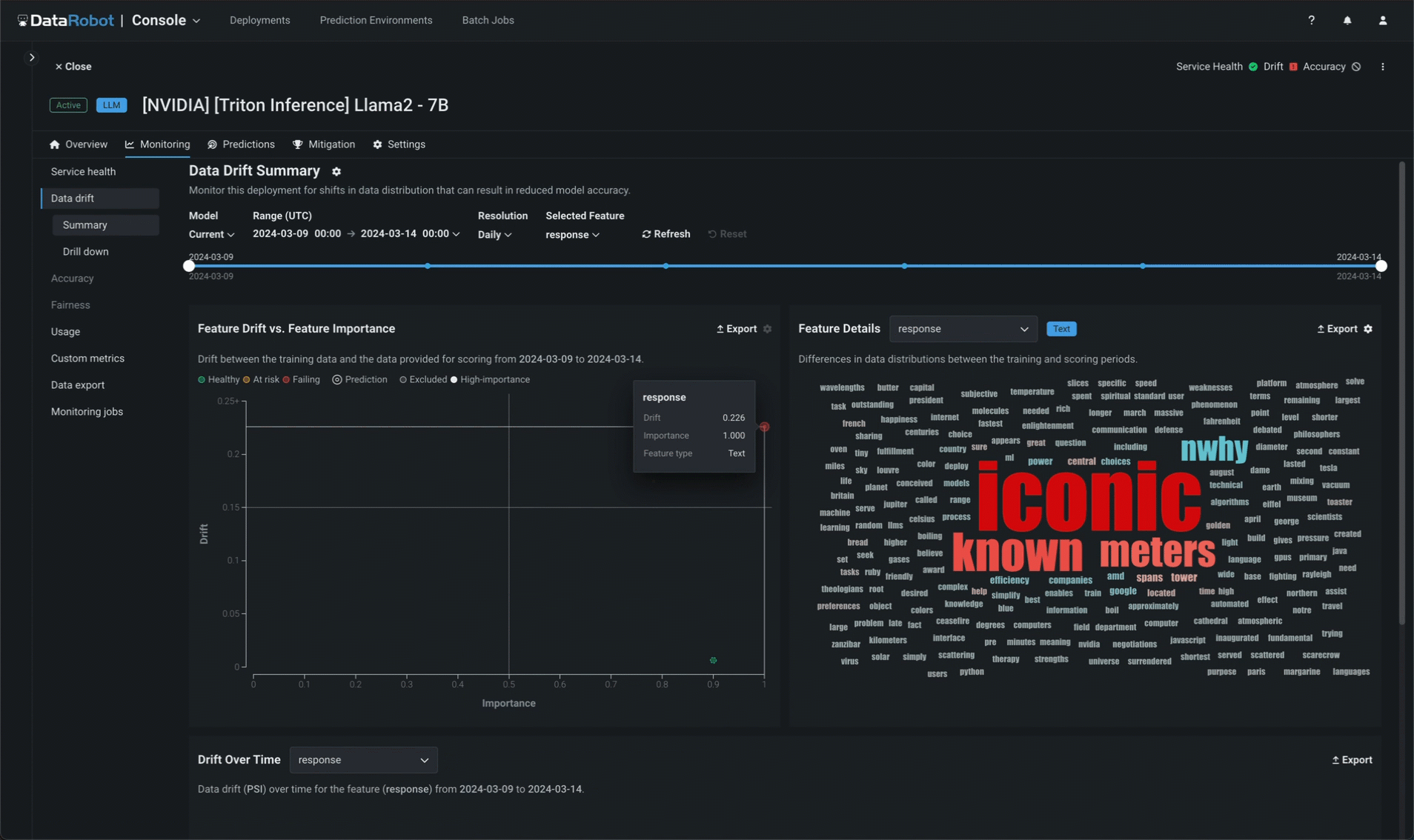
NeMo Guardrailsの実装¶
DataRobotには、すぐに使用できる指標に加えて、ゼロから、テンプレートから、またはNeMo Guardrailsとの連携によって、カスタム指標を作成するための強力なインターフェイスも用意されています。 NeMoとの連携により、NeMoが提供する 「トピックに沿った」原則に違反した場合、プロンプトや補完をブロックする介入を用いて、モデルがトピックに沿った状態を維持できるようにする強力なレールが提供されます。
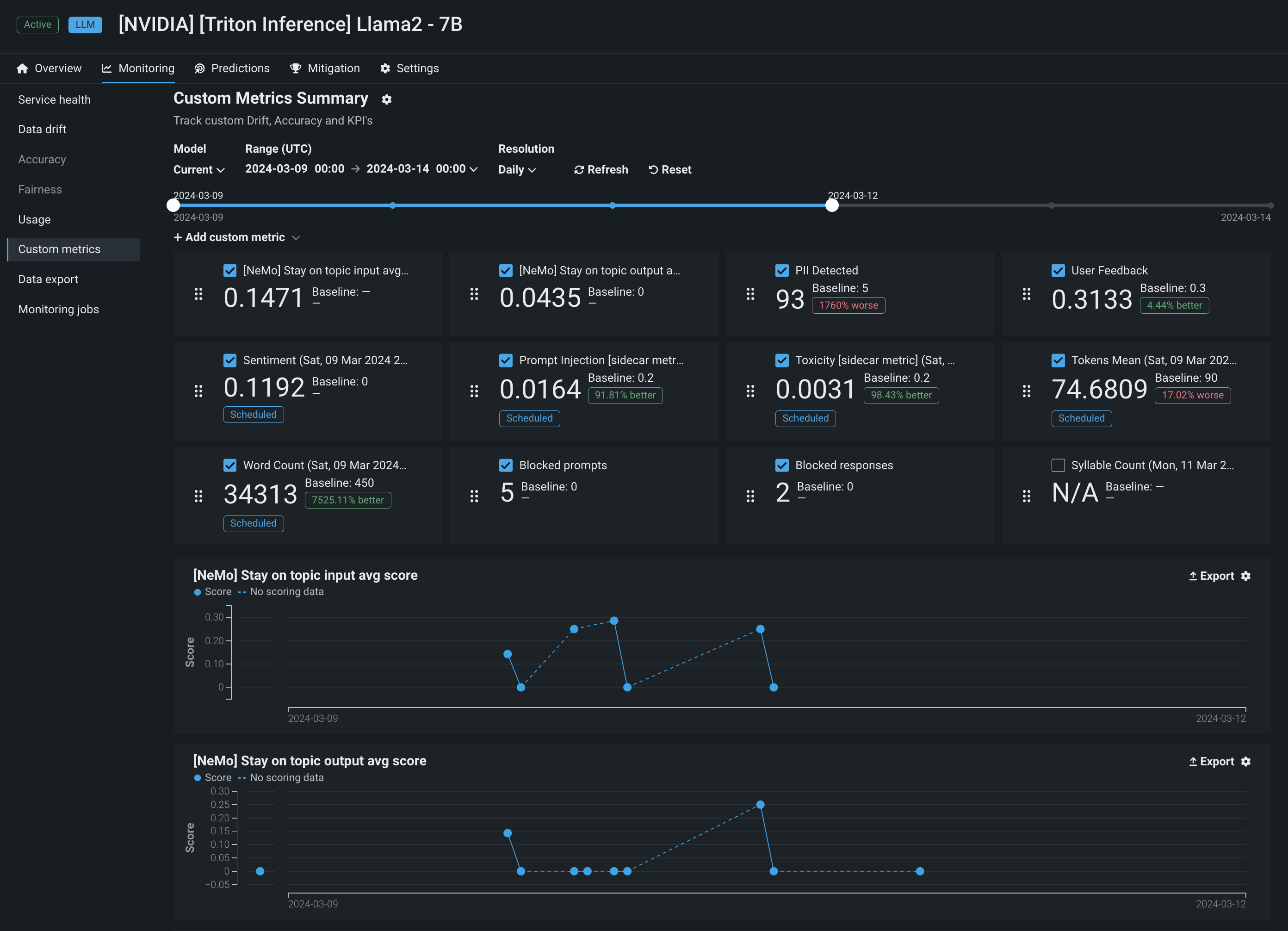
NeMo Guardrailsと同時に、DataRobotが提供する他のガードモデルと連携し、それらの指標を長期にわたって追跡することができます。 たとえば、DataRobotには個人を特定できる情報(PII)の検出に関するガードモデルのテンプレートが用意されているため、PIIのプロンプトをスキャンし、その入力をプロンプトデータベースに保存する前にサニタイズできます。 カスタム指標で、DataRobotは次のことができます。
-
デプロイ監視システムの各行に、(提供されている場合は)ユーザーのフィードバックでアノテーションを付けることによって、ヒューマンフィードバックループを促します。
-
プロンプトインジェクションを監視して、モデルが影響を受けないように介入を行うことができます。
-
プロンプトと回答において、センチメントおよび毒性を監視します。
-
トークンの使用状況を監視して、コストなどの運用指標を計算します。