カスタムモデルの作成¶
カスタムモデルは、ユーザーが作成して、モデルワークショップを介して(ファイルのコレクションとして)、DataRobotにアップロードできる事前トレーニング済みのモデルです。 カスタムモデルは、以下のうちいずれかの方法で構築できます。
-
アセンブルタブで、環境要件と
start_server.shファイル なし でカスタムモデルを作成します。 このタイプのカスタムモデルはドロップイン環境を使用する必要があります。 ドロップイン環境には、モデルで使用される要件とstart_server.shファイルが含まれます。 これらはワークショップ内のDataRobotによって提供されます。 -
アセンブルタブで、環境要件と
start_server.shファイル あり でカスタムモデルを作成します。 このタイプのカスタムモデルは、カスタムまたはドロップイン環境と組み合わせることができます。
作業を続ける前に、 カスタムモデルの構築に関するガイドラインを確認してください。 カスタムモデルと環境フォルダーの間でファイルが重複している場合は、モデルのファイルが優先されます。
カスタムモデルのテスト
カスタムモデルのファイルコンテンツを組み立てると、DataRobotにアップロードする前に開発目的でローカルでコンテンツをテストできます。 ワークショップでカスタムモデルを作成した後、テストタブからテストスイートを実行できます。
新しいカスタムモデルの作成¶
構築の準備としてカスタムモデルを作成するには:
-
レジストリ > モデルワークショップをクリックします。 このタブには、作成したモデルが一覧表示されます。
-
+ モデルを追加(または、カスタムモデルパネルが開いている場合は ボタン)をクリックします。
-
モデルを追加ページで、モデルを設定のフィールドに入力します。
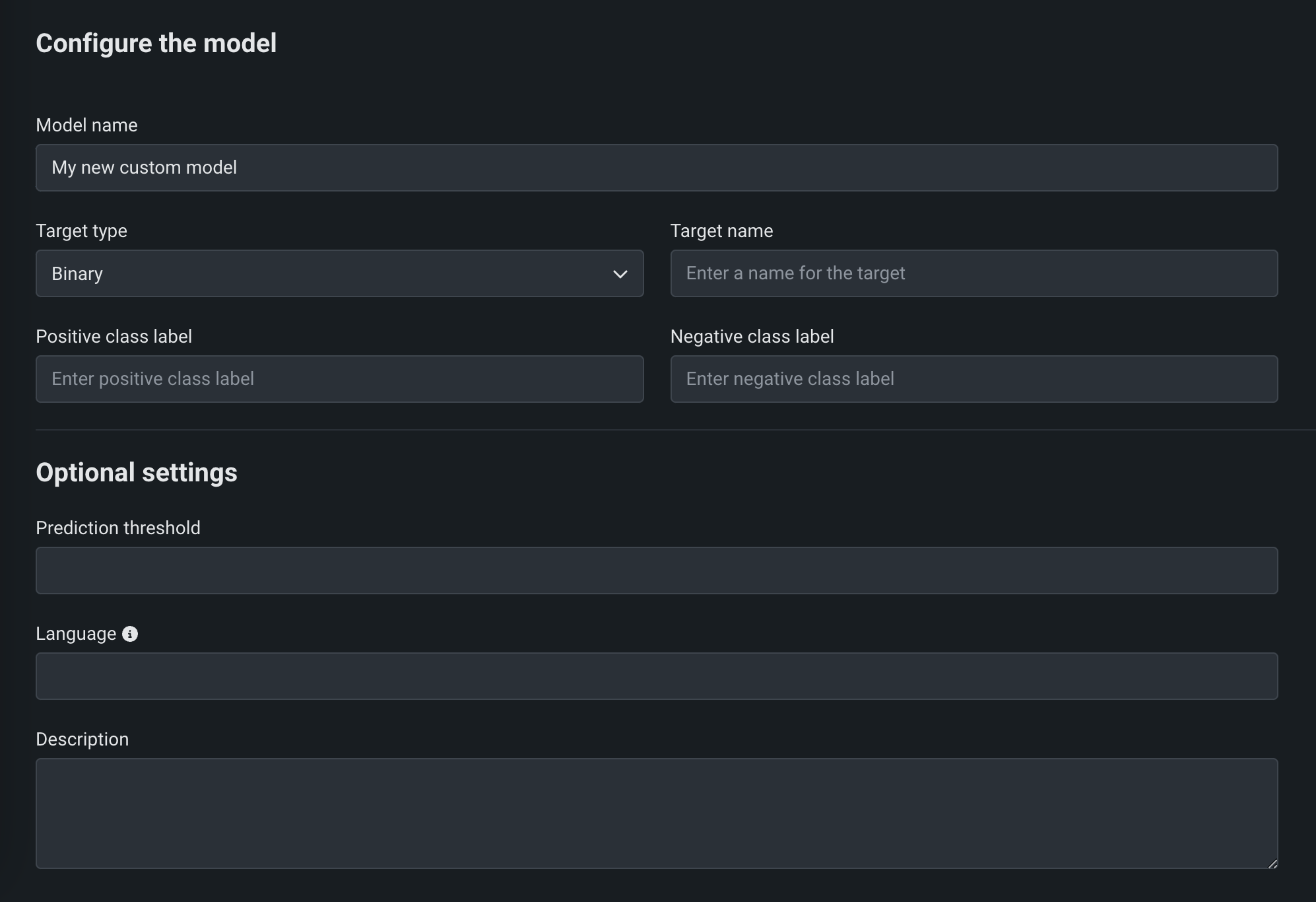
フィールド 説明 モデル名 カスタムモデルのわかりやすい名前。 ターゲットタイプ モデルが行っている予測のタイプ。 Depending on the prediction type, you must configure additional settings: - Binary: For a binary classification model, enter the Positive class label and the Negative class label.
- Regression: No additional settings.
- Time Series (Binary): Preview feature. For a binary classification model, enter the Positive class label and the Negative class label and configure the time series settings.
- Time Series (Regression): Preview feature. Configure the time series settings.
- Multiclass: For a multiclass classification model, enter or upload (
.csv,.txt) the Target classes for your target, one class per line. クラスがモデルの予測に正しく適用されるように、モデルが予測したクラスの確率と同じ順序でクラスを入力してください。 - テキスト生成:プレミアム機能。 No additional settings.
- Anomaly Detection: No additional settings.
- Unstructured: No additional settings. 非構造化モデルは、特定の入力/出力スキーマに準拠する必要はなく、異なる要求形式を使用する可能性があります。 「非構造化」ターゲットタイプのデプロイでは、予測ドリフト、精度追跡、チャレンジャー、および信頼性が無効になります。 サービスの正常性、デプロイアクティビティ、ガバナンスは引き続き利用できます。
ターゲット名 モデルが予測するデータセットの列名。 このフィールドは、多クラスモデルおよび異常検知モデルでは使用できません。 高度な設定 言語 モデルの構築に使用されるプログラミング言語。 説明 モデルのコンテンツと目的の説明。 -
フィールドに入力したら、モデルを追加をクリックします。
カスタムモデルがアセンブルタブで開きます。
Configure time series settings¶
本機能の提供について
Time series custom models are off by default. この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
Feature flag: Enable Time Series Custom Models, Enable Feature Filtering for Custom Model Predictions
You can create time series custom models by configuring the following time series-specific fields, in addition to the fields required for binary classification and regression models. To create a time series custom model, select Time Series (Binary) or a Time Series (Regression) as a Target type, and configure the following settings while creating the model:
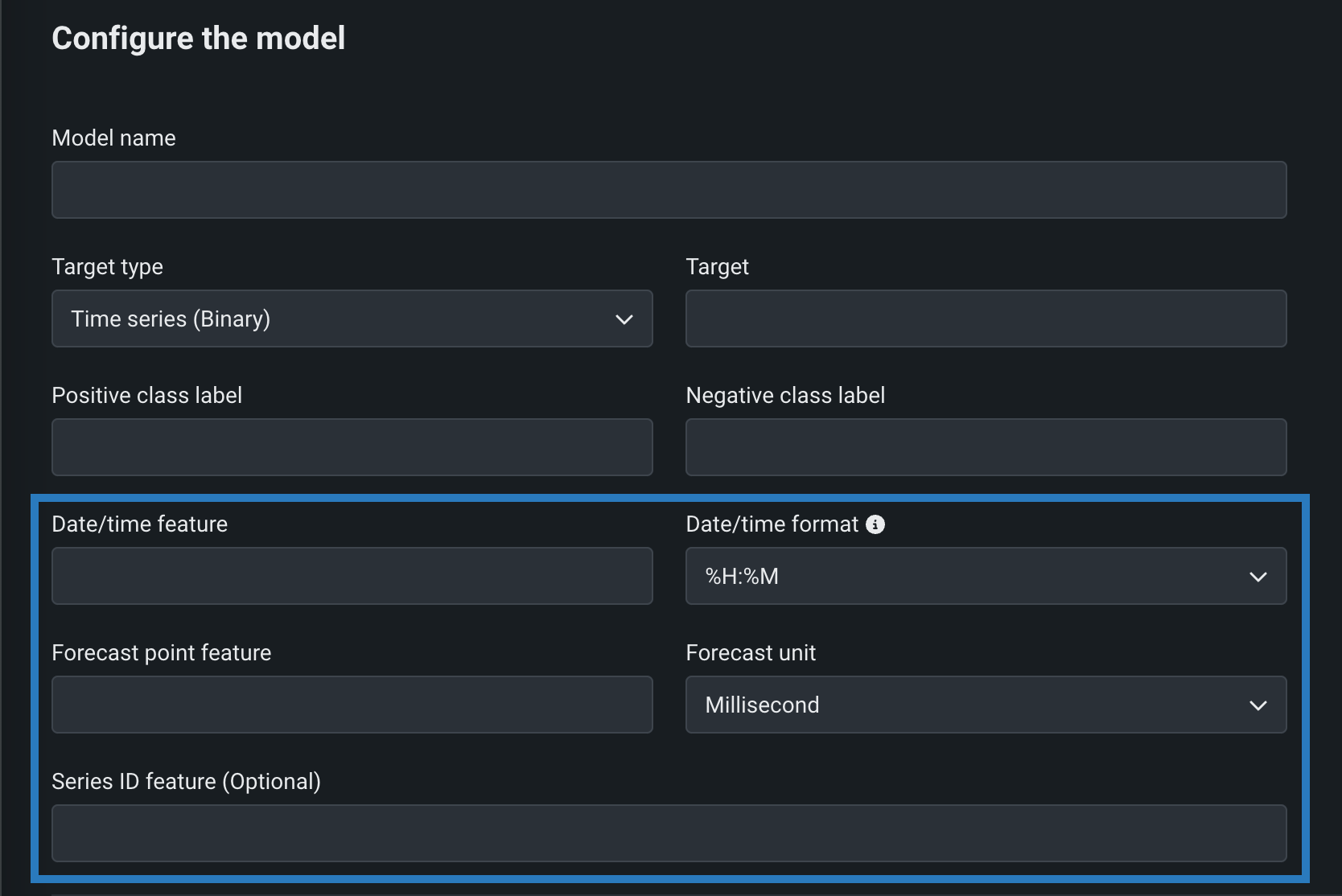
| フィールド | 説明 |
|---|---|
| 日付/時刻特徴量 | The column in the training dataset that contains date/time values of the given prediction row. |
| 日付/時刻形式 | The format of the values in both the date/time feature column and the forecast point feature column, provided as a drop-down list of all possible values in GNU C library format. |
| 予測ポイントの特徴量 | The column in the training dataset that contains the point from which you are making a prediction. |
| 予測単位 | The time unit (seconds, days, months, etc.) that the time step uses, provided as a drop-down list of all possible values. |
| 系列ID特徴量 | Optional. For multiseries models, the column in the training dataset that identifies which series each row belongs to. |
When you make real-time predictions with a time series custom model, in the CSV serialization of the prediction response, any extra columns (beyond the prediction results) returned from the model have a column name suffixed with _OUTPUT.
