Basic experiment setup¶
ワークベンチで実行可能なAIエクスペリメントの「タイプ」は2つあります。
- Predictive modeling, described on this page for basic settings and here for advanced, makes row-by-row predictions based on your data.
- 時間認識モデリング。 こちらで説明しています。 時間に関連するデータを使用してモデルを作成し、行単位の予測、時系列予測、または現在値の予測である 「ナウキャスト」を行います。
エクスペリメントは、 ユースケース内の個々の"プロジェクト"です。 データ、ターゲット、モデリング設定を変更しながら、ビジネス問題を解決するための最適なモデルを見つけることができます。 各エクスペリメント内では、そのリーダーボードと モデルのインサイト、および エクスペリメントのサマリー情報にアクセスできます。
その他の重要情報については、関連する FAQを参照してください。
基本を作成¶
ユースケース内から新しいエクスペリメントを作成するには、次の手順に従います。
備考
モデリングを開始ボタンをクリックして、データセットから直接モデリングを開始することもできます。 新しいエクスペリメントの設定ページが開きます。 ここから、以下の手順に従ってください。
特徴量セットを作成¶
プレビュー
ワークベンチでの特徴量セットのサポートは、デフォルトではオンになっています。
機能フラグ:ワークベンチのプレビューで特徴量セットを有効にする
モデリングの前に、データタブからカスタム特徴量セットを作成できます。 モデリングの設定中にそのセットを選択すると、DataRobotはそのセットの特徴量のみを使用して、モデリングデータを作成します。
新しいセットを作成するには:
- ユースケースから、モデリングするデータセットを選択し、データプレビューを開きます。
-
ページの上部にあるドロップダウンをクリックし、+ 新しい特徴量セットを選択して特徴量ビューを開きます。
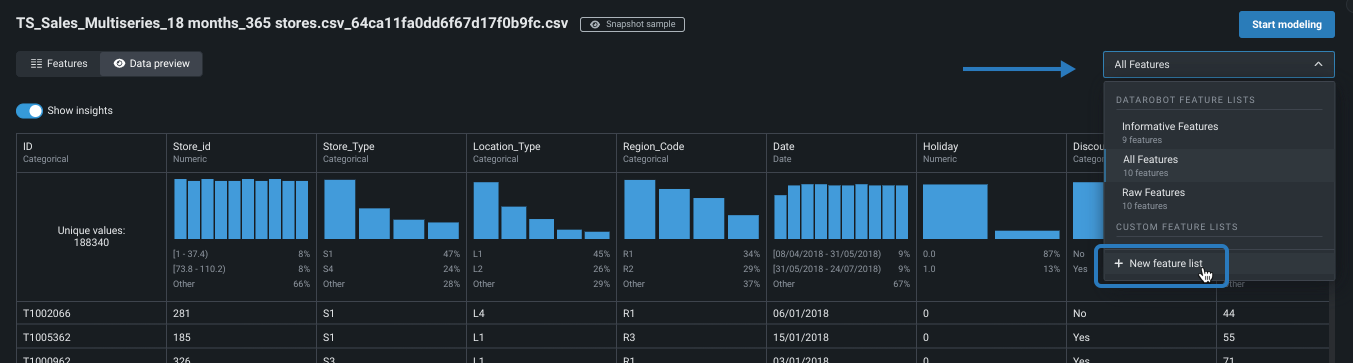
-
