Advanced experiment setup¶
トレーニングの前に、より高度なモデリング条件を適用するには、オプションで以下の操作を行うことができます。
データパーティショニングタブ¶
パーティショニングは、評価とモデル構築のためにDataRobotが観測値(または行)をまとめて「集中させる」方法を示します。 ワークベンチのデフォルトは、 層化サンプリング(二値分類エクスペリメントの場合)またはランダム(連続値エクスペリメントの場合)による 5分割交差検定、および20%のホールドアウト分割です。

備考
日付特徴量が使用可能な場合、エクスペリメントは日付/時刻パーティションに適格です。日付/時刻パーティションでは、行がランダムではなく時系列でバックテストに割り当てられます。 時間認識プロジェクトで唯一有効な分割手法。 詳細については、時間認識モデリングのドキュメントを参照してください。
分割手法または検定タイプを追加設定から変更するか、サマリーのパーティショニングフィールドをクリックして変更します。

分割手法の設定¶
分割手法では、モデルのトレーニング時に行を割り当てる方法をDataRobotに指示します。 分割手法と検定タイプの選択は、ターゲット特徴量およびパーティション列に依存します。 つまり、すべての選択が常に使用可能として表示されるわけではないということです。 次の表は、各手法を簡単に説明しています。パーティショニングの詳細については、 このセクションも参照してください。

| 方法 | 説明 |
|---|---|
| 層化抽出 | 行は、トレーニングデータ、検定、ホールドアウトセットにランダムに割り当てられ、元のデータと同じ(可能な限り近い)予測ターゲット値の比率が保持されます。 これは、二値分類問題のデフォルトの手法です。 |
| ランダム | DataRobotでは、行がトレーニング、検定、ホールドアウトセットにランダムに割り当てられます。 これは、連続値問題のデフォルトの手法です。 |
| ユーザー定義のグループ化 | この特徴量の値と検定パーティションの間で1対1のマッピングが作成されます。 それぞれの一意の値には独自のパーティションが割り当てられ、その値を含むすべての行がそのパーティションに配置されます。 この方法は、カーディナリティが低いパーティション特徴量に推奨されます。 以下の、 グループ化によるパーティションを参照してください。 |
| 自動グループ化 | 選択した特徴量に対して同じ単一の値を含むすべての行は同じトレーニングまたはテストセットに含まれることが保証されます。 各パーティションには特徴量の1つ以上の値を含めることができますが、個々の値はDataRobotによって自動的に一緒にグループ化されます。 この方法は、カーディナリティが高いパーティション特徴量に推奨されます。 以下の、 グループ化によるパーティションを参照してください。 |
| 日付/時刻 | 時間認識エクスペリメントを参照してください。 |
検定タイプの設定¶
検定タイプは、モデルを検証するためにデータで使用される方法を設定します。 方法を選択し、関連するフィールドを設定します。 設定フィールドの下のグラフィックは、設定を示します。 ユーザー定義または自動化されたグループパーティショニングを使用する場合は、検定タイプの説明を参照してください。

