Document ingest and modeling¶
PDF documents used for modeling are extracted by tasks within the blueprint and registered as a dataset made of a single text column, with each row in the column representing a single document and with the value being the extracted text—features of type document.
The steps to build models are:
- Prepare your data.
- Model with text, including ingesting, converting PDF to text, and analyzing data.
Prepare PDF data¶
The following options describe methods of preparing embedded text PDF or PDF documents with scans as data that can be imported into DataRobot for modeling. See the deep dive below for a more detailed description of both data handling methods.
-
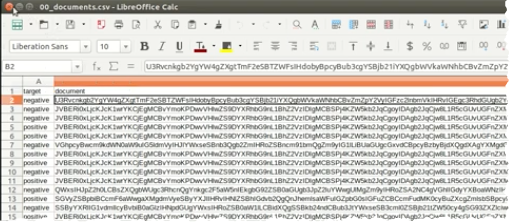
Include PDF documents as base64-encoded strings inside the dataset. (See the DataRobot Python client utility methods for assistance.)
-
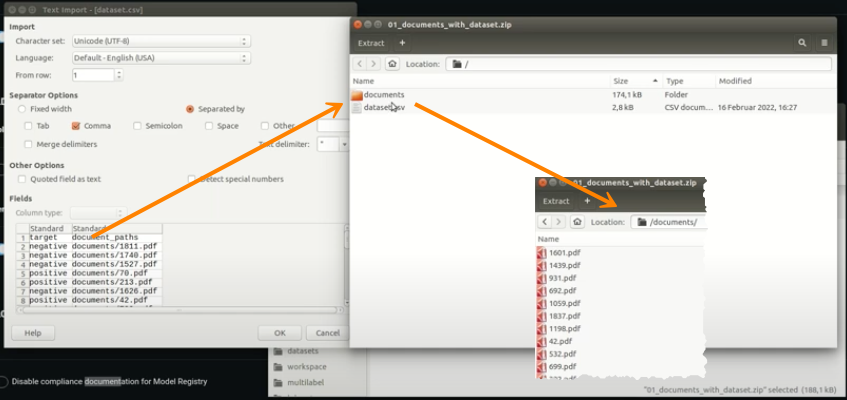
Upload an archive file (e.g., zip) with a dataset file that references PDF documents relative to the dataset (document columns in the dataset contain paths to documents).
-
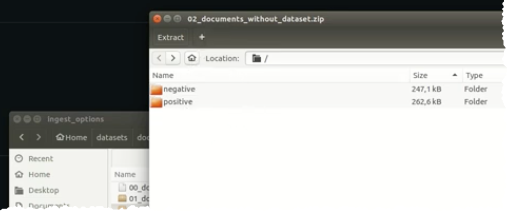
For binary or multiclass classification, separate the PDF document classes by folder, then compress the separated PDFs into an archive and upload them. DataRobot creates a column with the directory names, which you can use as the target.
-
For unsupervised projects, include all PDF files in the root (no directories needed).
-
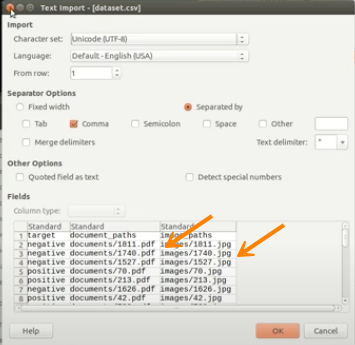
Include a dataset along with your documents and other binary files (for example, images). In the dataset, you can reference the binary files by their relative path to the dataset file in the archive. This method works for any project type and allows you to combine the document feature type with all the other feature types DataRobot supports.
When uploading a ZIP file, you can also supply an accompanying CSV file to provide additional information to support the uploaded document. One column within the CSV must contain the document file name being referenced. All other values contained in the row are associated with the document and used as modeling features.
Text extraction with the Document Text Extractor task
DataRobot extracts all text from text PDF documents. If images contain text, that text may or may not be used, depending on how the image was created. To determine if text in an image can be used for modeling, open the image in a PDF editor and try to select it—if you can select the text, DataRobot will use it for modeling. To ensure DataRobot can extract text from any image, you can select the the Tesseract OCR task.
Model with text¶
To start a project using Document AI:
-
Load your prepared dataset file, either via upload or the AI Catalog. Note that:
- Any
documenttype feature is converted to text during modeling (in the blueprint). - Each document is represented as a row.