Considerations for time series custom models
Time series custom models:
-
Cannot be selected as challengers.
-
Only support the model startup test during custom model testing.
-
Support real-time predictions, not batch predictions.
-
Do not support the portable prediction server (PPS).
Configure an anomaly detection model¶
異常検知の問題をサポートするカスタムモデルを作成できます。 構築する場合は、DRUMテンプレートを参照してください。 (このリンクをクリックする前にGitHubにログインしてください。)カスタム異常検知モデルをデプロイする場合、次の機能はサポートされていないことに注意してください。
- データドリフト
- 精度と関連付けID
- チャレンジャーモデル
- 信頼性ルール
- 予測の説明
カスタムモデルの構築¶
カスタムモデルを作成した後、必要な環境、依存関係、ファイルを指定できます。
-
構築するモデルで、アセンブルタブの環境セクションに移動し、基本環境ドロップダウンメニューからモデル環境を選択します。
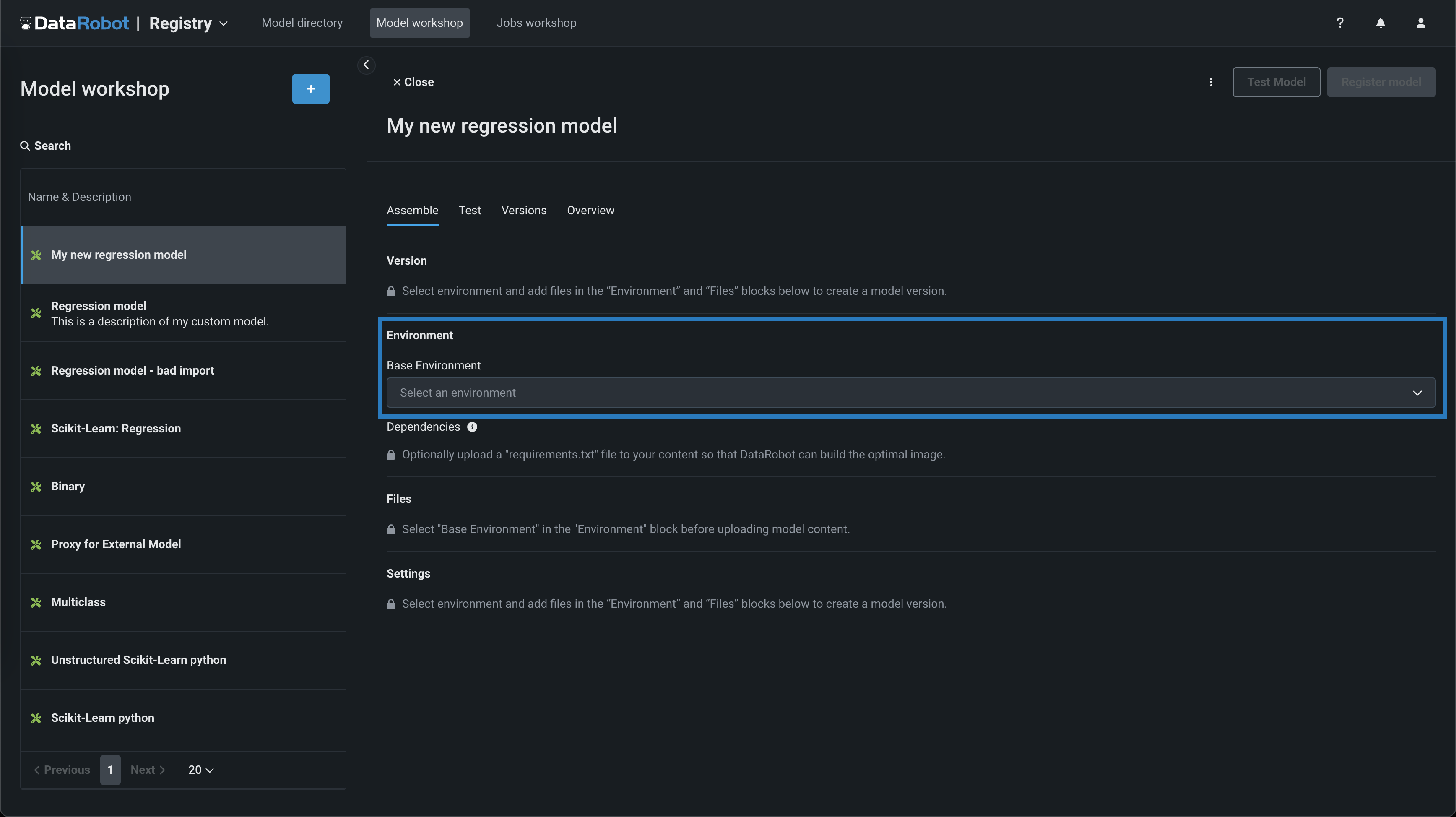
モデル環境
モデル環境は、カスタムモデルのテストとデプロイに使用されます。 基本環境ドロップダウンリストには、 ドロップインモデル環境と、作成可能な カスタム環境が含まれています。
-
依存関係セクションに入力するために、ファイルセクションで
requirements.txtファイルをアップロードし、DataRobotが最適なイメージを構築できるようにします。 -
ファイルセクションで、必要なカスタムモデルファイルを追加します。 モデルと ドロップイン環境をペアリングしていない場合、これにはカスタムモデル環境要件と
start_server.shファイルが含まれます。 ファイルの追加方法はいくつかあります。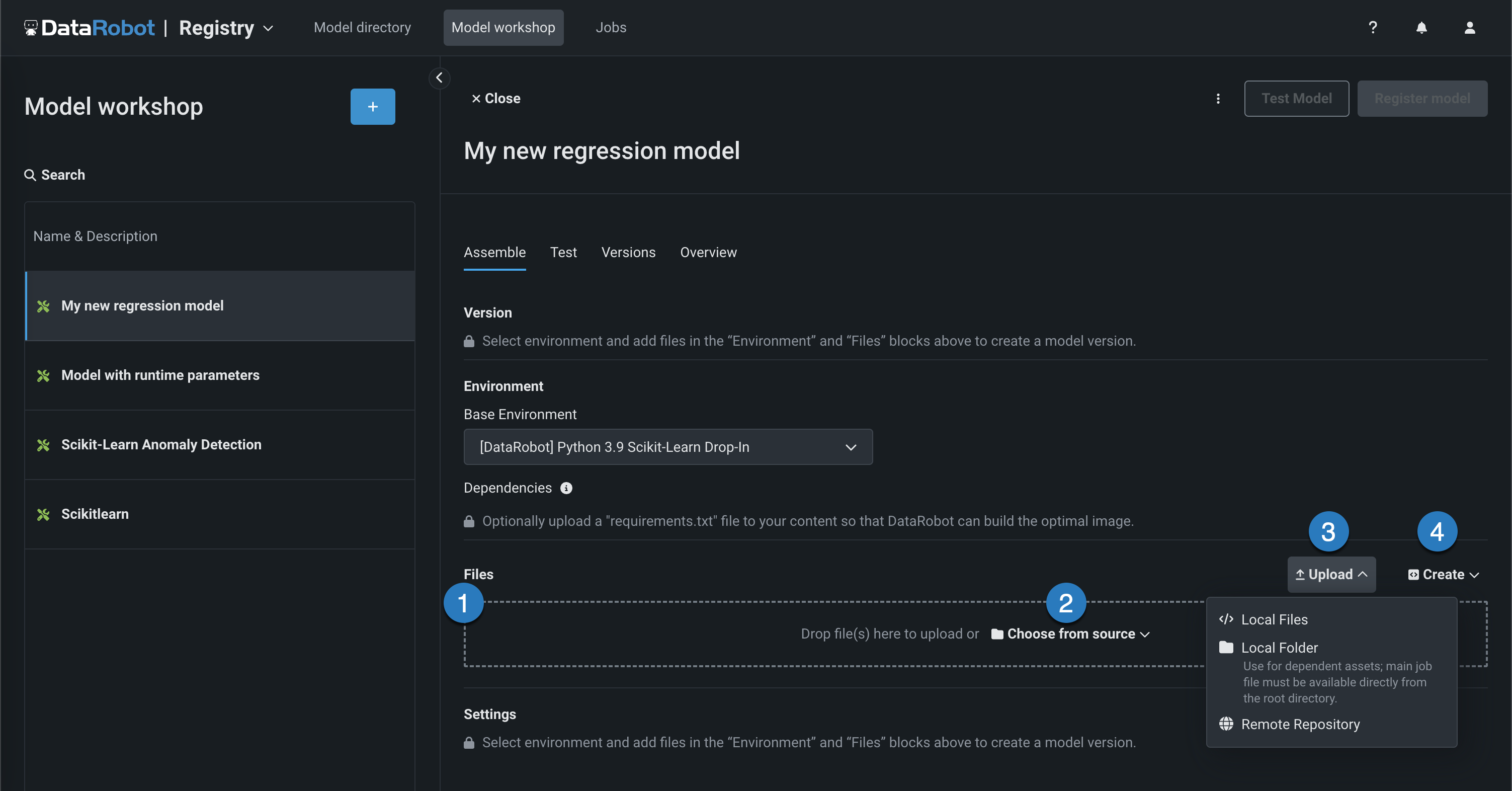
要素 説明 1 ファイル ファイルをグループボックスにドラッグしてアップロードします。 2 ソースから選択 クリックしてローカルファイルまたはローカルフォルダーを参照します。 3 アップロード クリックしてローカルファイルまたはローカルフォルダーを参照するか、 リモートリポジトリからファイルをプルします。 4 作成 空のファイルまたはテンプレートとして新しいファイルを作成し、カスタムモデルに保存します。 - model-metadata.yamlを作成:ランタイムパラメーターファイルの基本的で編集可能な例を作成します。
- 空白ファイルを作成:空のファイルを作成します。 名称未設定の横にある編集アイコン()をクリックしてファイル名と拡張子を入力し、カスタムコンテンツを追加します。
ファイルの置き換え
既存のファイルと同じ名前の新しいファイルを追加する場合、保存をクリックすると、ファイルセクションで古いファイルが置き換えられます。
モデルファイルの場所
ローカルフォルダーからファイルを追加する場合は、モデルファイルがすでにカスタムモデルのルートにあることを確認してください。 アップロードされたフォルダーは、モデル自体ではなく、モデルに必要な依存ファイルおよび追加のアセット用です。 モデルファイルがフォルダーに含まれている場合でも、ファイルがルートレベルに存在しない限り、DataRobotからモデルファイルにアクセスすることはできません。 ルートにあるファイルは、フォルダー内の依存関係を指定することができます。
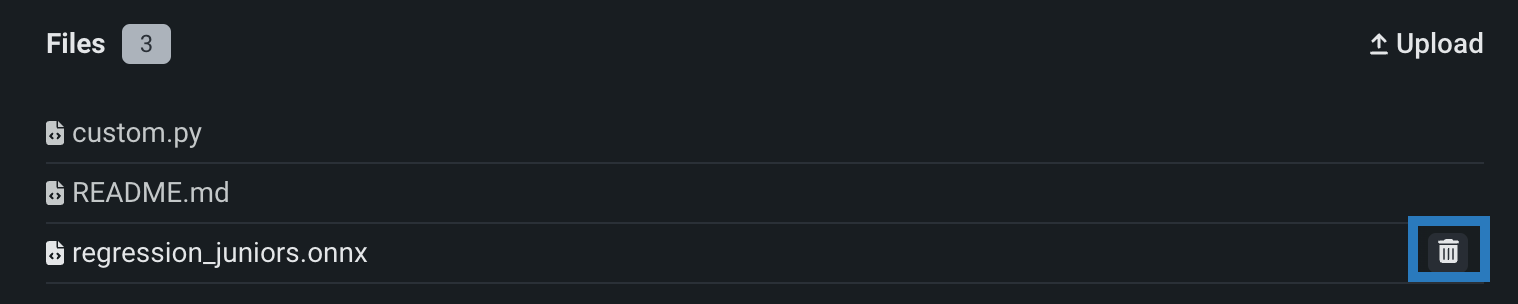
アセンブルタブのファイルセクションで1つ以上のファイルまたはフォルダーを誤って追加した場合は、各ファイルまたはフォルダーの横にある削除()アイコンをクリックして、カスタムモデルから削除できます。
リモートリポジトリ¶
ファイルセクションで、アップロード > リモートリポジトリをクリックすると、リモートリポジトリからコンテンツを追加パネルが開きます。 リモートリポジトリをクリックして、 新しいリモートリポジトリを登録(A)するか、既存のリモートリポジトリを選択(B)できます。
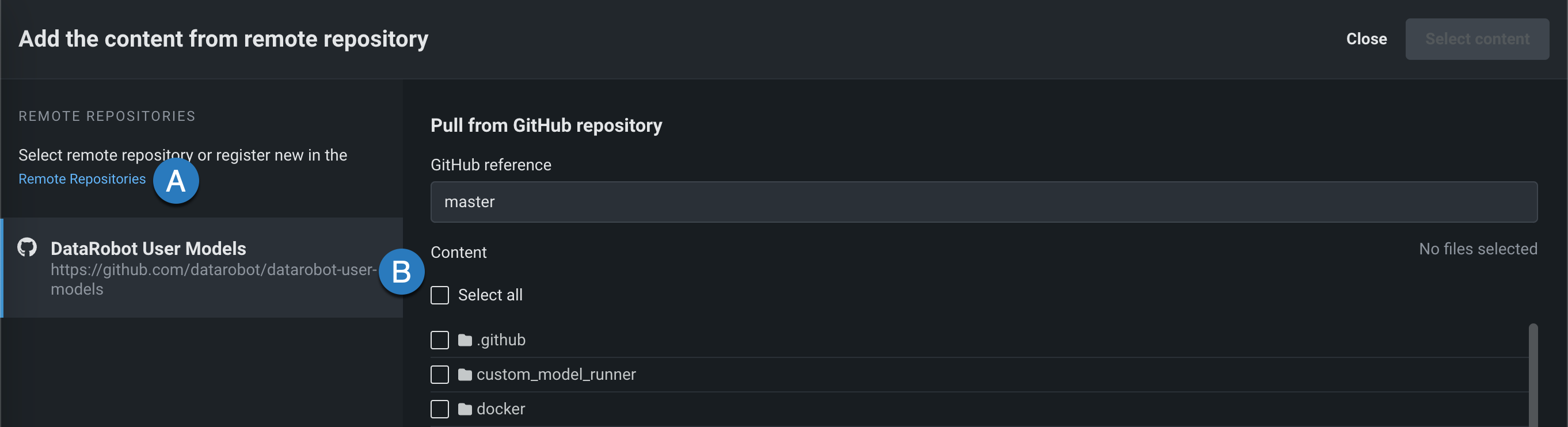
リポジトリを登録して選択した後、アップロードする各ファイルまたはフォルダーのチェックボックスを選択して、コンテンツを選択するをクリックします。
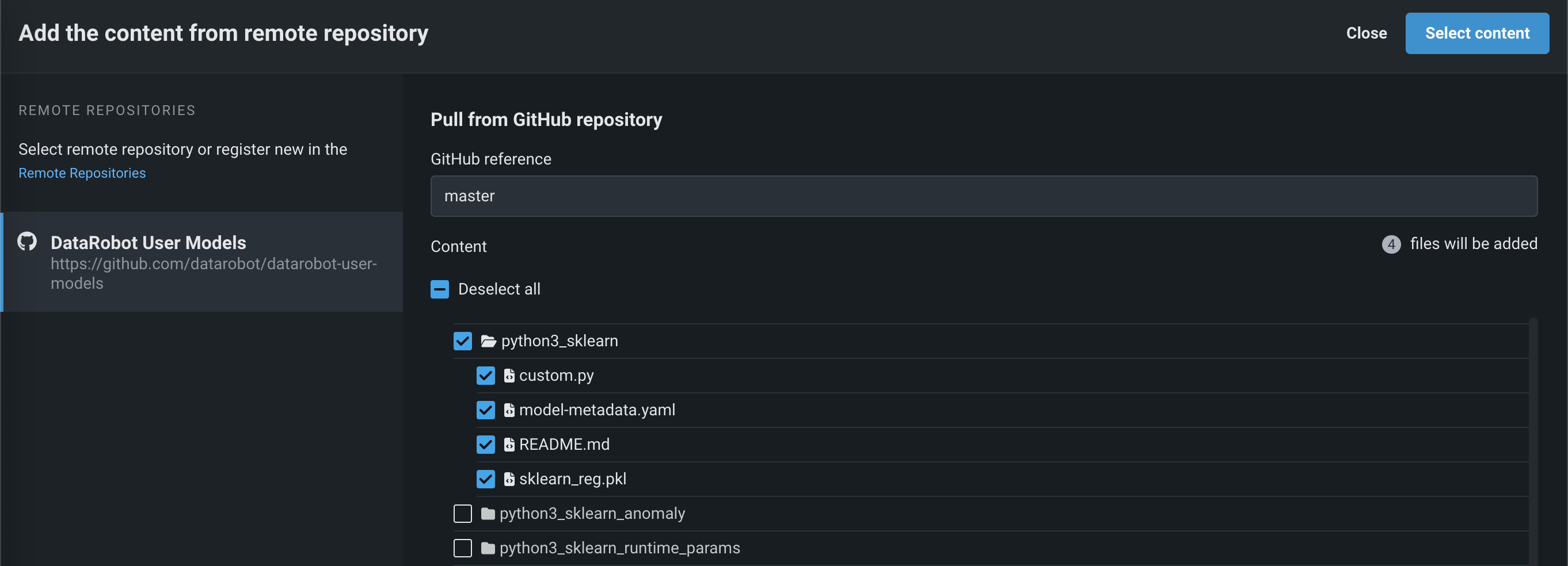
選択したファイルがファイルセクションに入れられます。
ドロップイン環境¶
DataRobotでは、モデルワークショップでドロップイン環境が使用でき、必要なライブラリを定義してstart_server.shファイルが使用できます。 次の表に、DataRobotのドロップイン環境の詳細とDRUMリポジトリ内のテンプレートへのリンクを示します。 モデルワークショップのアセンブルタブの環境セクションでは各環境の前に[DataRobot]が置かれます。
| 環境名と例 | モデルの互換性とアーティファクトファイルの拡張子 |
|---|---|
| Python 3 ONNXドロップイン | ONNXモデル(.onnx) |