| フィールド | 説明 |
|---|---|
| 交差検定:2つ以上の“分割”にデータを分離し、分割ごとに1つのモデルを作成します。その分割に割り当てられたデータは検定に使用され、それ以外のデータはトレーニングに使用されます。 | |
| 交差検定の分割数 | 交差検定手法で使用する分割数を設定します。 数値を大きくすると、各分割で使用可能なトレーニングデータサイズが増加し、合計トレーニング時間が長くなります。 |
| ホールドアウトの割合(%) | トレーニング時にワークベンチが「非表示」にするデータの割合を設定します。 リーダーボードは、ホールドアウト値を表示します。これは、ホールドアウトパーティションに対してトレーニング済みモデルの予測を使用して計算されます。 |
| トレーニング-検定-ホールドアウト:データセットが大きい場合、データをトレーニング、検定、ホールドアウトの3つのセクションに分割し、データの1回のパスに基づいて予測します。 | |
| 検定の割合 | トレーニング時にワークベンチが「非表示」にするデータの割合を設定します。 |
| ホールドアウトの割合(%) | トレーニング時にワークベンチが「非表示」にするデータの割合を設定します。 リーダーボードは、ホールドアウト値を表示します。これは、ホールドアウトパーティションに対してトレーニング済みモデルの予測を使用して計算されます。 |
備考
データセットが800 MBを超える場合、すべての分割手法で使用可能な検定タイプはトレーニング-検定-ホールドアウトだけです。
グループ化によるパーティション¶
あまり一般的ではありませんが、ユーザー定義および自動化されたグループ分割では、グループ化の基礎となるデータセットの特徴量を _パーティション特徴量_で分割する方法が行われます。
-
_ユーザー定義のグループ化_では、選択したパーティション特徴量の一意の値ごとにパーティションが作成されます。 つまり、行は、選択したパーティション特徴量の値を使用してパーティションに割り当てられ、一意の値ごとに1つのパーティションになります。 この方法を選択すると、パーティション特徴量の一意の値が10未満である特徴量を指定することが推奨されます。
-
_自動化されたグループ化_では、パーティション特徴量の同じ単一(指定)値を持つすべての行が同じパーティションに割り当てられます。 各パーティションには、その特徴値が複数含まれることがあります。 この方法を選択すると、DataRobotにより一意の値が6以上である特徴量を指定することが推奨されます。
これらの方法のいずれかを選択すると、パーティション特徴量を入力するように求められます。 ヘルプテキストからは、パーティション特徴量に含める必要のある値の数に関する情報が得られます。ドロップダウンをクリックして、一意の値の数を含む特徴量を表示します。

パーティション特徴量の選択後、検定タイプを設定します。 検定タイプの適用性は、次のチャートに示すように、パーティション特徴量の一意の値に依存します。

自動化されたグループ化では、上記と同じ 検定設定が使用されます。 しかし、ユーザー定義のグループ化では、パーティション特徴量に固有の値の入力が求められます。 _交差検定_の場合、ホールドアウトの設定はオプションです。 設定する場合は、パーセンテージではなくパーティション特徴量の値を選択します。 _トレーニング-検定-ホールドアウト_の場合、ここでもパーセンテージではなく、各セクションのパーティション特徴量の値を選択します。

Configure incremental learning¶
本機能の提供について
Incremental learning for large datasets is off by default. この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
機能フラグ:
- 増分学習を有効にする
- Enable Data Chunking
増分学習(IL)は大規模なデータセット(10GB~100GB)に特化したモデルトレーニング方法であり、データをチャンク化してトレーニングのイテレーションを作成します。 モデルの構築が開始されたら、トレーニング済みのイテレーションを比較し、必要に応じて、別のアクティブバージョンを割り当てるか、トレーニングを継続することができます。 アクティブなイテレーションは、他のインサイトのベースとなり、予測に使用されます。
Using the default settings, DataRobot trains the most accurate model on all iterations and all other models on only the first iteration. From the Model Iterations you can train additional increments once models have been built.
IL experiment setup¶
IL is automatically enabled (required) for any dataset larger than 10GB. To begin configuration:
-
From within a Use Case, add a static or snapshotted dataset.
-
After the dataset registers (this can take significantly longer than non-IL experiments), set a binary classification or regression target, which enables IL and makes the settings available.
ヒント
Do not navigate away from the experiment configuration tab before you begin modeling. Otherwise, DataRobot will register the dataset again (which may be time consuming based on size) and the draft that results will not support incremental learning due to the incomplete configuration.
If there is a longer-than-expected delay, you can check the registration status in the AI Catalog:

-
Choose a modeling mode—either Quick Autopilot (the default) or Manual. Comprehensive mode is not available in IL. Notice that the experiment summary updates to show incremental modeling has been activated.

