定期的なバッチ予測ジョブのスケジュール¶
1回限りのバッチ予測を行うことも、定期的にバッチ予測ジョブをスケジュールすることもできます。 このセクションでは、バッチ予測ジョブを作成およびスケジュールする方法を示します。
先に進む前に、デプロイと予測に関する注意事項を必ず確認してください。
予測ジョブ定義の作成¶
ジョブ定義は、バッチ予測ジョブを作成するための柔軟なテンプレートです。 DataRobot内部に定義を保存し、ワンクリック、APIコール、またはスケジュールによる自動実行で、新たなジョブを実行できます。 スケジュールされたジョブでは、各リクエストに対して接続、認証、予測のオプションを指定する必要はありません。
デプロイのジョブ定義を作成するには、ジョブ定義タブに移動します。 次の表では、新しい予測ジョブ定義タブで利用可能な情報とアクションについて説明します。

| フィールド名 | 説明 | |
|---|---|---|
| 1 | 予測ジョブ定義名 | デプロイのために作成する予測ジョブの名前を入力します。 |
| 2 | 予測ソース | ソースのタイプを設定し、スコアリングするデータの接続を定義します。 |
| 3 | 予測オプション | 予測オプションを設定します。 |
| 4 | 時系列オプション | 時系列予測の方法を指定および設定します。 |
| 5 | 予測先 | 予測の出力先を示します。 宛先タイプを設定し、接続を定義します。 |
| 6 | ジョブスケジュール | ジョブをすぐに実行するかどうか、およびジョブをスケジュールするかどうかを切り替えます。 |
| 7 | 予測ジョブ定義を保存 | このボタンをクリックして、ジョブ定義を保存します。 このジョブをすぐに実行トグルがオンになっている場合、このボタンは予測ジョブ定義を保存して実行に変わります。 検定エラーがある場合、このボタンは無効になっています。 |
設定が完了したら、予測ジョブ定義を保存(または、このジョブをすぐに実行が有効になっている場合は、予測ジョブ定義を保存して実行)をクリックします。
備考
新しい予測ジョブ定義タブでの入力が完了すると、バッチ予測APIに必要な詳細が設定されます。 詳細は、バッチ予測APIのドキュメントを参照してください。
予測ソースの設定¶
予測ソース(別名入力アダプター)を選択します。

予測ソースを設定するには、ソースのタイプに応じた適切な認証ワークフローを完了させます。
AIカタログソースの場合、ジョブ定義には、変更日、ソースを設定したユーザー、アセットの状態を表すバッジ(この場合はSTATIC)が表示されます。
予測ソースを設定すると、DataRobotはそのデータがデプロイ済みモデルに適用可能であるかを検証します。

備考
DataRobotは、データソースがデプロイ済みモデルに適用可能であるかどうかをできる限り検証しますが、すべてのケースで検証できるわけではありません。 DataRobotは、AIカタログ、ほとんどのJDBC接続、Snowflake、Synapseで検証を行います。
ソース接続タイプ¶
以下の接続タイプを選択すると、フィールドの説明が表示されます。
備考
接続の参照時に無効なアダプターは表示されません。
データベース接続
クラウドストレージ接続
- Azure
- Google Cloud Storage(GCP Cloud)
- S3
データウェアハウス接続
その他
サポートされているデータソースの詳細については、バッチ予測でサポートされているデータソースを参照してください。
予測オプションの設定¶
予測結果に含める情報を指定します。