- All extracted text from the document is represented within a cell for that row.
- Any
-
Verify that DataRobot is using the correct document processing task and set the language.
-
Examine your data after EDA1 (ingest) to understand the content of the dataset.
-
Press start to begin modeling building.
-
Examine your data using the Document AI insights.
Document settings¶
After setting the target, use the Document Settings advanced option to verify or modify the document task type and language.
Set document task¶
Select one of two document tasks to be used in the blueprints. —Document Text Extractor or Tesseract OCR. During EDA1, if DataRobot can detect embedded text it applies Document Text Extractor; otherwise, it selects Tesseract OCR.
- For embedded text, the Document Text Extractor is recommended because it's faster and more accurate.
-
To extract all visible text, including the text from images inside the documents, select the Tesseract OCR task.
-
When PDFs contain scans, it is possible that the scans have quality issues—they contain "noise," the pages are rotated, the contrast is not sharp. Once EDA1 completes, you can view the state of the scans by expanding the
Documenttype entry in the data table:
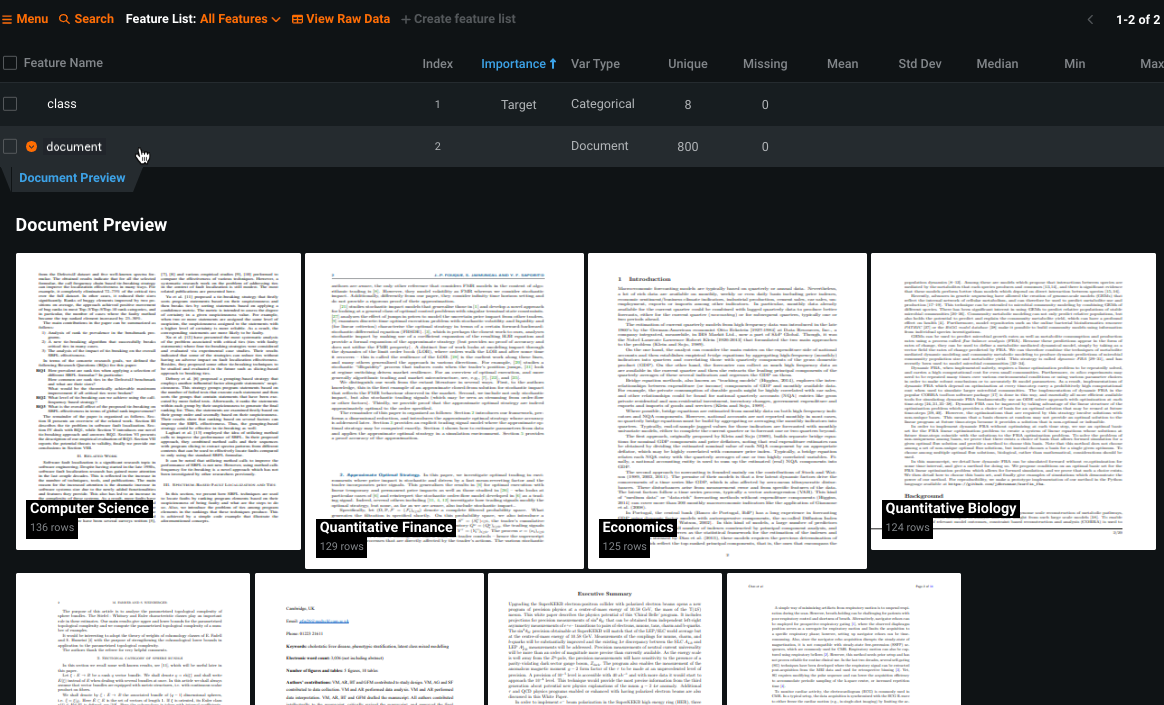
Set language¶
It is important to verify and set the language of the document. The OCR engine must have the correct language set in order to set the appropriate pre-trained language model. DataRobot's OCR engine supports 105 languages.
