テストデータやトレーニングデータでの予測¶
デプロイ前に予測を行い、モデルのパフォーマンスを評価するには、予測を作成タブを使用します。 外部のテストデータセットで予測する(つまり外部ホールドアウト)ことも、トレーニングデータで予測する(つまり検定やホールドアウト)ことも可能です。
外部のテストデータセットでの予測¶
モデルのパフォーマンスをよりよく評価するために、プロジェクトデータを準備してモデルをトレーニングした後、任意の数の追加のテストデータセットをアップロードできます。 外部テストデータセットは次の1つです。
-
実測値(ターゲットの値)が含まれる。
-
元のデータセットの一部ではない(その部分についてはトレーニングしなかった)。
外部テストデータセットを使用すると、精度と予測を比較できます。
外部データセットをアップロードして元のモデルのデータセットパーティションを使用することにより、精度指標やvisualizationを比較でき、デプロイ前に安定したパフォーマンスを確保することができます。 元のプロジェクトデータのパーティションの場合と同様に外部テストセットを選択します。 外部テストセットのサポートは、教師あり時系列を除くすべてのプロジェクトタイプで利用できます。 教師なし(異常検知)の時系列にも対応しています。
外部のテストセットで予測を行うには:
-
予測データセットをアップロードする場合と同じ方法で新しいテストデータをアップロードします 。 教師あり学習の場合、外部セットには、ターゲット列とトレーニングデータセットに存在するすべての列が含まれている必要があります(ただし、追加の列を追加することができます)。 異常検知プロジェクトのワークフローについては若干異なります。
-
アップロードされると、データセット名の下に外部テストというラベルが表示されます。 外部テストの実行をクリックすると、予測値が計算され、実際のターゲット値と予測値を比較する統計値が計算されます。 外部テストはキューされ、右のサイドバーにあるワーカーキューに表示されます。
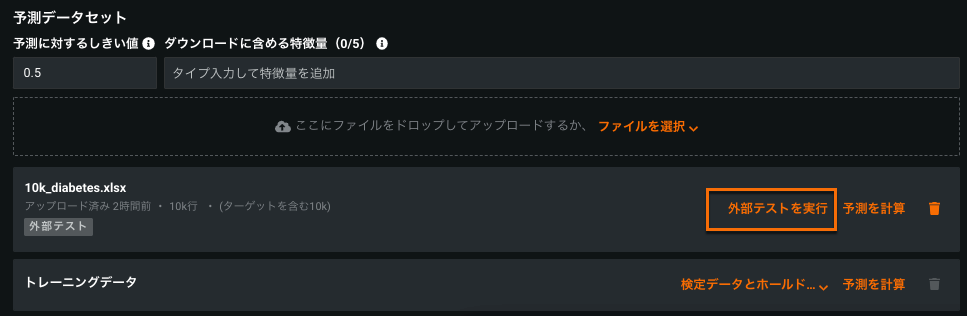
-
予測をダウンロードをクリックして、予測結果をCSVファイルに保存します。

備考
二値分類プロジェクトでは、外部テストを実行をクリックすると、現在の予測しきい値が予測ラベルの計算に使用されます。 ダウンロードされた予測では、計算とダウンロードの間にしきい値を更新しても、ラベルはそのしきい値に対応します。 DataRobotは、計算に使われたしきい値をデータセット一覧に表示します。
-
外部テストのスコアを表示するには、「リーダーボード」メニューから外部テスト列を表示を選択します。
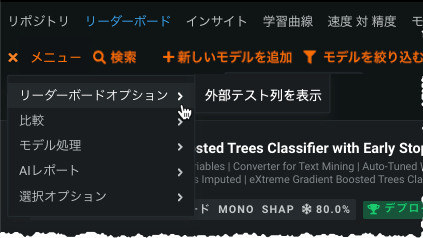
リーダーボードに外部テスト列が表示されるようになりました。
-
外部テスト列から、結果を表示するテストデータを選択するか、外部テストを追加をクリックして予測を作成タブに戻って追加のテストデータを追加します。

外部テストのスコアでモデルをソートしたり、より多くのモデルのスコアを計算することができるようになっています。
異常検知プロジェクトの実測値の提供¶
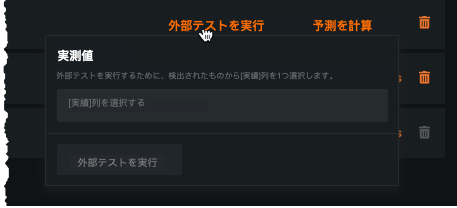
異常検知(非時系列)プロジェクトでは、予測結果と比較する結果を識別する実測値列を設定する必要があります。 これは、予測を行うイベントの精度の尺度を提供します。 予測データセットには、トレーニングセットと同じ列に加えて、少なくとも既知の異常値の1つの列が含まれる必要があります。 既知の異常列を実測値として選択します。