-
Click the Additional settings > Incremental modeling tab:

-
Configure the settings for your project:
設定 説明 増分サイズ Sets the number of rows to assign to each iteration. DataRobot provides the valid range per increment. すべてのイテレーションで最上位モデルをトレーニング Sets whether training continues for the top-performing model. When checked, the top-performing model is trained on all increments; other Leaderboard models are trained on a single increment. When unchecked, all models are trained on a single increment. This setting is disabled when manual modeling mode is selected. モデルの精度が上がらなくなったらトレーニングを停止 Sets whether to stop training new model iterations when model accuracy, based on the validation partition, plateaus. Specifically, training ceases when the accuracy metric has not improved more than 0.000000001% over the 3 preceding iterations. A graphic to the right of the settings illustrates the number and size of the increments DataRobot broke the experiment data into. Notice that the graphic changes as the number of increments change.

IL partitioning
Note the following about IL partitioning:
- The experiment’s partitioning settings are applied to the first iteration. Data from each subsequent iteration is added to the model’s training partition.
- Because the first iteration is used for all partitions—training, validation, and holdout—it is smaller than subsequent iterations which only hold training data.
-
モデリングを開始をクリックします。
-
When the first iteration completes, the Model Iterations insight becomes available on the Leaderboard.
ILに関する注意事項¶
Incremental learning is activated automatically when datasets are 10GB or larger. Consider the following when working with IL:
- IL is available for non-time aware binary classification and regression experiments only.
- You cannot restart a draft from a Use Case. You must create a new experiment.
- Default increment size is 4GB.
- Datasets must be either static or snapshots, registered in the AI Catalog. They cannot be directly uploaded from a local computer.
- Datasets must be between 10GB and 100GB.
- IL does not support user-defined grouping, automated grouping, or date/time partitioning methods.
- Comprehensive modeling mode is disabled for IL experiments.
- Cross-validation is not available.
- Monotonic feature constraints, assigning weights, and insurance-specific settings are not supported.