| 要素 | 説明 | |
|---|---|---|
| 1 | 予測結果に追加の特徴量値を含める | 予測値と一緒に入力特徴量を予測結果ファイルに書き込みます。 特定の特徴量を追加するには、予測結果に追加の特徴量値を含めるをオンに切り替えて、指定された特徴量を追加を選択し、フィルターする特徴量名を入力して、特徴量を選択します。 データセットのすべての特徴量を含めるには、すべての特徴量を追加を選択します。 追加できるのは元のデータセットに存在する特徴量(列)だけですが、その特徴量は、モデルの構築に使用した特徴量セットの一部である必要はありません。 派生した特徴量は含まれません。 |
| 2 | 予測の説明を含める | 予測の出力結果に 予測の説明のための列を追加します。
|
| 3 | 予測外れ値警告を含める | 外れ値の予測値に対する警告を含めます(連続値モデルデプロイでのみ使用可能)。 |
| 4 | データ探索のために予測を保存 | データドリフト、精度、データ探索、公平性を追跡します(デプロイで有効になっている場合)。 |
| 5 | チャンクサイズ | チャンクサイズの選択方法を調整します。 デフォルトでは、チャンクサイズは自動的に計算されます。この設定は、DataRobotの担当者から勧められた場合にのみ変更してください。 詳細については、チャンクサイズとは?を参照してください。 |
| 6 | 予測リクエストの同時実行 | 予測リクエストの同時実行数を制限します。 デフォルトでは、予測ジョブは利用可能な予測サーバーコアをすべて使用します。 リアルタイム予測用に処理能力を確保するには、同時予測リクエストの最大数に上限を設けます。 |
| 7 | 予測ステータスを含める | 予測のステータスを含む列を追加します。 |
| 8 | デフォルトの予測インスタンスを使用 | 予測インスタンスを変更できます。 トグルをオフにして、予測インスタンスを選択します。 |
| 9 | 列名の再マッピング | 予測ジョブの出力の列名を、このフィールドに追加されたエントリーにマッピングして変更します。 + 列名の再マッピングを追加をクリックし、入力列名を予測出力で指定された出力列名に置き換えるように定義します。 列名マッピングの追加を間違えた場合は、削除アイコン をクリックして削除できます。 |
予測の説明を有効にできないのはなぜですか?
予測の説明を含めることができない場合、次の理由が考えられます。
-
モデルの検定パーティションに、必要な行数が含まれていません。
-
統合されたモデルで、少なくとも1つのセグメントチャンピオンの検定パーティションに、必要な行数が含まれていません。 予測の説明を有効にするには、モデルパッケージやデプロイを作成する前に、再トレーニングしたチャンピオンを手動で置き換えてください。
チャンクサイズとは?
バッチ予測プロセスでは、データが小さな断片に分割され、それらの断片が1つずつスコアリングされるため、DataRobotは大量のバッチをスコアリングできます。 チャンクサイズの設定では、DataRobotがデータをチャンク化するために使用する方法を決定します。 DataRobotは、全体的に最もパフォーマンスが高いデフォルト設定の自動チャンク化をお勧めしますが、他のオプションも利用できます。
-
固定:DataRobotは、最初に有効なチャンクサイズを識別し、モデルのスコアリングプロセスの残りの部分でそのサイズを引き続き使用します。
-
動的:DataRobotは、モデルのスコアリング速度が許容範囲内である間はチャンクサイズを大きくし、スコアリング速度が低下するとチャンクサイズを小さくします。
-
カスタム:データサイエンティストがチャンクサイズを設定すると、DataRobotは残りのモデルスコアリングプロセスでそのチャンクサイズを使用し続けます。
時系列オプションの設定¶
時系列データ要件
時系列モデルで予測を作成するには、特定の形式のデータセットが必要です。 形式は時系列プロジェクトの設定に基づきます。 予測データセットに正しい履歴行、予測行、および事前に既知の特徴量が含まれていることを確認します。 さらに、DataRobotが時系列データを確実に処理できるようにするには、次の要件を満たすようにデータセットを設定してください。
- 予測行をタイムスタンプでソートします。最も古い行が最初に表示されます。
- 複数系列では、予測行を系列IDでソートし、さらにタイムスタンプでソートして、古い順に表示します。
DataRobotがサポートする系列の数には制限はありません。 制限に記載されているように、唯一の制限はジョブのタイムアウトです。 データセットの例については、スコアリングデータセットの要件をご覧ください。
時系列オプションの時系列予測法を設定するには、 予測ポイントまたは予測範囲を選択します。
予測ポイント オプションで、予測を開始する特定の日付を選択し、予測ポイントで選択方法を定義します。
-
自動的に設定、DataRobotはスコアリングデータに基づいて予測ポイントを選択します。

-
相対:ジョブ時間からのオフセットで、スケジュールされたジョブの実行時間からオフセットする月、日、時間、分の数を設定して、予測ポイントを設定します。 オフセットの適用方法に応じて、ジョブの時間前またはジョブの時間後をクリックします。

-
手動で設定:日付セレクターを使用して開始および終了の日付を手動で指定し、特定の日付範囲を設定します。

(予測ポイントから将来の行を予測するのではなく)一括で過去の予測を行う場合は、予測範囲 オプションを選択し、予測範囲の選択で、選択方法を定義します。
-
自動、予測は選択した時間範囲内のすべての予測距離を使用します。
-
手動:日付セレクターを使用して開始および終了の日付を手動で指定し、特定の日付範囲を設定します。

さらに、高度なオプションを表示をクリックし、事前に既知の列の欠損値を無視するを有効にすると、指定されたソースデータセットの事前に既知の列で欠損値があっても、予測を行うことができます。ただし、これは計算された予測に悪影響を及ぼす可能性があります。
予測先の設定¶
予測先(別名出力アダプター)を選択します。

次に、宛先タイプに応じた適切な認証ワークフローを完了させます。
さらに、詳細オプションを表示をクリックして、定期的に結果をコミットすることもできます。この場合、カスタムコミット間隔を定義して、データの宛先への書き込み操作をコミットする頻度を指定します。
宛先の接続タイプ¶
以下の接続タイプを選択すると、フィールドの説明が表示されます。
備考
接続の参照時に無効なアダプターは表示されません。
データベース接続
クラウドストレージ接続
- Azure
- Google Cloud Storage(GCP Cloud)
- S3
データウェアハウス接続
その他
予測ジョブのスケジュール¶
予測ジョブは、スケジュールに従って自動的に実行されるように設定することができます。 ジョブ定義を作成する際に、ジョブスケジュールをオンに切り替えます。 頻度(毎日、毎時、毎月など)と時間帯を指定して、ジョブの実行スケジュールを定義します。
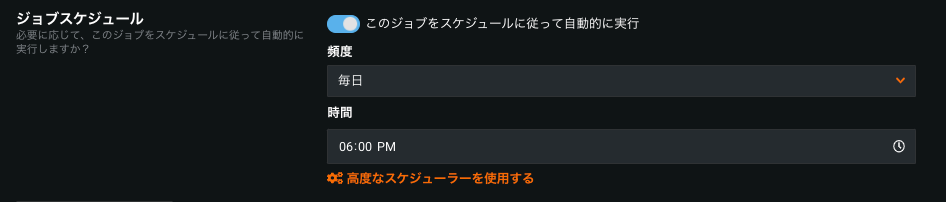
さらに詳細な指定をする場合は、高度なスケジューラーを使用するを選択します。 予測ジョブの実行時刻を分単位で正確に指定することができます。

適切なオプションをすべて設定したら、予測ジョブ定義を保存をクリックします。