LLMの評価¶
本機能の提供について
Evaluation metrics are off by default. この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
Evaluation metrics help your organization report on prompt injection and hateful, toxic, or inappropriate prompts and responses. These metrics can also prevent hallucinations or low-confidence responses and safeguard against the sharing of personally identifiable information (PII). Many evaluation metrics connect a playground-built LLM to a deployed guard model. These guard models make predictions on LLM prompts and responses and then report the predictions and statistics to the playground. The LLM evaluation metric tools include:
Add and configure metrics¶
To use evaluation metrics, first, if you intend to use any of the Evaluation Deployment type metrics—Custom Deployment, PII Detection, Prompt Injection, Sentiment Classifier, and Toxicity—deploy the required guard models from the NextGen Registry to make predictions on an LLM's prompts or responses.
To select and configure evaluation metrics in an LLM playground, click Configure metrics below the prompt box or LLM evaluation in the side navigation bar:

If you haven't added any blueprints to the playground, in the Evaluate with metrics tile, click Configure metrics to configure metrics before adding a blueprint:

The LLM Evaluation page opens to the Metrics tab. Certain metrics are enabled by default; however, Citations and Rouge 1 require a vector database associated with the LLM blueprint to report a metric value. Click a disabled metric to enable it in the current playground. To configure a new metric for the playground, in the upper-right corner of the LLM Evaluation page, click Configure:

In the Configure evaluation panel, click evaluation metrics with + Add in the upper-right corner to add the metric; no configuration is required for these metrics. They may, however, require a vector database associated with the LLM blueprint to report metric values. Click metrics with Configure in the upper right corner to define the settings:

| Evaluation metric | 要件 | 説明 |
|---|---|---|
| 評価データセットの指標 | 評価データセット/ベクターデータベース | Either provide or synthetically generate a set of prompts or prompt and response pairs to evaluate aggregated metrics against the provided reference dataset. |
| コスト | LLM cost settings | Calculate the cost of generating the LLM response using default or custom LLM, currency, input cost per token, and output cost per token values. |
| トークン数 | Token count settings | LLMへの入力、LLMからの出力、ベクターデータベースから取得したテキストに関連付けられたトークンの数を追跡します。 |
| 待ち時間 | N/A | Report the response latency of the LLM blueprint. |
| 引用 | ベクターデータベース | ベクターデータベースをプロンプトする際にLLMによって取得されたドキュメントを報告します。 |
| 忠実度 | ベクターデータベース | Measure if the LLM response matches the source to identify possible hallucinations. |
| Rouge 1 | ベクターデータベース | LLMブループリントから生成された回答とベクターデータベースから取得されたドキュメントの間で類似度を計算します。 |
| Custom Deployment | Custom deployment | Use any deployment to evaluate and moderate your LLM (supported target types: regression, binary classification, multiclass, text generation). |
| PII検出 | PresidioのPII検出のデプロイ | Detect Personally Identifiable Information (PII) in text using the Microsoft Presidio library. |
| Prompt Injection | プロンプトインジェクション分類器のデプロイ | Detect input manipulations, such as overwriting or altering system prompts, intended to modify the model's output. |
| センチメント分類器 | センチメント分類器のデプロイ | テキストのセンチメントを肯定的か否定的に分類します。 |
| 毒性 | 毒性分類器のデプロイ | Classify content toxicity to apply moderation techniques, safeguarding against dissemination of harmful content. |
グローバルモデル
The deployments required for PII detection, prompt injection detection, sentiment classification, and toxicity classification are available as global models in the registry.
Depending on the evaluation metric (or evaluation metric type) selected, different configuration options are required. Click the tab below to learn more about the settings for each metric or metric type:
For Evaluation dataset metrics, under Add evaluation dataset to Use Case, do one of the following:

| Dataset addition method | 説明 |
|---|---|
| 評価データセットをアップロード | Click + Select dataset and, from the Data Registry panel, select a data set and click Select dataset, or click Upload to register and select a new dataset. |
| 合成データを生成 | Enter a Dataset name, select an LLM and Vector database to use when creating synthetic data, and then click Generate. For more information, see Synthetic datasets. |
| ユースケースから選択 | Select an Evaluation dataset from the current Use Case. |
After you add a dataset, click the Correctness metric tile to apply that metric to LLM responses in the playground. Correctness calculates a response similarity score between the LLM blueprint and the supplied ground-truth evaluation dataset.
When you add an evaluation dataset, it appears on the LLM Evaluation > Evaluation datasets tab, where you can click the action menu to Edit evaluation dataset or Delete evaluation dataset:

For the Cost metric, in the row for each LLM type, define a Currency, Input cost in currency amount / tokens amount, and Output cost in currency amount / tokens amount:

For the Token Count metric, select the token types to count: Total token count, Citation token count, Input token count, and Output token count:

For the Evaluation Deployment type metrics—Custom Deployment, PII Detection, Prompt Injection, Sentiment Classifier, and Toxicity—configure the following settings:

| フィールド | 説明 |
|---|---|
| 名前 | Enter a unique name if adding multiple instances of the evaluation metric. |
| 適用先 | Select one or both of Prompt and Response, depending on the evaluation metric. |
| デプロイ名 | Select the model deployment corresponding to the metric. For a Custom Deployment, you must also configure the Input column name and Output column name. The column names should be suffixed with PREDICTION, as they rely on the CSV data exported from the deployment. You can confirm the column names by exporting and viewing the CSV data from the custom deployment. |
| モデレーションの基準 | Define the criteria that determine when moderation logic is applied. |
After you configure a new metric, it appears on the LLM Evaluation > Metrics tab, where you can enable it:

指標を表示¶
The metrics you configure and add to the playground appear on the LLM responses in the playground. You can click the down arrow to open the metric panel for more details:

You can click Citation to view the prompt, response, and a list of citations in the Citation dialog box.
集計された指標¶
When a playground includes more than one metric, you can begin creating aggregate metrics. Aggregation is the act of combining metrics across many prompts and/or responses, which helps to evaluate a blueprint at a high level (only so much can be learned from evaluating a single prompt/response). Aggregation provides a more comprehensive approach to evaluation.
Aggregation either averages the raw scores, counts the boolean values, or surfaces the number of categories in a multiclass model. DataRobot does this by generating the metrics for each individual prompt/response and then aggregating using one of the methods listed, based on the metric.
To configure aggregated metrics, click Configure aggregation below the prompt input:
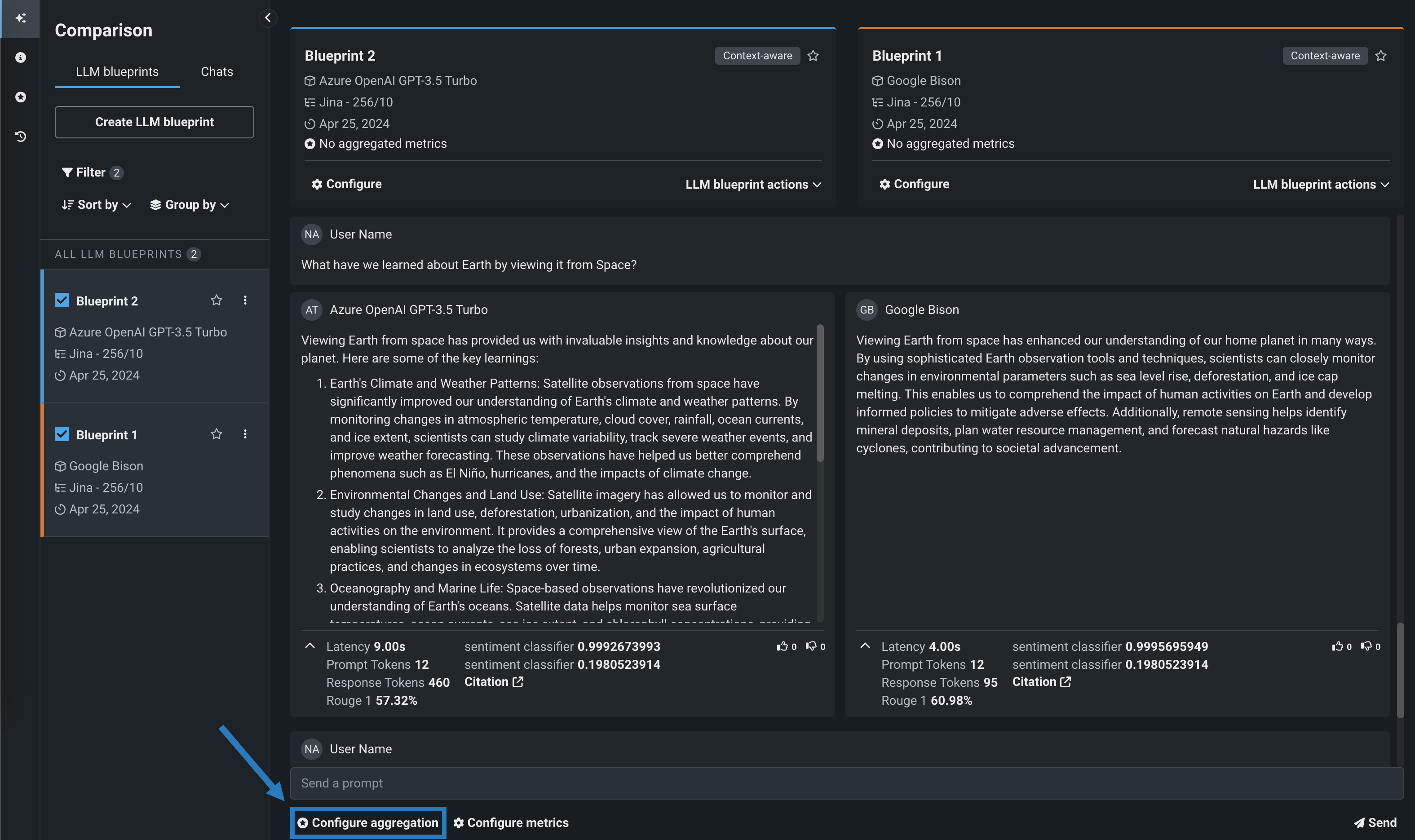
Aggregation job run limit
Only one aggregated metric job can run at a time. If an aggregation job is currently running, the Configure aggregation button is disabled and the "Aggregation job in progress; try again when it completes" tooltip appears.
On the Generate aggregated metrics panel, select metrics to calculate in aggregate and configure the Aggregate by settings. Then, enter a new Chat name, select an Evaluation dataset (to generate prompts in the new chat), and select the LLM blueprints for which the metrics should be generated. These fields are pre-populated based on the current playground:

Evaluation dataset selection
If you select an evaluation dataset metric, like Correctness, you must use the evaluation dataset used to create that evaluation dataset.
After you complete the Metrics selection and Configuration sections, click Generate metrics. これにより、関連するすべてのプロンプトと回答を含む新しいチャットが作成されます。

View aggregated metrics
Aggregated metrics are run against an evaluation dataset, not individual prompts in a standard chat. Therefore, you can only view aggregated metrics in the generated Aggregated chat, added to the LLM blueprint's All Chats list (on the configuration page).
評価データセット¶
When you add an evaluation dataset, it appears on the LLM Evaluation > Evaluation datasets tab, where you can click the action menu to Edit evaluation dataset or Delete evaluation dataset:
Synthetic datasets¶
When you add evaluation dataset metrics, DataRobot can use a vector database to generate synthetic datasets, composed of prompt and response pairs, to evaluate your LLM blueprint against. Synthetic datasets are generated by accessing the selected vector database, clustering the vectors, pulling a representative chunk from each cluster, and prompting the selected LLM to generate 100 question and answer pairs based on the document(s):
How is a synthetic evaluation dataset generated?
When you click Generate to create a synthetic evaluation dataset, two events occur sequentially:
-
A placeholder dataset is registered to the Data Registry with the required columns (
questionandanswer), containing 65 rows and 2 columns of placeholder data (for example,Record for synthetic prompt answer 0,Record for synthetic prompt answer 1, etc.). -
The selected LLM and vector database pair generates 100 question and answer pairs, added to the Data Registry as a second version of the synthetic evaluation dataset created in step 1. The generation time depends on the selected LLM.
追跡中¶
Tracing the execution of LLM blueprints is a powerful tool for understanding how most parts of the GenAI stack work. The tracing tab provides a log of all components and prompting activity used in generating LLM responses in the playground.

Insights from tracing provide full context of everything the LLM evaluated, including prompts, VDB chunks, and past interactions within the context window. 例:
- DataRobot metadata: Reports the timestamp, Use Case, playground, VDB, and blueprint IDs, as well as creator name and base LLM. These help pinpoint the sources of trace records if you need to surface additional information from DataRobot objects interacting with the LLM blueprint.
- LLM parameters: Shows the parameters used when calling out to an LLM, which is useful for potentially debugging settings like temperature and the system prompts.
- Prompts and responses: Provide a history of chats; token count and user feedback provide additional detail.
- Latency: Highlights issues orchestrating the parts of the LLM Blueprint.
- Token usage: displays the breakdown of token usage to accurately calculate LLM cost.
- Evaluations and moderations (if configured): Illustrates how evaluation and moderation metrics are scoring prompts or responses.