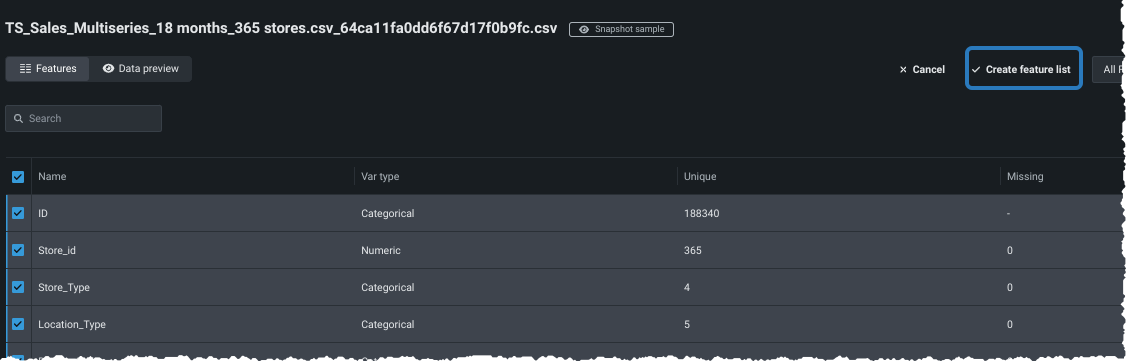
各特徴量の横にあるカスタムセットに含めたいチェックボックスを選択します。 次に、特徴量セットを作成をクリックし、名前と説明(オプション)を入力し、変更を保存をクリックします。
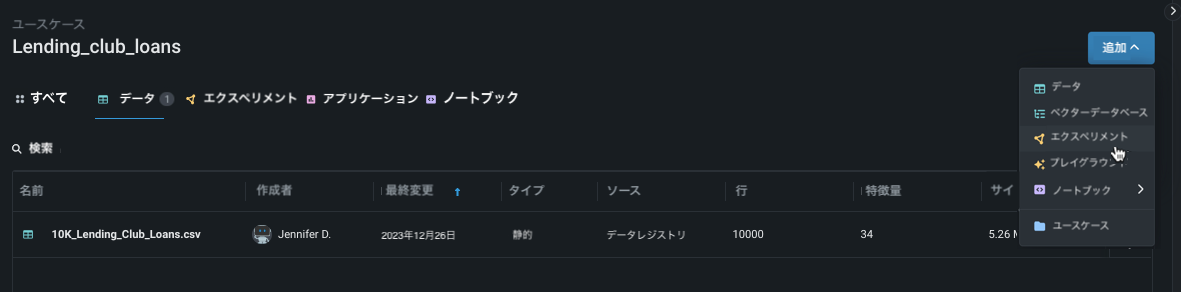
エクスペリメントを追加¶
ユースケース内から追加をクリックし、エクスペリメントを選択します。 新しいエクスペリメントの設定ページが開き、ユースケースにロード済みのすべてのデータが一覧表示されます。
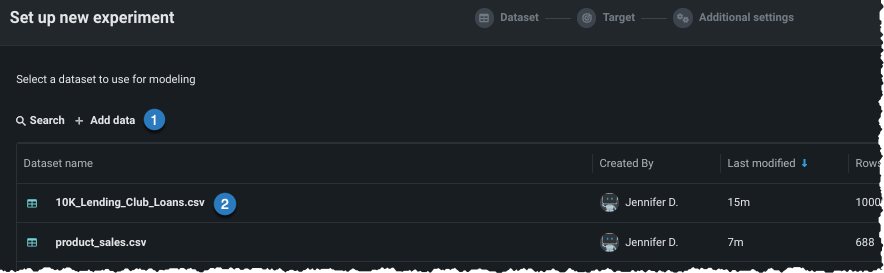
データを追加¶
新しいデータを追加 する(1)か、ユースケースに既にロードされているデータセットを選択する(2)ことにより、エクスペリメントにデータを追加します。
データがユースケースにロードされたら(上記のオプション2と同様)、エクスペリメントで使用するデータセットをクリックして選択します。 ワークベンチは、データのプレビューを開きます。
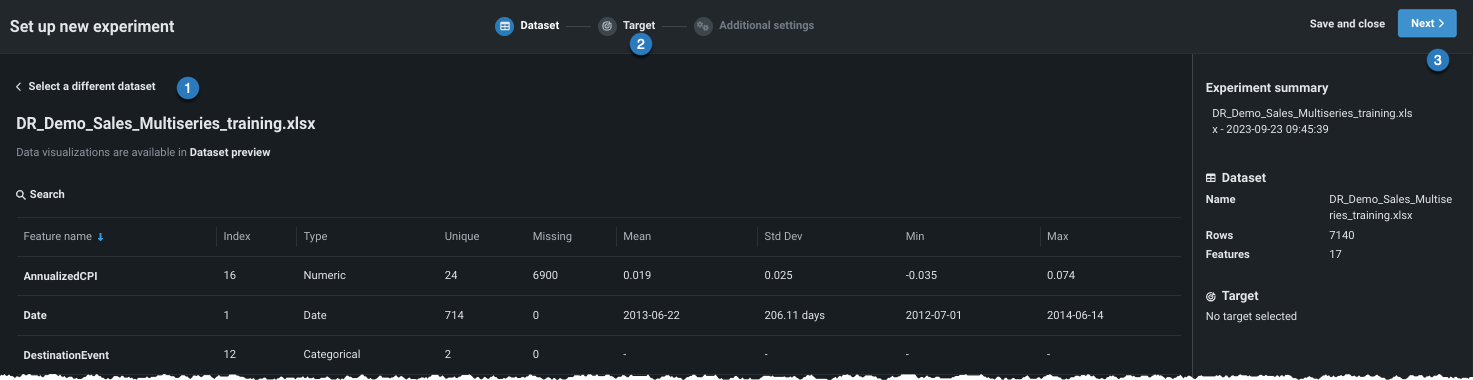
ここから、次のことができます。
| オプション | |
|---|---|
| 1 | クリックして、データリストに戻り、別のデータセットを選択します。 |
| 2 | アイコンをクリックして続行し、ターゲットを設定します。 |
| 3 | 次へをクリックして続行し、ターゲットを設定します。 |
ターゲットの設定¶
ターゲットの選択に進むと、ワークベンチでは、モデリング用のデータセットが準備されます(EDA 1)。
備考
これ以降のエクスペリメントの作成では、エクスペリメントの設定を続行するか、または保存して閉じるをクリックして、作成中のユースケースをドラフトとして保存できます。

ワークベンチで作成したドラフトをDataRobot Classicで開き、ワークベンチでサポートされていない機能を導入する変更を加えた場合、そのドラフトはユースケースにリストされますが、Classicインターフェイス以外からはアクセスできません。
EDA1が終了したとき、ターゲットを設定するには次のどちらかを実行します。