| Python 3 PMMLドロップイン | PMMLモデル(.pmml) |
| Python 3 PyTorchドロップイン | PyTorchモデル(.pth) |
| Python 3 Scikit-Learnドロップイン | Scikit-Learnモデル(.pkl) |
| Python 3 XGBoostドロップイン | ネイティブXGBoostモデル(.pkl) |
| Python 3 Kerasドロップイン | TensorFlow(.h5)を用いたKerasモデル |
| Javaドロップイン | DataRobotスコアリングコードモデル(.jar) |
| Rドロップイン環境 | CARET(.rds)を使ってトレーニングされたRモデルCARETが推奨するすべてのライブラリをインストールするのに時間がかかるため、パッケージ名でもあるモデルタイプのみがインストールされます(例: brnn、glmnet)。 この環境のコピーを作成し、Dockerfileを修正して、必要なパッケージを追加でインストールします。 この環境をカスタマイズする際のビルド回数を減らすために、# Install caret modelsセクションで不要な行を削除して、必要なものだけをインストールすることもできます。 CARETドキュメントを参照して、モデルの手法がパッケージ名と一致しているかどうかを確認してください。 このリンクをクリックする前にGitHubにログインしてください。 |
| Juliaドロップイン* | Juliaモデル(.jlso)* Juliaのドロップイン環境は公式にはサポートされていません。例として提供されています。 |
備考
すべてのPython環境には、前処理(必要な場合)を支援するScikit-Learnが含まれていますが、sklearnモデルで予測を作成できるのはScikit-Learnだけです。
ドロップイン環境を使用する場合、カスタムモデルコードは、 DataRobotクライアントと MLOps Connected Clientへのアクセスを容易にするために挿入された複数の環境変数を参照できます。
| 環境変数 | 説明 |
|---|---|
MLOPS_DEPLOYMENT_ID |
カスタムモデルがデプロイモードで実行されている場合(カスタムモデルがデプロイされている場合)、デプロイIDを使用できます。 |
DATAROBOT_ENDPOINT |
カスタムモデルに パブリックネットワークアクセスがある場合、DataRobotエンドポイントURLを使用できます。 |
DATAROBOT_API_TOKEN |
カスタムモデルに パブリックネットワークアクセスがある場合、DataRobot APIトークンを使用できます。 |
評価とモデレーションを設定¶
本機能の提供について
Evaluation and moderation guardrails are off by default. この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
Feature flag: Enable Moderation Guardrails, Enable Global Models in the Model Registry (Premium), Enable Additional Custom Model Output in Prediction Responses
Evaluation and moderation guardrails help your organization block prompt injection and hateful, toxic, or inappropriate prompts and responses. It can also prevent hallucinations or low-confidence responses and, more generally, keep the model on topic. In addition, these guardrails can safeguard against the sharing of personally identifiable information (PII). Many evaluation and moderation guardrails connect a deployed text generation model (LLM) to a deployed guard model. These guard models make predictions on LLM prompts and responses and report these predictions and statistics to the central LLM deployment. To use evaluation and moderation guardrails, first, create and deploy guard models to make predictions on an LLM's prompts or responses; for example, a guard model could identify prompt injection or toxic responses. Then, when you create a custom model with the Text Generation target type, define one or more evaluation and moderation guardrails.