外部テストセットとインサイトの比較¶
元のプロジェクトデータのパーティションの場合と同様にデータ選択ドロップダウンを展開します。
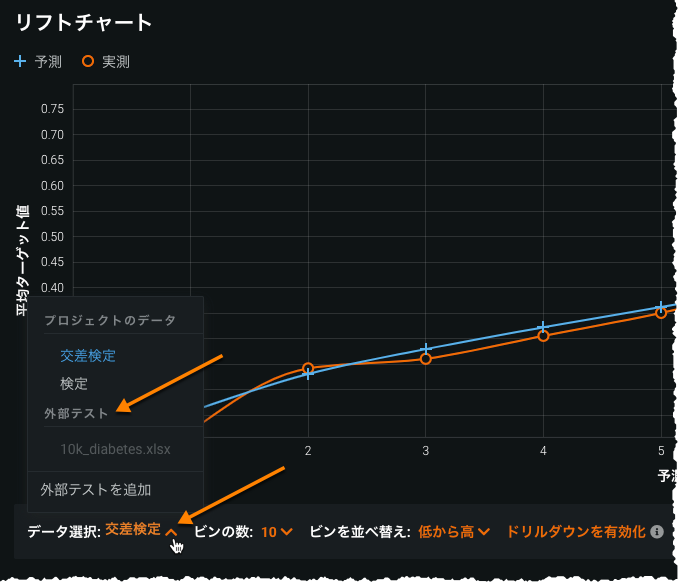
このオプションは、次のインサイトを使用しているときに使用できます。
以下の点に注意してください。
-
外部データセットの行数が10行未満の場合、インサイトは計算されません。ただし、指標スコアは計算され、リーダーボードに表示されます。
-
外部データセットに単一クラスの実測値しか含まれていない場合、ROC曲線のインサイトは無効になります。
トレーニングデータでの予測¶
(リーズンはあるにしても)あまり一般的ではないケースとして、DataRobotが自動的にインポートする元のトレーニングデータ用に予測をダウンロードすることがあります。 プルダウンから、予測を生成するときに使用するパーティションを選択します。
小さいデータセットの場合、予測の演算処理はスタックされた予測によって行われるので、すべてのパーティションが使用されます。 これらの計算は、大規模なデータセット(デフォルトでは750MB以上)で実行するには「コストがかかりすぎる」ため、トレーニングに使用されていないデータであれば、ホールドアウトパーティションや検定パーティションに基づいて予測が行われます。
トレーニングデータによる予測 vs. リーダーボードでの交差検定
リーダーボードのトレーニングデータで生成される予測値は、リーダーボードでの交差検定スコアの生成に使用される予測値と一致しない必要があります。これは、トレーニングデータを用いた予測では、トレーニングデータ内のスタックされた予測が使用されるためです。 より詳細な比較については、以下を参照してください。
-
トレーニングデータでの予測値:スタックされた予測を使用して生成されます。インサンプル予測に起因するオーバーフィッティングを発生させずに、トレーニングデータで予測を行います。 トレーニングデータでアウトオブサンプル予測を行うために、スタックされた予測では、トレーニングデータの5つの異なる_分割_(セクション)で複数のモデルを構築し、誤解を招くような高い精度スコアを防ぎます。 このプロセスは、トレーニングデータ内で実行されます。
-
交差検定での予測値:K分割交差検定(デフォルトは5分割)を使用して生成されます。データの複数のサブセットに対して予測を行い、新しいデータが提示されたときにモデルが適切に一般化されるようにします。 リーダーボードでは、交差検定スコアは、各分割で計算されたK分割交差検定スコアの平均を表します。 このプロセスは、トレーニングデータと検定データに対して実行されます。
| ドロップダウンオプション | 小さいデータセットの説明 | 大きいデータセットの説明 |
|---|---|---|
| すべてのデータ | モデルのトレーニングに使用されたか、およびホールドアウトのロックが解除されているかどうかは関係なく、予測は、トレーニング、検定、およびホールドアウトパーティションに対して、スタックされた予測を行って計算されます。 | 使用できません |
| 検定データとホールドアウト | 予測は検定およびホールドアウトパーティションを使用して演算されます。 トレーニングで検定が使用されていた場合、このオプションは無効化されます。 | 予測は検定およびホールドアウトパーティションを使用して演算されます。 トレーニングで検定が使用された場合、またはホールドアウトパーティションなしでプロジェクトが作成された場合、このオプションは使用できません。 |