特徴量のリストをスクロールして、ターゲットを見つけます。 見つからない場合は、表示の下部からリストを展開します。
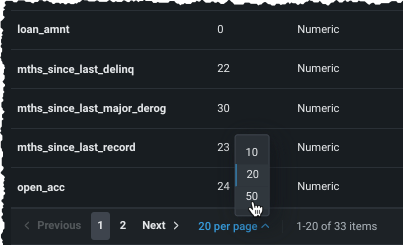
配置されたら、テーブル内のエントリーをクリックして、特徴量をターゲットとして使用します。
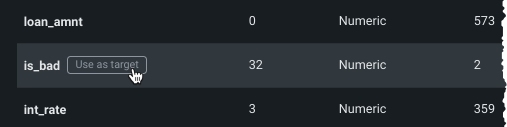
- 予測したいターゲット特徴量の名前を入力ボックスに入力します。 特徴量名の文字を入力するに従って、一致する特徴量がリスト表示されます。
DataRobotは、指定されたターゲット特徴量の値の数に応じて、自動的にエクスペリメントのタイプ(連続値または分類)を決定します。 分類エクスペリメントは、二値(二値分類)または3つ以上のクラス(多クラス)のいずれかになります。 次の表は、DataRobotが数値および非数値のターゲットデータ型にデフォルトの問題タイプを割り当てる方法を示しています。
| ターゲットデータ型 | 一意のターゲット値の数 | デフォルトの問題タイプ | 多クラス分類を使用 |
|---|---|---|---|
| 数値 | 2 | 分類 | いいえ |
| 数値 | 3+ | 連続値 | はい、オプション |
| 数値以外 | 2 | 二値分類 | いいえ |
| 数値以外 | 3-100 | 分類 | はい。自動 |
| 数値以外、数値 | 100+ | 集計された分類 | はい。自動 |
ターゲットを選択すると、ワークベンチには、ターゲット特徴量の分布に関する情報を提供するヒストグラムと、右ペインにエクスペリメント設定の概要が表示されます。
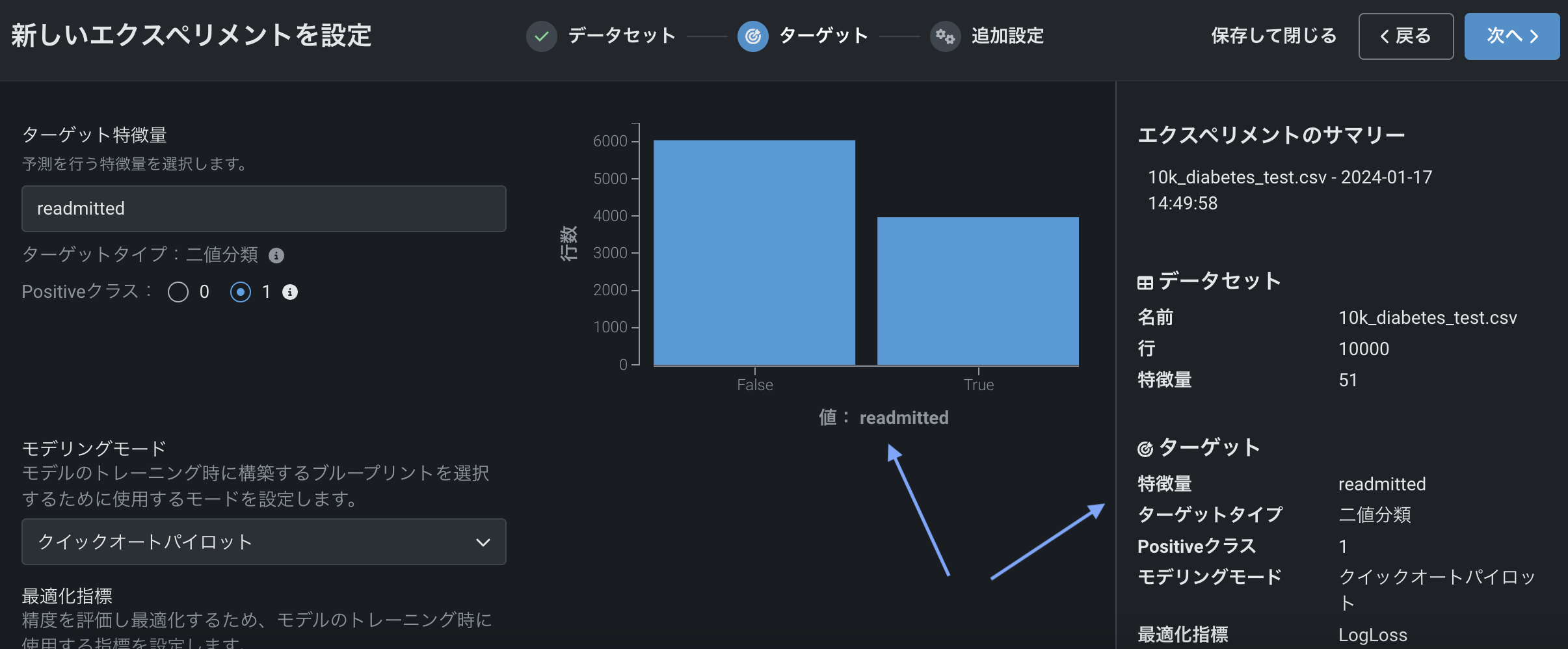
ここでは以下の操作を行うことができます。
-
連続値エクスペリメントを変更して多クラスエクスペリメントにします。
-
次へをクリックして、追加設定を表示します。そこでは、デフォルトの設定でモデルを作成したり、設定を変更したりすることができます。
-
多クラス分類エクスペリメントの場合、分類設定をさらに表示をクリックして、さらに集計設定を行います。