To select and configure evaluation and moderation guardrails, on the Assemble tab for a custom model with the Text Generation target type, scroll to Evaluation and Moderation and click Configure:
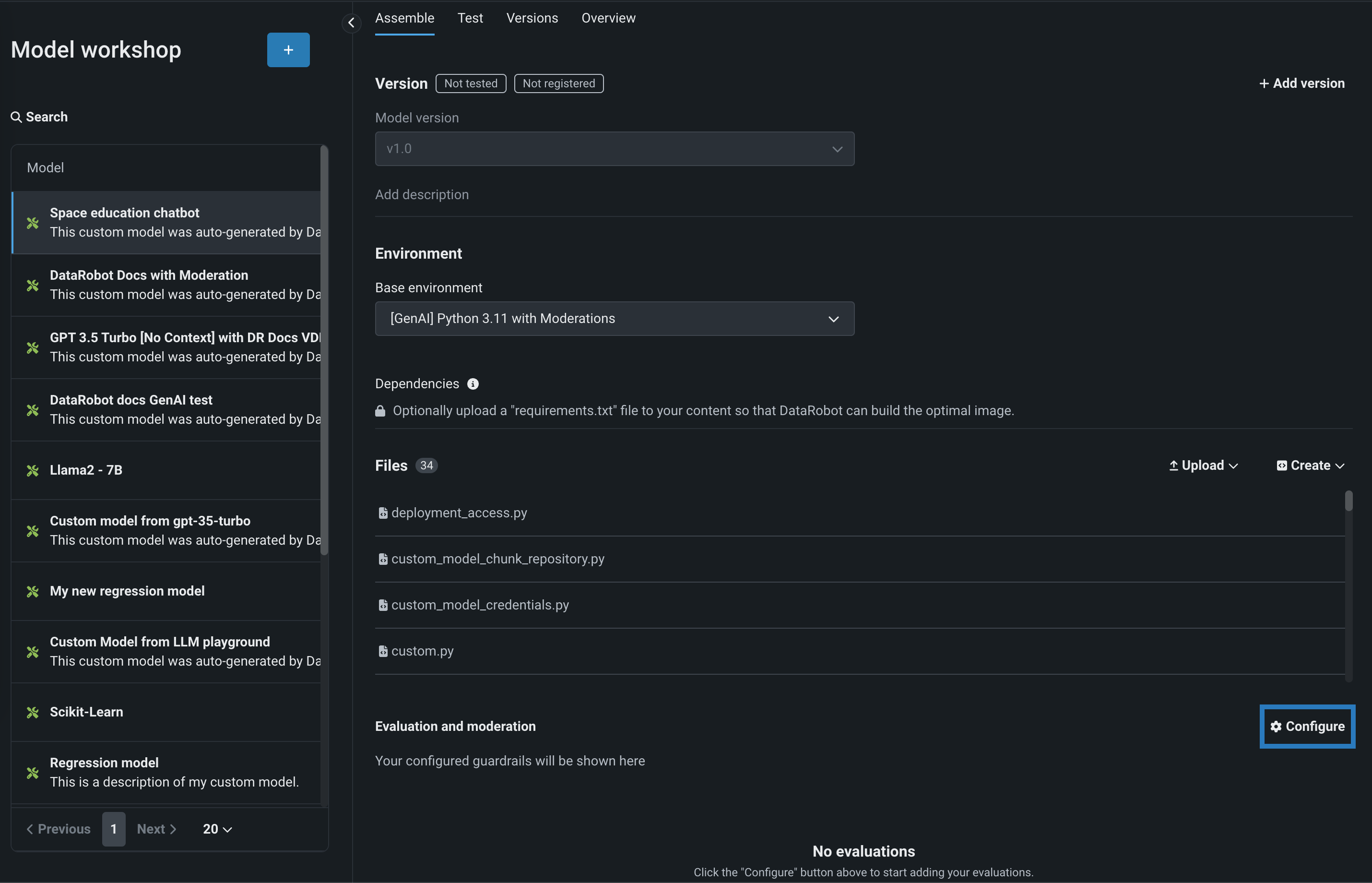
In the Configure evaluation and moderation panel, click a metric card, configure the required properties, and then click Add to return the the Evaluation tab:
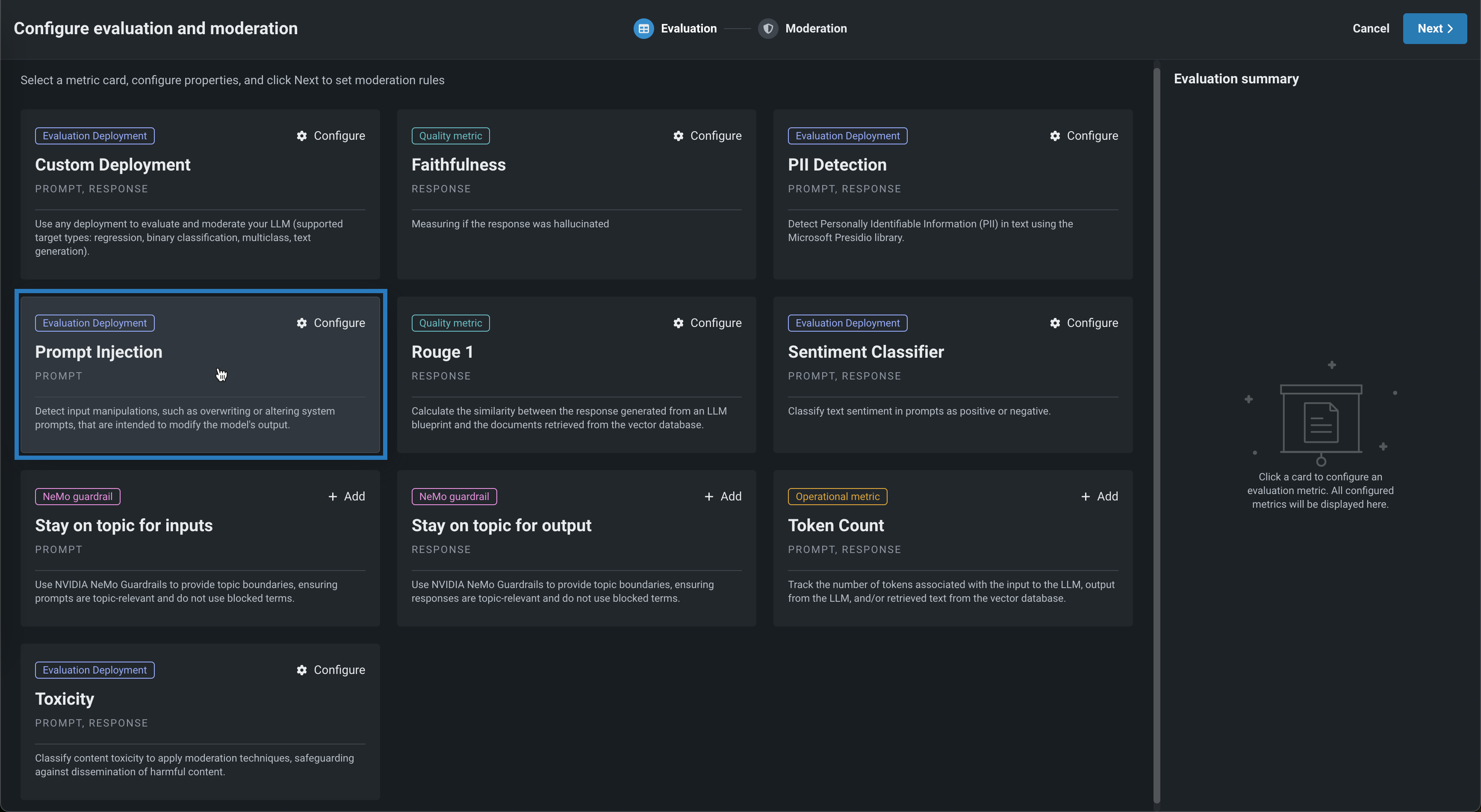
Select another metric or click Next to proceed to the Moderation tab to configure a Moderation strategy:
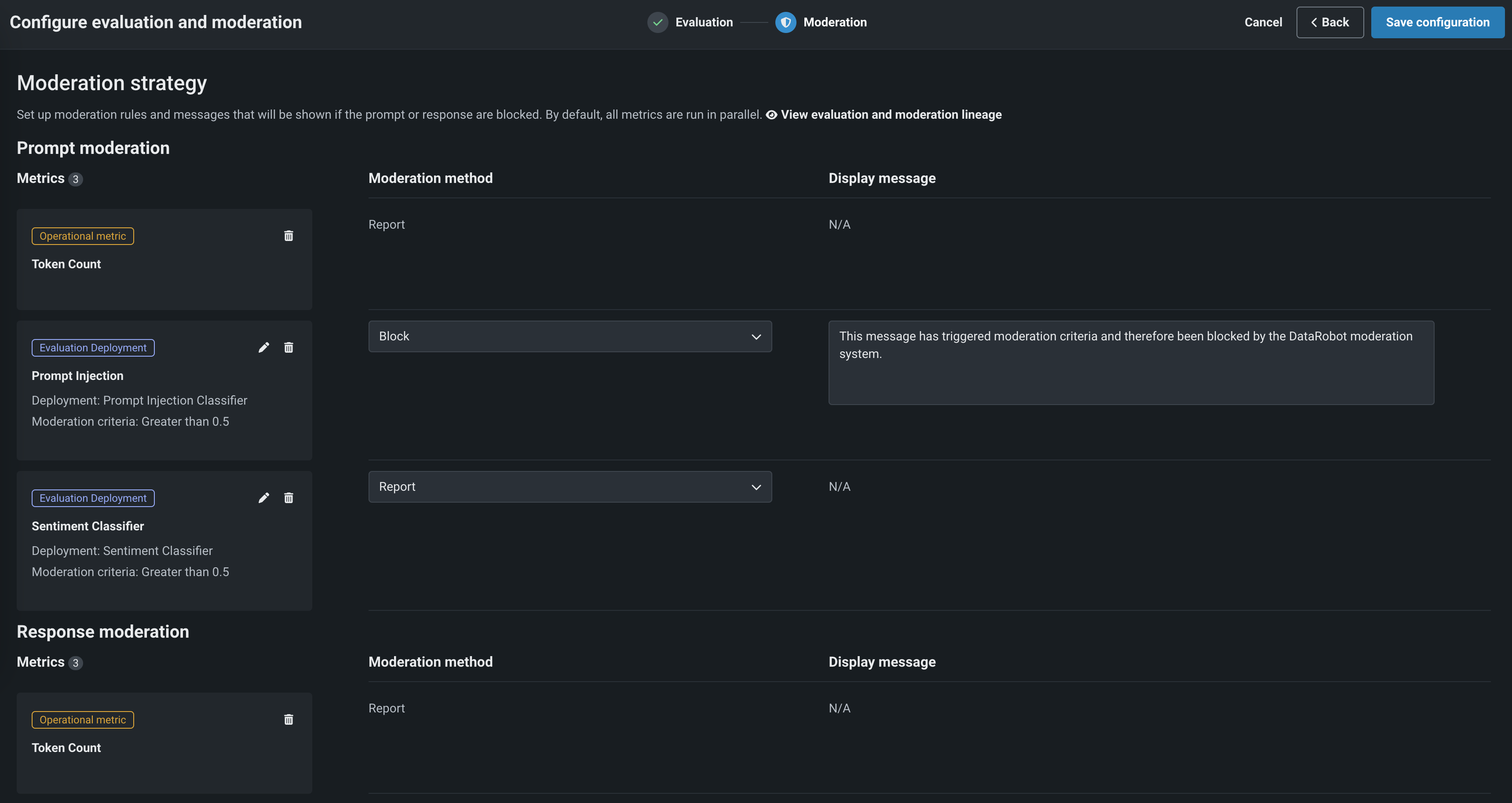
After adding guardrails to a text generation custom model, you can test, register, and deploy the model to make predictions in production. After you make predictions, you can view the evaluation metrics on the Custom metrics tab and prompts, responses, and feedback (if configured) on the Data exploration tab.
For more information, see Configure evaluation and moderation.