- Sharing is only available at the Use Case level; experiment-level sharing is not supported. When sharing, changing the active iteration is the only available option for any user but the experiment creator. If a user with whom a project was shared trains new iterations, all iterations will error.
- To model on datasets over 10GB, the organization's AI Catalog file size limit must be increased. システム管理者に連絡してください。
- Feature Discovery is available on AWS multi-tenant SaaS only. Primary datasets are limited to a maximum of 20GB; secondary datasets can be up to 100GB.
- The following blueprint families are available:
- GBM (Gradient Boosting Machine), such as Light Gradient Boosting on ElasticNet Predictions, eXtreme Gradient Boosted Trees Classifier
- GLMNET (Lasso and ElasticNet regularized generalized linear models), such as Elastic-Net Classifier, Generalized Additive2
- NN (Neural Network), such as Keras
- デフォルトでは、特徴量ごとの作用により、上位500の特徴量(特徴量のインパクトでランク付け)のインサイトが生成されます。 In consideration of runtime performance, Feature Effects generates insights for the top 100 features in IL experiments.
追加設定を行う¶
より高度なモデリング機能を設定するには、追加設定タブを選択します。 時系列モデリングタブについては、データセットで日付/時刻特徴量が見つかったかどうかに応じて、使用可能になるかグレーアウトされます。
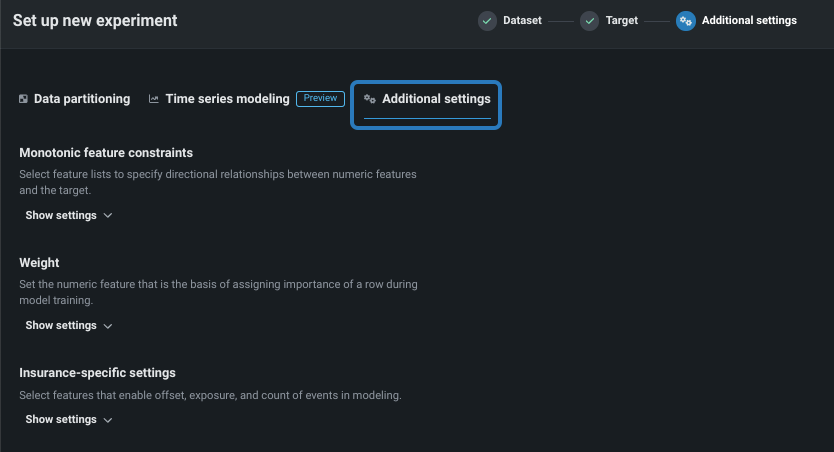
ビジネスユースケースに応じて、以下を設定します。
単調特徴量制約¶
単調制約は、特徴量とターゲットの間の上下方向の影響を制御します。 一部のプロジェクト(保険業や銀行業など)では、特徴量とターゲットの間の方向関係性を強制することが望ましい場合があります(評価価値の高い家屋の火災保険料が常に高くなるなど)。 単調制約でのトレーニングを行うことによって、特定のXGBoostモデルに特定の特徴量とターゲットの間の単調(常に増加または常に減少)関係性を学習させます。
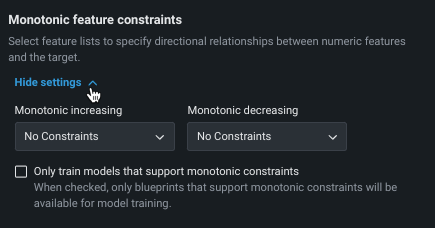
単調制約特徴量を使用するには、 特殊な特徴量セットを作成する必要があります。この特徴量セットは、ここで選択されます。 また、手動モードを使用する場合、使用可能なブループリントにはMONOバッジが付けられ、サポートされるモデルを識別できます。
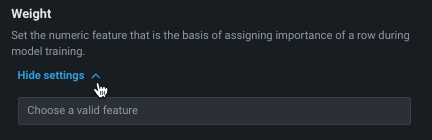
ウェイト¶
ウェイト違いを表す重みとして使用し、各行の相対的な有用性を示す単一の特徴量を設定します。 これは、モデルの構築やスコアリングの際に、リーダーボードで指標を計算する目的で使用されます。新しいデータで予測を行う目的では使用されません。 選択した特徴量のすべての値が0より大きい値である必要があります。DataRobotでは検定が行われ、選択した特徴量にはサポートされている値のみが含まれているかどうかが確認されます。
保険特有の設定¶
保険業界の頻繁な加重ニーズに対処するいくつかの機能を利用できます。 次の表では各モデルについて簡単に説明しますが、詳細については、 ここを参照してください。
| 設定 | 説明 |
|---|---|
| エクスポージャー | 連続値問題のターゲット予測において厳密な比例関係で処理される特徴量を設定し、保険料率をモデリングする際にエクスポージャーの指標を追加します。 DataRobotでは、エクスポージャーで選択された特徴量は特殊な列として扱われ、モデルの構築やスコアリングの際に元の予測に追加されます。選択した列は、予測のために後でアップロードするすべてのデータセットに存在する必要があります。 |
| イベント数 | ゼロ以外のイベントの頻度に関する情報を追加することで、ゼロ過剰ターゲットのモデリングを改善します。 |
| オフセット | 各サンプルでモデルの切片(線形モデル)またはマージン(ツリーベースモデル)を調整するもので、複数の特徴量を受け付けます。 |
設定を変更します。¶
ターゲットページに戻ることで、モデリングを開始する前に、プロジェクトのターゲットまたは特徴量セットを変更できます。 戻るには、サマリーのターゲットアイコン、戻るボタン、またはターゲットフィールドをクリックします。

次のアクション¶
モデリングを開始すると、DataRobotでリーダーボードにモデルが入力されます。 以下を実行することが可能です。
- エクスペリメント情報を表示オプションを使用すると、エクスペリメントに関するさまざまな情報を表示できます。
- 使用可能なモデルで モデル評価を開始します。