デフォルト設定を使用する場合は、モデリングを開始をクリックして、 クイックモードのオートパイロットモデリングプロセスを開始します。
連続値ターゲット¶
連続値エクスペリメントは、ターゲットが数値であるエクスペリメントです。 連続値予測問題は、入力変数(特徴量)のリストが与えられた場合、連続値(1.7、6、9.8...など)を予測します。 連続値問題の例には、財務予測、時系列予測、メンテナンスのスケジューリング、および気象分析などがあります。
連続値エクスペリメントは、ターゲットタイプを数値から分類に変更することで分類として処理することもできます。
| 一意の数値 | デフォルトのエクスペリメントタイプ | 変更できますか? |
|---|---|---|
| 2 | 二値分類 | いいえ |
| 3+ | 連続値 | はい |
連続値問題(数値ターゲット)を分類に変更するには、ターゲットタイプを識別するラジオボタンを変更します。

ターゲットタイプを変更すると、 多クラス設定オプションが有効になります。 ターゲットに1000を超える数値(クラス)がある場合、以下で説明する低頻度のクラスを集計オプションがデフォルトで有効になります。
分類のターゲット¶
分類エクスペリメントで、モデルは、特定のクラスの共通の特性を識別することにより、観測値をカテゴリーにグループ化します。 これらの特性を分類しているデータと比較し、観測値が特定のクラスに属する可能性を推定します。 分類プロジェクトは二値(2つのクラス)または多クラス(3つ以上のクラス)に分けることができます。
可用性:プレビュー
多クラス分類は、時間認識以外のエクスペリメントでは、デフォルトでオンになっているプレビュー特徴量です。
機能フラグ: 無制限の多クラス
分類エクスペリメントの設定は、タイプ(クラス数)に依存し、ターゲット特徴量エントリーの下にターゲットタイプとしてレポートされます。二値分類またはターゲットタイプ:分類。この場合、クラスの数も報告されます。

A multiclass confusion matrix helps to visualize where a model is, perhaps, mislabeling one class as another.