接続されたデプロイを定義¶
本機能の提供について
接続されたデプロイは、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:デプロイの接続を有効にする
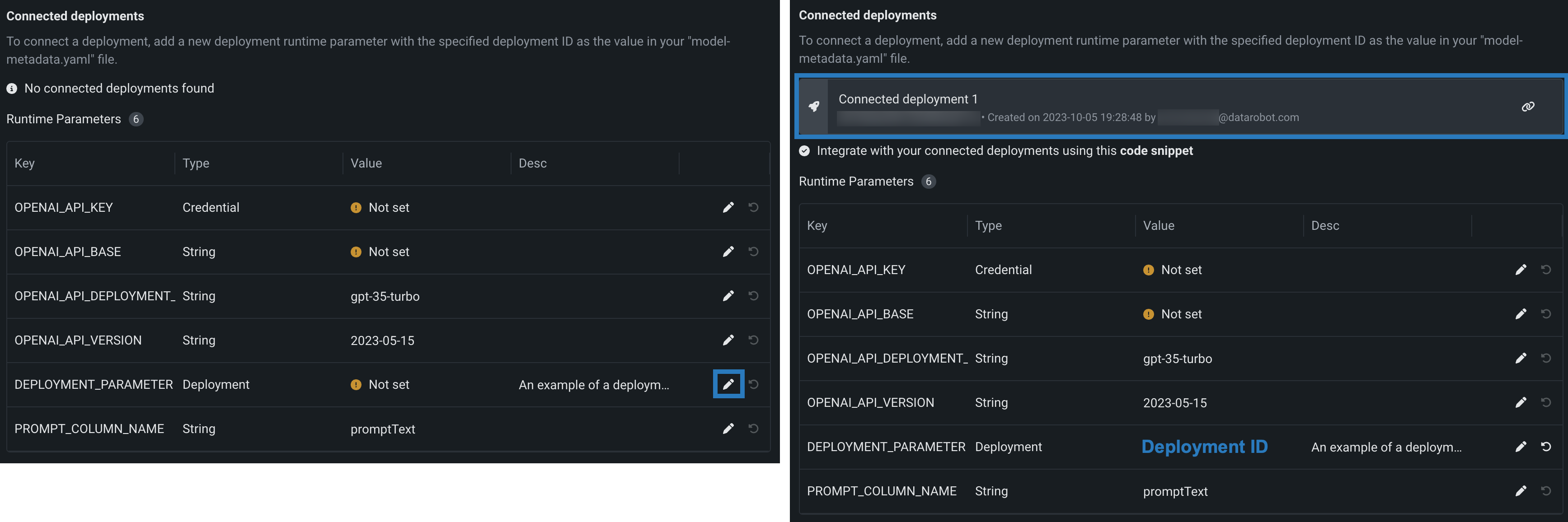
接続されたデプロイは、監視対象のテキスト生成モデルデプロイに予測と統計を報告します。 接続されたデプロイを使用するには、最初に、LLMのプロンプトや出力について予測を行う監査モデルを作成してデプロイします。たとえば、監査モデルでプロンプトインジェクション、つまり有害な回答を識別できる場合があります。 次に、テキスト生成ターゲットタイプでカスタムモデルを作成するときに、接続された1つまたは複数のデプロイを定義して予測を生成し、中央モデルにレポートします。 接続されたデプロイの予測は、監視対象のテキスト生成モデルデプロイの予測出力に統合することができます。
接続されたデプロイを定義するには、deploymentタイプのランタイムパラメーターを1つ以上含むmodel-metadata.yamlファイルをアップロードするか作成します。 作成 > model-metadata.yamlを作成をクリックすると、テンプレートに例が含まれるようになります。
runtimeParameterDefinitions:
- fieldName: DEPLOYMENT_PARAMETER
type: deployment
description: An example of a deployment parameter (for various purposes, such as connected deployments)
defaultValue: null
上の例でnullを接続するデプロイのデプロイIDに置き換えるか、model-metadata.yamlファイルの保存後に編集アイコン()をクリックしてデプロイIDを入力します。
接続されたデプロイを使用するには、カスタムモデルにテキスト生成ターゲットタイプがあることを確認します。 ターゲットタイプは、次のようにmodel-metadata.yamlファイルで定義できます。
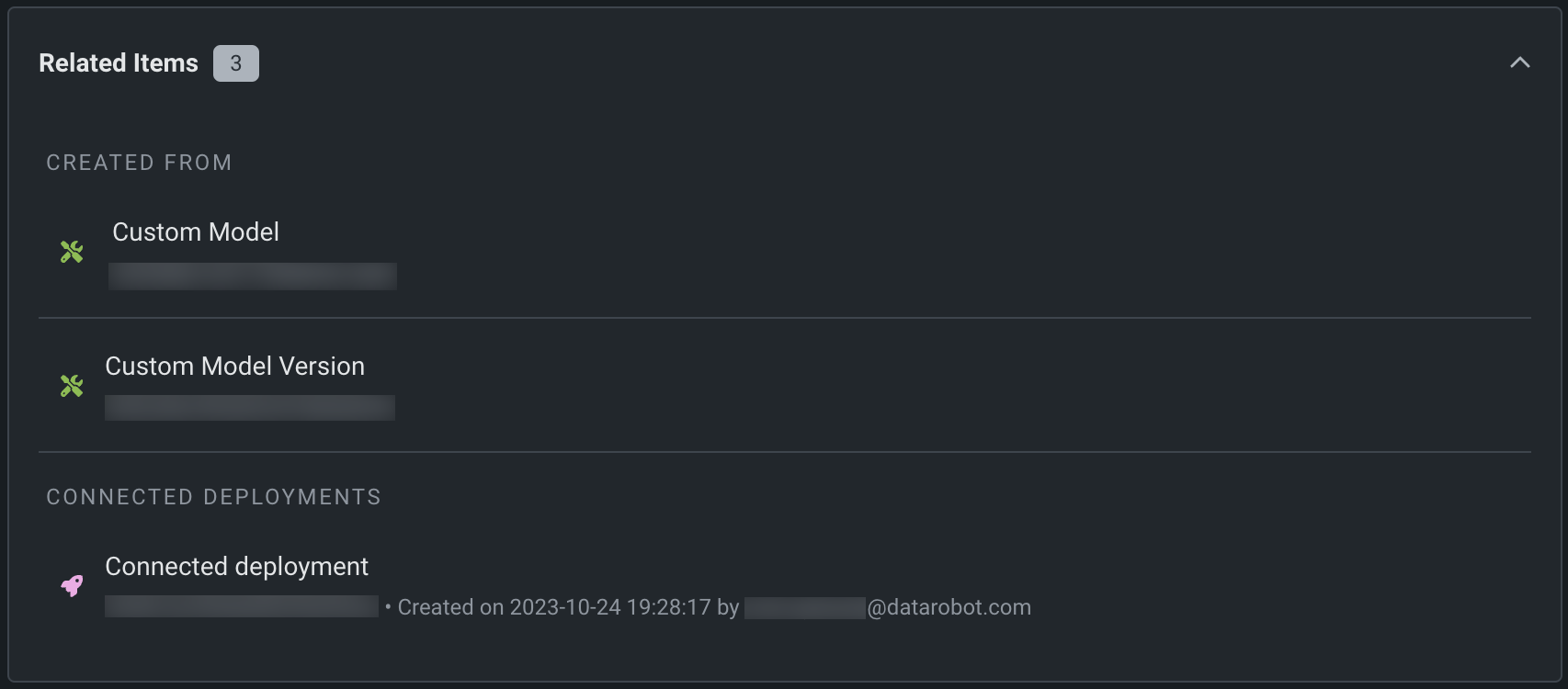
targetType: textgeneration
カスタムモデルの構築と登録を行うと、登録モデルバージョンの関連アイテムセクションで接続されたデプロイを確認できます。
ランタイムパラメーターの管理¶
model-metadata.yamlファイルのruntimeParameterDefinitionsによりランタイムパラメーターを定義した場合、ランタイムパラメーターセクションでそれらを管理できます。
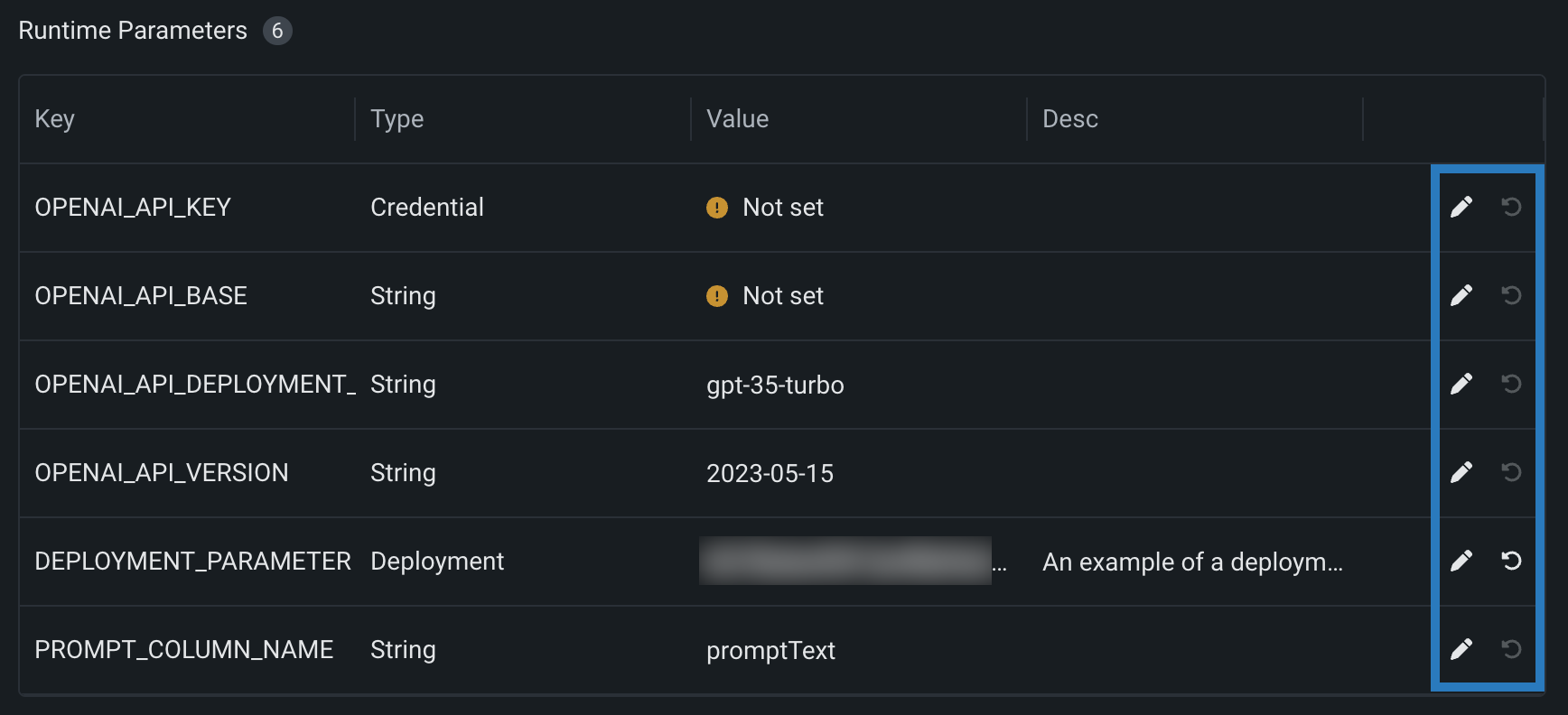
| アイコン | 設定 | 説明 |
|---|---|---|
| 編集 | キーを編集ダイアログボックスを開き、ランタイムパラメーターの値を編集します。 | |
| 初期値に戻す | ランタイムパラメーターの値をmodel-metadata.yamlファイル内のdefaultValueセットにリセットします。 |
defaultValueのない定義で、ランタイムパラメーターにallowEmpty: falseがある場合は、カスタムモデルを登録する前に値を設定する必要があります。
For more information on how to define runtime parameters and use them in your custom model code, see the Define custom mode runtime parameters documentation.
カスタムモデルデータセットの割り当て¶
モデルデプロイで特徴量ドリフト追跡を有効にするには、トレーニングデータを追加する必要があります。 これを行うには、モデルのバージョンにトレーニングデータを割り当てます。 非構造化カスタム推論モデルのトレーニングデータセットとホールドアウトデータセットを指定する方法では、トレーニングデータセットとホールドアウトデータセットを個別にアップロードする必要があります。 さらに、これらのデータセットにはパーティション列を含めることはできません。
ファイルサイズに関する注意
The file size limit for custom model training data uploaded to DataRobot is 1.5GB.