| 検証 | ホールドアウトパーティションなしでプロジェクトが作成されている場合、このオプションは検定とホールドアウトオプションを置き換えます。 | ホールドアウトパーティションなしでプロジェクトが作成されている場合、このオプションは検定とホールドアウトオプションを置き換えます。 |
| ホールドアウト | 予測はホールドアウトパーティションのみを使用して演算されます。 ホールドアウトがトレーニングで使用されていた場合、このオプションは使用できません(すべてのデータのオプションが有効です)。 | 予測はホールドアウトパーティションのみを使用して演算されます。 ホールドアウトがトレーニングで使用されていた場合、このデータセットで予測を行うことはできません。 |
備考
OTVプロジェクトの場合、ホールドアウトパーティションで再トレーニングされたモデルを使用してホールドアウト予測を生成します。 代わりに、ホールドアウトを外部テストデータセットとしてアップロードすると、バックテスト1のモデルを使用して予測を生成します。この場合、外部テストからの予測はホールドアウト予測と一致しません。
予測を計算をクリックして、既存のデータセットで選択したパーティションの予測を生成します。 予測値をダウンロードを選択すると、結果がCSVで保存されます。
備考
エクスポートされた結果のPartitionフィールドには、交差検定パーティションのソースパーティション名またはフォールドナンバーが表示されます。 この値-2は行が「破棄された」ことを示します(TVHでは使用されません)。 ターゲットが欠損している、パーティション列(日付/時刻、グループ、またはパーティション特徴量で分割されたプロジェクト)が欠損している、スマートダウンサンプリングが有効で、ダウンサンプリングの一環としてそれらの行がマジョリティークラスから破棄された、などの理由が考えられます。
予測にトレーニングデータを使用する理由とは?¶
一般的ではありませんが、元のトレーニングデータセットで予測を作成する場合があります。 最も一般的に、大規模データセットでの使用が考えられます。 大規模データセットに対してスタックされた予測を実行すると演算コストが高くなりすぎるので、予測の作成タブで検定パーティションおよびホールドアウトパーティションのデータを使用して予測をダウンロードすることができます(トレーニングで使用されていない場合)。
いくつかの使用例を以下に示します。
ソフトウェア開発者は、平均値ではなく、予測の完全な分布を把握する必要があります。 データセットは大規模なので、スタックされた予測は使用できません。 R APIを使用して毎週モデリングを行うことにより、ホールドアウトおよび検定の予測をローカルマシンにダウンロードしてRに読み込み、必要なレポートを生成します。
データサイエンティストは、社内の指標を使用した場合と全く同じモデルのスコアリングがDataRobotで再現できることを確認する必要があります。 モデリング中にホールドアウトを指定してデータのパーティショニングを行います。 モデリングが完了した後、ホールドアウトのロックを解除して上位モデルを選択し、ホールドアウトセットの予測を演算してダウンロードします。 その後、その簡単な演習の予測と以前の複数月にわたる長期プロジェクトの結果を比較します。