DataRobotでは、ターゲット特徴量に2つの一意の値(ブール値、カテゴリー値、または数値)がある場合に、二値分類エクスペリメントが作成されます。 この例には、顧客が期日までに決済するかどうか(YesまたはNo)、患者が再入院するかどうか(TrueまたはFalse)などがあります。 モデルは、特定の観測値が「ポジティブ」クラス(最後の例ではreadmitted=yes)に分類される予測確率を生成します。 デフォルトでは、予測確率が50%以上の場合、予測クラスは「ポジティブ」になります。代替のラジオボタンを選択して、Positiveクラスを変更し、 モデルのインサイトでPositiveとしてラベル付けできます。

一方、多クラス分類問題では、2つ以上の結果(クラス)が提供されます。 たとえば 、顧客が(単に購入しそうかどうかではなく)5つの競合のうちどれに目を向けるか、顧客が(単に電話をかけてきそうかどうかではなく)どの部署に電話をかけるべきか。 この場合、モデルは、特定の観測値が各クラスに分類される予測確率を生成します。予測クラスは、予測確率が最も高いクラスです。 (これは argmaxとも呼ばれます。) 多クラス分類問題でクラスオプションを追加すると、選択式の質問を増やすことができ、より詳細なモデルと解が得られます。
1000クラスをサポートするため、DataRobotは頻度に基づいて、クラスを自動集計して、1000個の一意のラベルにします。 集計の設定を行うこともできますが、デフォルトでは、DataRobotは最も頻度の高い上位999クラスを保持し、残りを1つの 「その他 」バケットに集計します。

しかし、集計パラメーターを設定して、プロジェクトに必要なすべてのクラスが表示されるように設定することもできます。 To configure, first, expand Show more classification settings and then toggle Aggregate low-frequency classes on.
次の表は、集計関連の設定を示します。
| 設定 | 説明 | デフォルト |
|---|---|---|
| 低頻度のクラスを集計 | 検出されたクラス数に基づくデフォルト設定で、集計機能を有効にします。 | 値が1000未満のターゲットの場合はオフ。 1000以上の値を持つターゲットではオンで、無効にすることはできません。 |
| 集計されたクラス名 | "Other" bin(この集計プランの設定に該当しないすべてのクラスを含むビン)の名前を設定します。 これはデータセットで除外された値のすべての行を表します。 列内の既存のターゲット値とは異なる名前を指定する必要があります。 | 集計済み |
| 集計方法 | 頻度しきい値:「その他」ビンに入れられないようにするために必要な、クラスに属する行の最小出現回数を設定します。 つまり、インスタンスの数が少ないクラスは、1つのクラスに折りたたまれます。 総クラス数:集計後のクラスの最終的な数を設定します。 最後のクラスは"Other" binです。 たとえば、900と入力した場合、データからの899クラスのbinと、集約されたクラスの"Other" bin 1つが存在することになります。 3~1000の値(クラスの最大許容数)を入力します。 |
頻度のしきい値, 1行 |
| 集計から除外されるクラス | 集計から保護されるクラスのコンマ区切りリストを指定し、対象となる頻度の低いクラスについて予測できるようにします。 | なし。オプション |