環境とファイルを定義した後にカスタムモデルにトレーニングデータを割り当てるには:
-
アセンブルタブの設定セクションのデータセットの下:
-
モデルのバージョンにトレーニングデータが割り当てられていない場合は、割り当てるをクリックします。
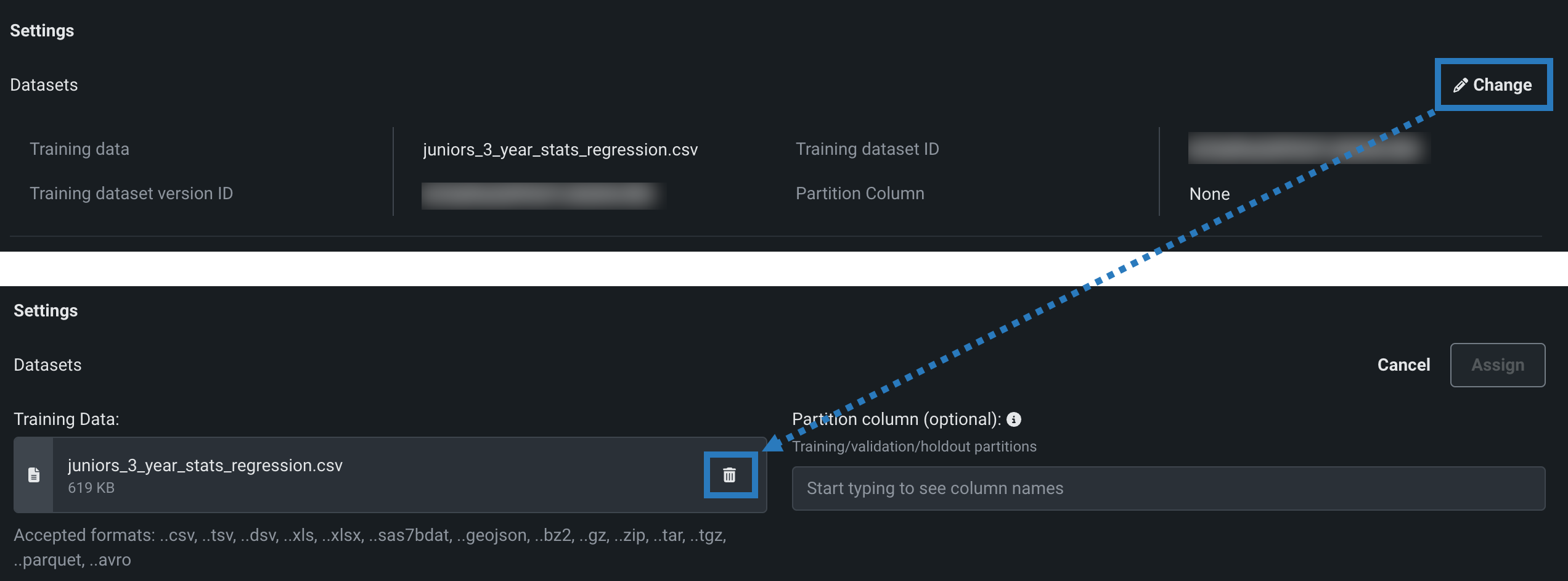
-
モデルバージョンにトレーニングデータが 割り当てられている 場合は、()変更をクリックし、トレーニングデータの下で削除()アイコンをクリックして、既存のトレーニングデータを削除します。
-
-
トレーニングデータセクションで、+ データセットを選択をクリックして、次のいずれかを実行します。
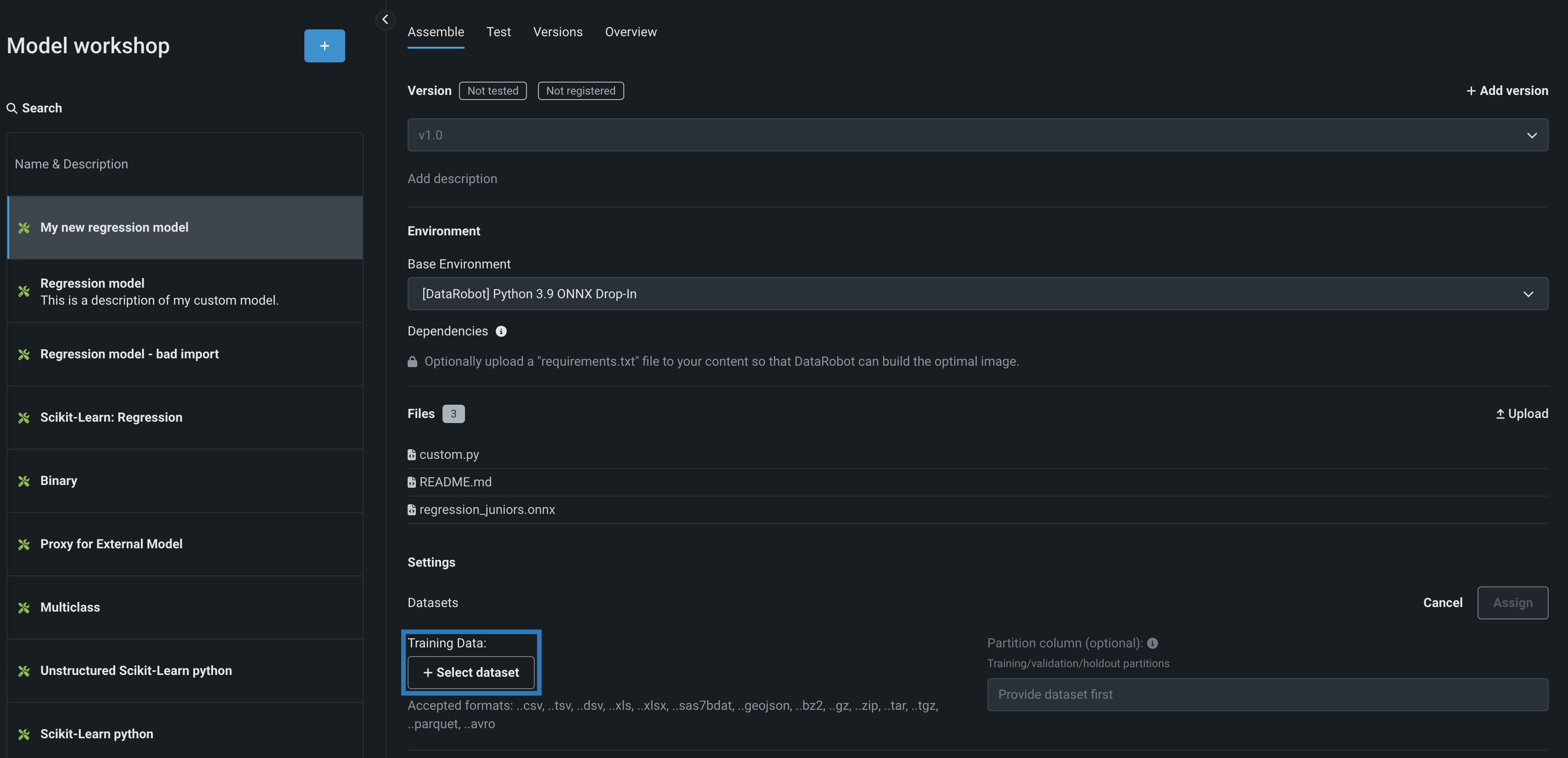
-
新しいデータセットをデータレジストリに追加するには、アップロードをクリックし、ローカルストレージからファイルを選択して、開くをクリックします。
-
データレジストリから既存のデータセットを選択するには、データレジストリリストで、DataRobotに以前アップロードしたトレーニングデータセットを見つけてクリックし、データセットを選択をクリックします。
スコアリングに必要な特徴量を含める
カスタムモデルのトレーニングデータの列は、デプロイされたカスタムモデルへのスコアリングリクエストにどの特徴量が含まれるかを示します。 したがって、トレーニングデータが利用可能になると、トレーニングデータセットに含まれない特徴量はモデルに送信されません。 Available as a preview feature, you can disable this behavior using the Column filtering setting.
-
-
(オプション)パーティション列セクションで、(トレーニング/検定/ホールドアウトのパーティショニングに基づいて)データのパーティショニング情報を含む列名(そこにあるトレーニングデータセットから)を指定します。 カスタムモデルをデプロイし、そのデータドリフトと精度を監視する予定であれば、列にホールドアウトパーティションを指定して、精度のベースラインを確立します。
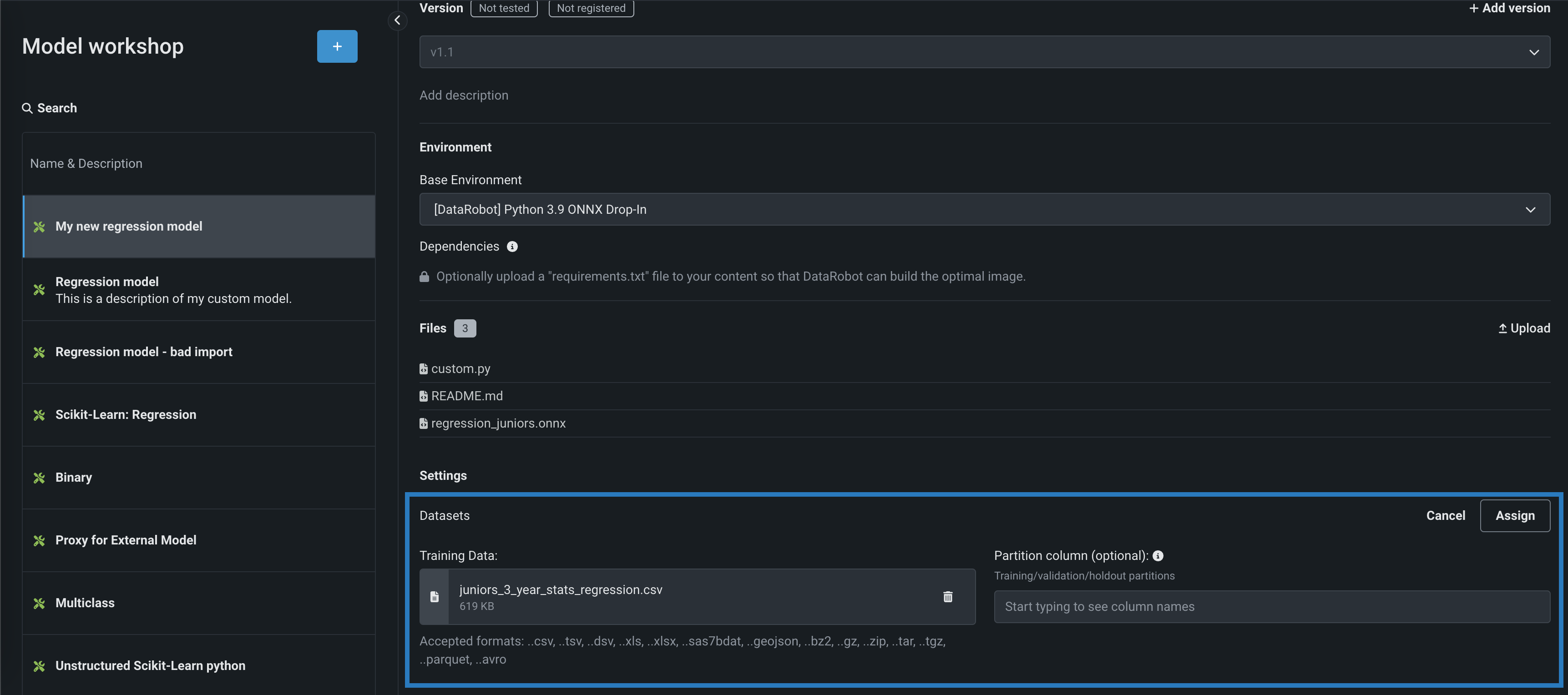
パーティション列の指定
パーティション列を指定しなくても、データのドリフトと精度を追跡できます。ただし、このシナリオでは、DataRobotにベースライン値はありません。 選択されたパーティション列は
T、V、Hのいずれかの値のみを含む必要があります。 -
割り当てるをクリックします。
トレーニングデータの割り当てエラー
トレーニングデータの割り当てに失敗すると、新しいカスタムモデルバージョンのデータセットの下にエラーメッセージが表示されます。 このエラーが存在する間は、影響を受けるバージョンをデプロイするモデルパッケージを作成できません。 エラーを解決してモデルパッケージをデプロイするには、トレーニングデータを再割り当てして新しいバージョンを作成するか、新しいバージョンを作成してからトレーニングデータを割り当てます。
予測リクエストでの列フィルターの無効化¶
本機能の提供について
Configurable column filtering is off by default. この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:カスタムモデルの予測で特徴量のフィルターを有効にする
Now available for preview, you can enable or disable column filtering for custom model predictions. 選択したフィルター設定は、カスタムモデルのテストやデプロイの際に同様に適用されます。 デフォルトでは、ターゲット列は予測リクエストから除外されます。また、トレーニングデータが割り当てられている場合、トレーニングデータセットに存在しない追加の列は、モデルに送信されるスコアリングリクエストから除外されます。 あるいは、予測データセットの列が欠損している場合は、欠損している特徴量を通知するエラーメッセージが表示されます。
カスタムモデルを構築する際に、この列フィルターを無効にすることができます。 モデルワークショップでカスタムモデルを開いて、アセンブルタブをクリックし、設定セクションの列のフィルターで、リクエストからターゲット列を除外をオフにします(または、トレーニングデータが割り当てられている場合は、ターゲット列とトレーニングデータにない余分な列を除外をオフにします)。
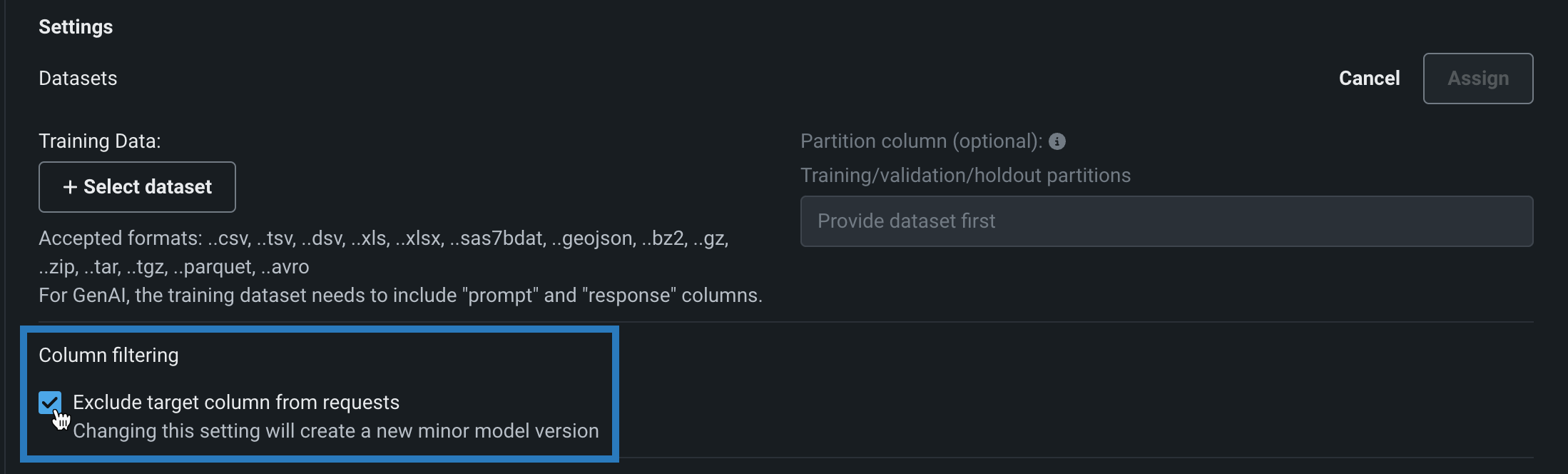
As with other changes to a model's environment, files, or settings, changing this setting creates a new minor custom model version.
The following behavior is expected when Exclude target column from requests / Exclude target and extra columns not in training data is enabled or disabled:
Training data assignment method
If a model uses the deprecated "per model" training data assignment method, this setting cannot be disabled and feature filtering is not applied during testing.
| Set to | Behavior |
|---|---|
| 有効 |
|
| 無効 |
|
DRUM predictions
Predictions made with DRUM are not filtered; all columns are included in each prediction request.
カスタムモデルのリソース設定を行う¶
カスタム推論モデルを作成した後、モデルが消費するリソースを設定して、スムーズなデプロイを促進し、本番環境で発生する可能性のある環境エラーを最小限に抑えることができます。
リソースの割り当てとアクセスを設定するには:
-
アセンブルタブの設定セクションで、リソースの横にある()編集をクリックします。
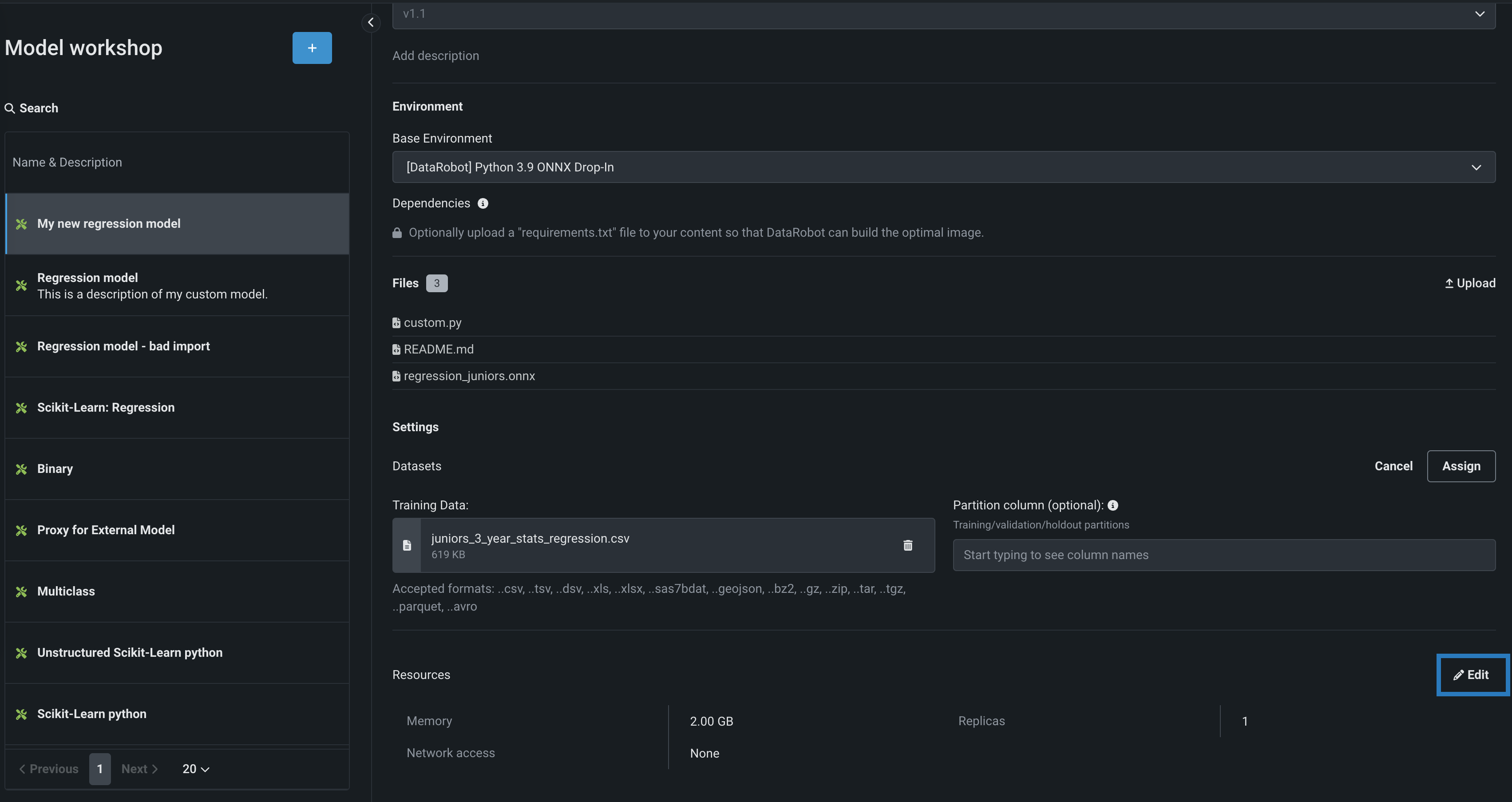
-
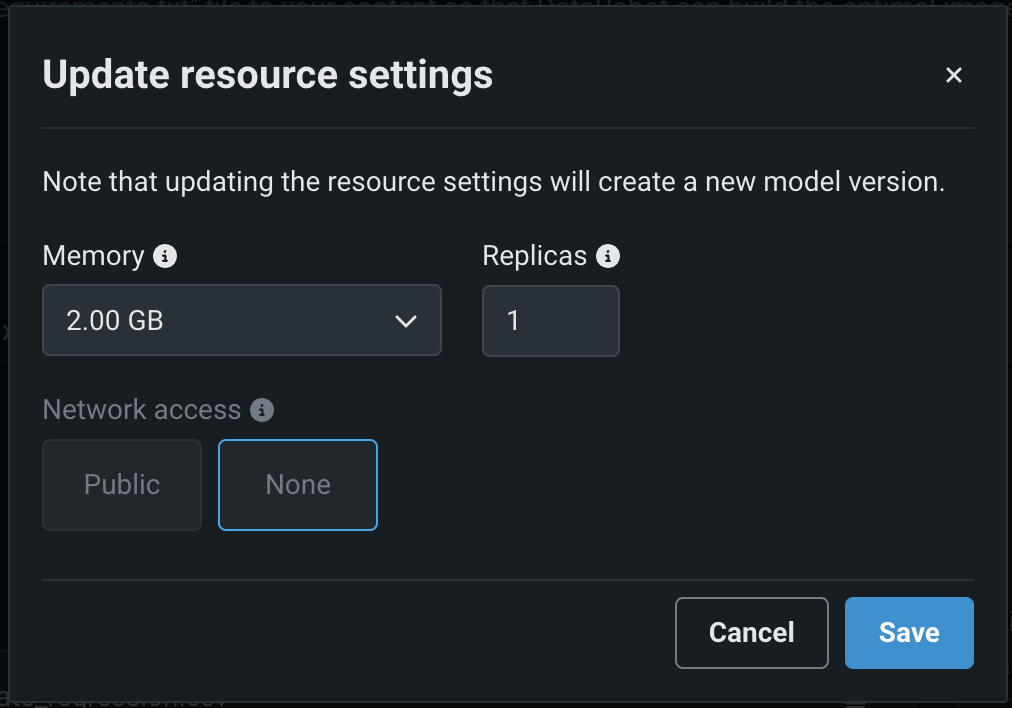
リソース設定の更新ダイアログボックスで、次の設定を行います。
リソース設定へのアクセス
ユーザーはモデルに割り当てられる最大メモリーを決定できますが、追加のリソース設定を行えるのは 組織管理者だけです。
設定 説明 メモリー カスタム推論モデルに割り当てることのできるメモリーの最大量を決定します。 設定された最大値以上のメモリーが割り当てられたモデルはシステムによって排除されます。 この問題がテスト中に発生した場合、テストは失敗としてマークされます。 モデルのデプロイ時に発生した場合は、Kubernetesによってモデルが自動的に再起動されます。 レプリカ カスタムモデルの実行時にワークロードのバランスを取るために、並行して実行するレプリカの最大数を設定します。 レプリカの数を増やしても、カスタムモデルの速度に依存するため、パフォーマンスが向上しない場合があります。 ネットワークアクセス プレミアム機能。 カスタムモデルのエグレストラフィックを設定します。 - パブリック:デフォルト設定。 カスタムモデルは、パブリックネットワーク内の任意の完全修飾ドメイン名(FQDN)にアクセスして、サードパーティのサービスを利用できます。
- なし:カスタムモデルはパブリックネットワークから分離されているため、サードパーティのサービスにはアクセスできません。
DATAROBOT_ENDPOINTおよびDATAROBOT_API_TOKEN環境変数を使用できます。 これらの環境変数は、 ドロップイン環境または DRUM上に構築された カスタム環境を使用するすべてのカスタムモデルで使用できます。バランスの悪いメモリー設定
DataRobotでは、必要な場合にのみリソース設定を行うことをお勧めします。 以下のメモリー設定では、Kubernetesメモリーの「制限」(メモリーの最大許容量)が設定されます。ただし、メモリーの「リクエスト」(メモリーの最小許容量)を設定することはできません。 このため、「制限」値をデフォルトの「リクエスト」値より大きく設定することができます。 メモリーの「リクエスト」と増加した「制限」によるメモリー許容量との不均衡が生じ、カスタムモデルがメモリー使用量の上限を超える場合があります。 その結果、カスタムモデルの頻繁な削除や再起動により、カスタムモデルが実行時に不安定になる場合があります。 メモリー設定を増やす必要がある場合は、組織レベルで「リクエスト」を増やすと、この問題を軽減できます。詳細については、DataRobotサポートまでお問い合わせください。
プレミアム機能:ネットワークアクセス
_新しく_作成したカスタムモデルはすべて、デフォルトでパブリックネットワークにアクセスできます。ただし、2023年10月より前に作成されたカスタムモデルの新しいバージョンを作成した場合、その新しいバージョンは、パブリックアクセスを有効にする(アクセスをパブリックに設定する)まで、パブリックネットワークから隔離された(アクセスがなしに設定された)ままです。 パブリックアクセスを有効にすると、後続の各バージョンは、前のバージョンのパブリックアクセス定義を継承します。