基本設定のカスタマイズ¶
エクスペリメントパラメーターを変更することは、ユースケースで同じ手順を繰り返すよい方法です。 モデリングを開始する前に、さまざまな設定を変更できます。
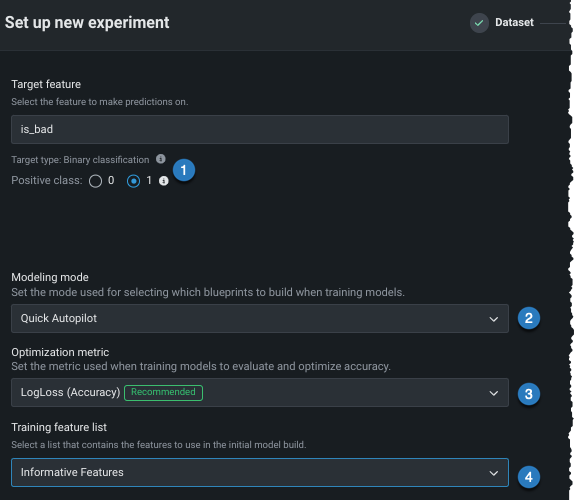
| 設定 | 変更対象 | |
|---|---|---|
| Positiveクラス | 二値分類プロジェクトの場合のみ。 予測スコアが分類しきい値よりも高い場合に使用するクラス。 | |
| モデリングモード | モデリングモード。DataRobotがトレーニングするブループリントに影響します。 | |
| 最適化指標 | DataRobotで推奨されているものとは異なる最適化指標に変更します。 | |
| トレーニング特徴量セット | DataRobotでモデルの構築に使用する特徴量のサブセット。 |
モデリングモードの変更¶
デフォルトでは、DataRobotはクイックオートパイロットを使用してエクスペリメントを構築します。 ただし、モデリングモードを変更することで、特定のブループリントまたは該当するすべてのリポジトリブループリントをトレーニングすることもできます。
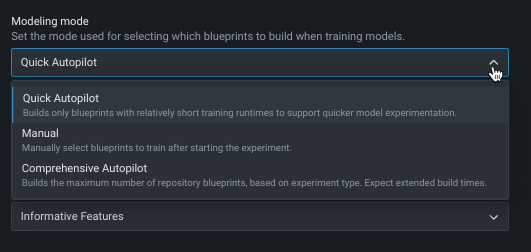
以下の表では、各モデリングモードについて説明しています。
| モデリングモード | 説明 |
|---|---|
| クイック(デフォルト) | クイックオートパイロットでは、最初に32%のサンプルサイズを使用し、その後に64%のサンプルサイズを使用して、指定されたターゲット特徴量とパフォーマンス指標に基づいてモデルのサブセットを実行し、モデルのベースセットとインサイトをすばやく提供します。 |
| 手動 | 手動モードでは、実行するブループリントを完全に管理できます。 EDA2が完了すると、DataRobotは ブループリントリポジトリにリダイレクトし、トレーニング用に1つまたは複数のブループリントを選択できます。 |
| 包括的 | モデルの精度を高めるために、最大のオートパイロットサンプルサイズですべてのリポジトリブループリントを実行する包括的なオートパイロットモード。 このモードでは構築時間が大幅に長くなります。 |
最適化指標の変更¶
最適化指標は、DataRobotによるモデルのスコアリング方法を定義します。 ターゲット特徴量を選択した後、モデリングタスクに基づいて最適化メトリックが選択されます。 通常、モデルのスコアリングのために DataRobotが選択する指標が、エクスペリメントに最適な選択です。 推奨された指標を上書きし、別の指標を使用してモデルを構築するには、最適化指標ドロップダウンを使用します。
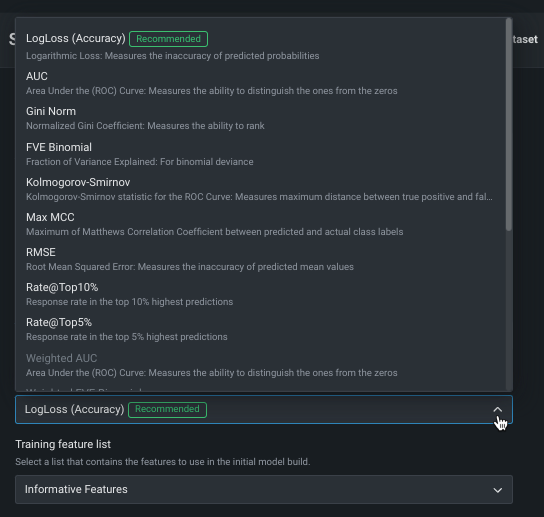
利用可能な指標の完全なリストと説明については、リファレンス資料を参照してください。
特徴量セットの変更(モデリング前)¶
特徴量セットは、DataRobotでモデルの構築に使用する特徴量のサブセットを制御します。 デフォルトでは 有用な特徴量セットですが、モデル構築の前に変更できます。 変更するには、特徴量セットドロップダウンをクリックし、別のセットを選択します。
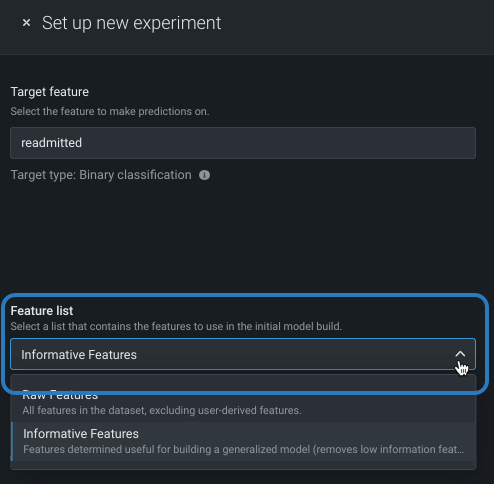
エクスペリメントの構築が終了したら、モデルごとに 選択済みリストを変更することもできます。
追加の自動化を設定¶