-
カスタムモデルのリソース設定を行ったら、保存をクリックします。
編集したリソース設定が適用された新しいバージョンのカスタムモデルが作成されます。
凍結バージョン
リソース設定を更新できるのは、最新のモデルバージョンに限ります。 さらに、最新のモデルバージョンが登録またはデプロイされている場合は、更新されたリソース設定を適用できず、変更を保存しようとすると、「凍結バージョン」の警告が表示されます。 この警告が表示された場合は、カスタムモデルバージョンを新規作成し、リソース設定を更新してから、正しい設定でモデルを登録してデプロイします。
Select a resource bundle¶
本機能の提供について
Custom model resource bundles are available for preview and off by default. この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ: リソースのバンドルを有効にする、カスタムモデルでGPUを使用した推論を有効にする
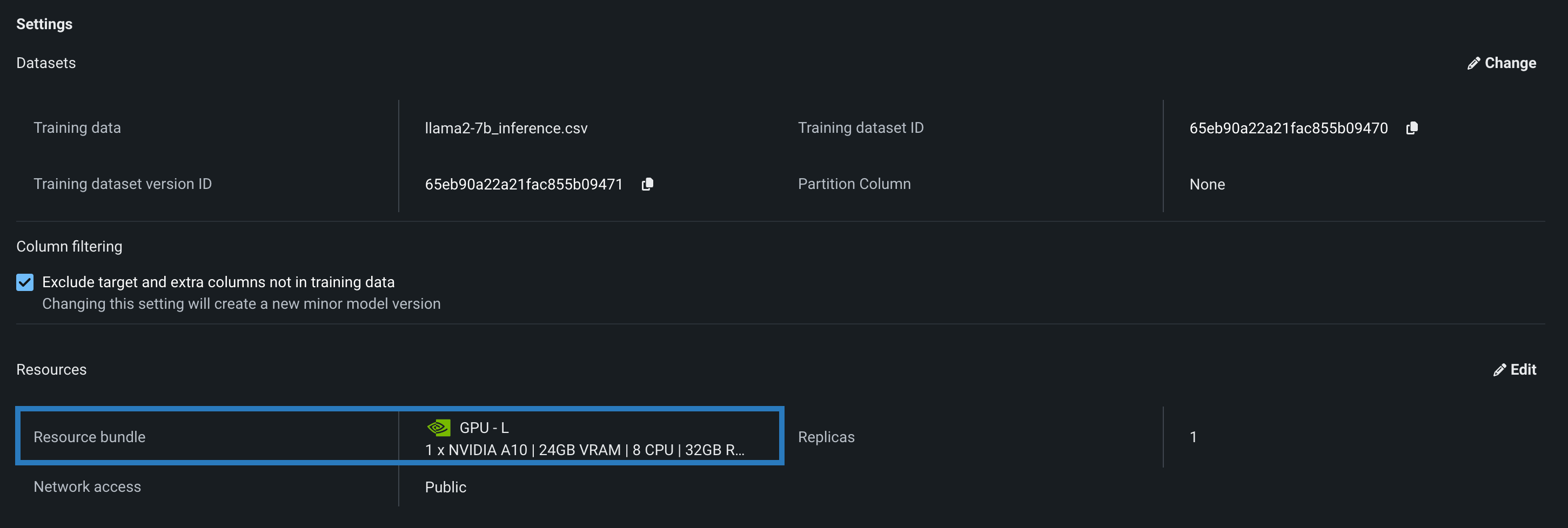
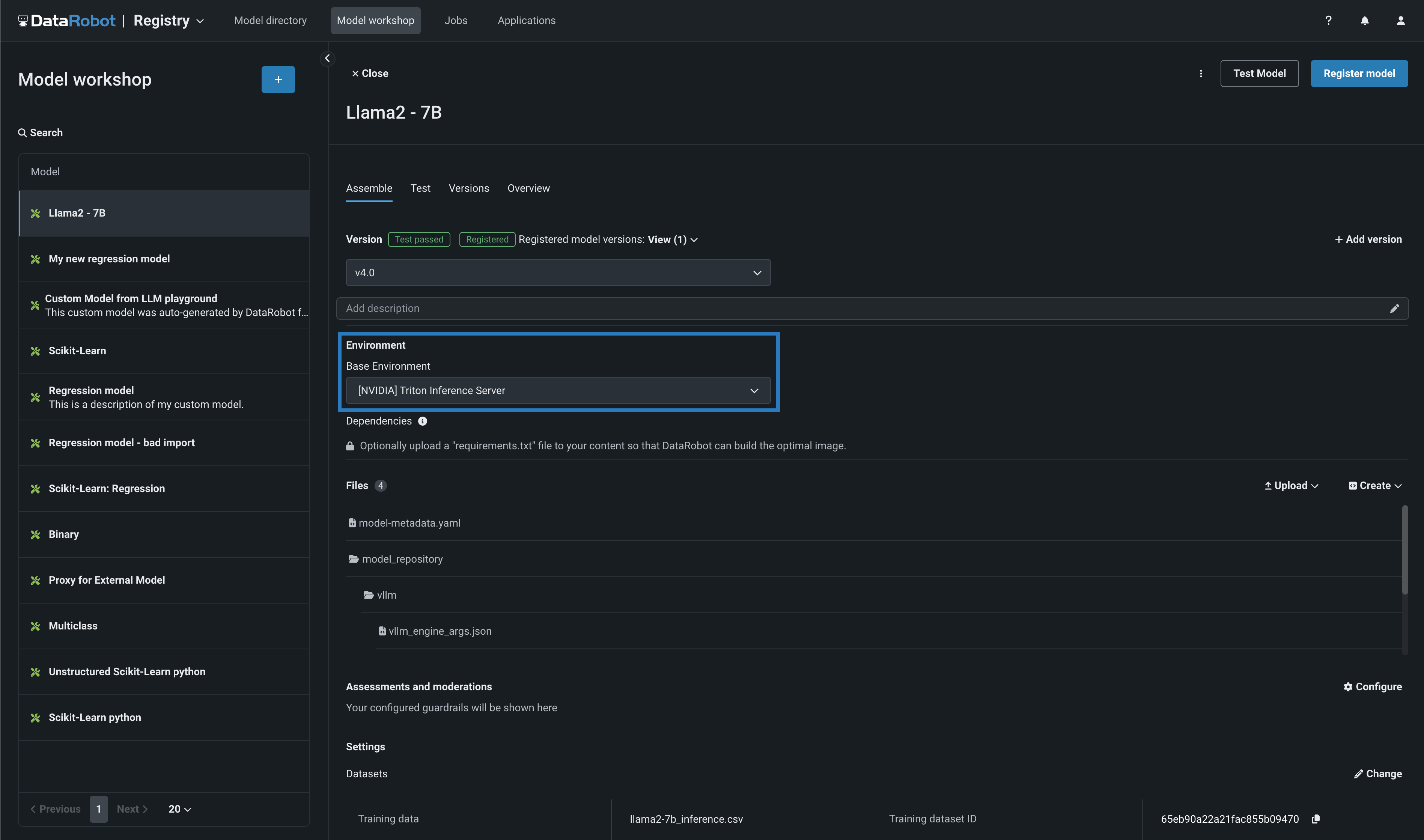
You can select a Resource bundle—instead of Memory—when you assemble a model and configure the resource settings. Resource bundles allow you to choose from various CPU and GPU hardware platforms for building and testing custom models. In a custom model's Settings section, open the Resources settings to select a resource bundle. In this example, the model is built to be tested and deployed on an NVIDIA A10 device.
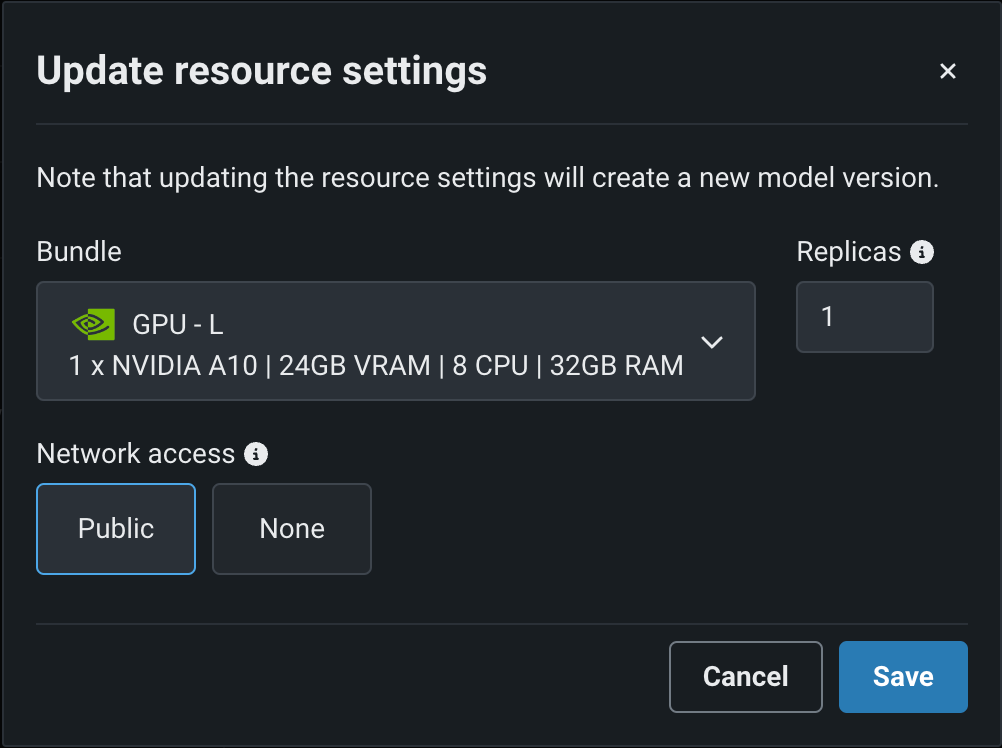
Click Edit to open the Update resource settings dialog box and, in the resource Bundle field, review the CPU and NVIDIA GPU devices available as build environments:
DataRobot can deploy models onto any of the following NVIDIA resource bundles:
| バンドル | GPU | VRAM | CPU | RAM | 説明 |
|---|---|---|---|---|---|
| GPU - S | 1 x NVIDIA T4 | 16GB | 4 | 16GB | Recommended for general deep learning workloads, or any machine learning workload that benefits from GPU acceleration. |
| GPU - M | 1 x NVIDIA T4 | 16GB | 8 | 32GB | |
| GPU - L | 1 x NVIDIA A10 | 24GB | 8 | 32GB | Recommended for running small LLMs. |
Along with the NVIDIA GPU resource bundles, this feature introduces custom model environments optimized to run on NVIDIA GPUs. When you assemble a custom model, you define a Base Environment. The model in the example below is running on an [NVIDIA] Triton Inference Server:
For more information on the DataRobot integration with NVIDIA, see Generative AI with NeMo Guardrails on NVIDIA GPUs.