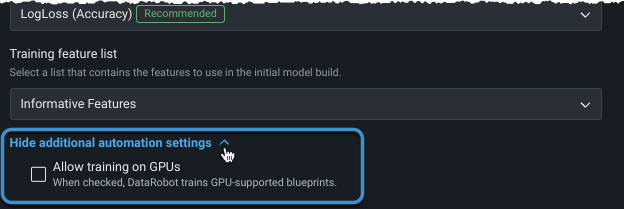
高度な設定に移動する前に、またはモデリングを開始する前に、他の自動化を設定できます。
ターゲットを設定し、基本設定を表示した後、追加の自動化設定を表示を展開して、追加のオプションを表示します。
GPUでのトレーニング¶
本機能の提供について
GPUワーカーはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者にお問い合わせください。
テキストや画像を含み、ディープラーニングモデルを必要とするデータセットの場合、 GPUでのトレーニングを選択すると、トレーニング時間を短縮できます。 一部のモデルはCPU上で実行できますが、他のモデルでは、適切なレスポンス時間を実現するためにGPUが必要です。 GPUでのトレーニングを許可するを選択すると、DataRobotは特定のタスクを含むブループリントを検出し、オートパイロットの実行にGPU対応のブループリントを含めます。 GPUバリアントとCPUバリアントの両方がリポジトリに用意されており、トレーニングに使用するワーカーのタイプを選択できます。GPUバリアントのブループリントは、GPUワーカーでより速くトレーニングできるように最適化されています。 GPUの使用については、以下の点を考慮してください。
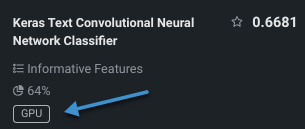
- リーダーボードが生成されると、 フィルターを使用してGPUベースのモデルを簡単に識別できます。
- モデルを 再トレーニングすると、結果として得られるモデルもGPUを使用してトレーニングされます。
- 手動モードを使用すると、 ブループリントリポジトリでフィルターすることでGPU対応のブループリントを識別できます。
- 最初にGPUでトレーニングするように選択しなかった場合、リポジトリを介して、またはモデリングを再実行することで、GPU対応のブループリントを追加できます。
-
GPUでトレーニングされたモデルは、リーダーボードでバッジが付けられます。
説明された設定の一部またはすべてを変更した後、次へをクリックして、以下のいずれかを実行します。
- モデリングを開始をクリックして、 クイックモードの予測モデリングプロセスを開始します。
- より 高度な設定をカスタマイズします。
-
Changes the project's target or feature list before modeling by returning to the Target page. 戻るには、サマリーのターゲットアイコン、戻るボタン、またはターゲットフィールドをクリックします。

次のアクション¶
Configuration for large datasets
For datasets larger than 10GB, DataRobot automatically applies incremental learning, which chunks data to allow for more manageable and efficient training processes.
モデリングを開始すると、DataRobotでリーダーボードにモデルが入力されます。 以下を実行することが可能です。
- エクスペリメント情報を表示オプションを使用すると、エクスペリメントに関するさまざまな情報を表示できます。
- 使用可能なモデルで モデル評価を開始します。