Data quality¶
If the dataset was loaded to the AI Catalog, use the Profile tab for visual inspection:
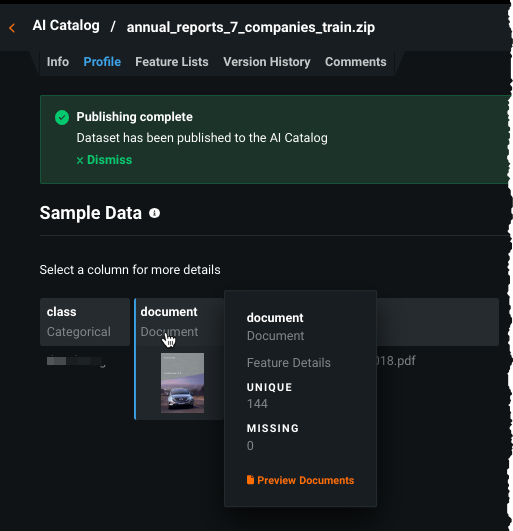
After uploading, examine the data, which shows:
-
The feature names or, if an archive file is separated into folders, a class column—the folder names from the ZIP file.
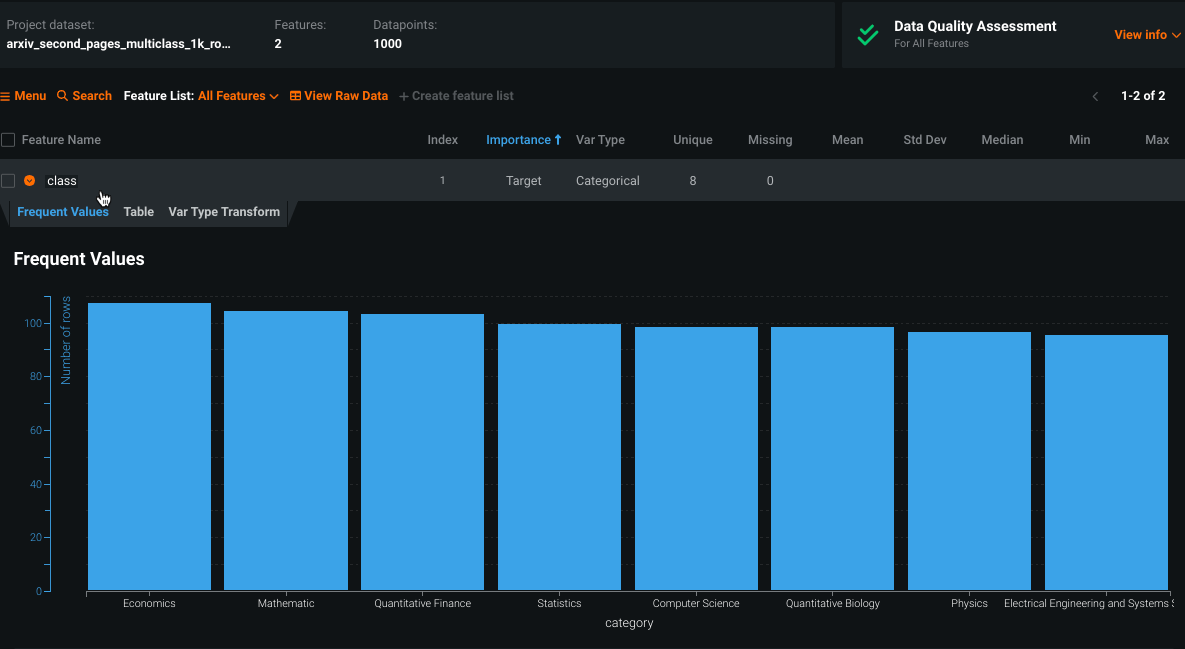
-
The
documenttype features. -
The Reference ID, which provides all the file names to later help identify which predictions belong to which file if no dataset file was provided inside the archive file.
Additionally, DataRobot's Data Quality assessment helps to identify issues so that you can identify errors before modeling.
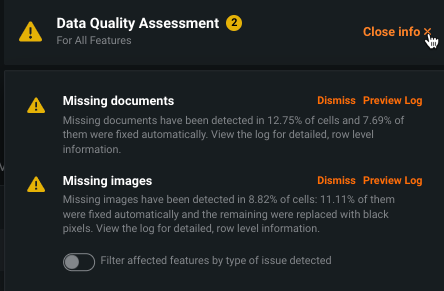
Click Preview log, and optionally download the log, to identify errors and fix the dataset. Some of the errors include:
There is no file with this nameFound empty pathFile not in PDF format or corruptedThe file extension indicates that this file is not of a supported document type
Deep dive: Text handling details¶
DataRobot handles both embedded text and PDFs with scans. Embedded text documents are PDFs that allow you to select and/or search for text in your PDF viewer. PDF with scans are processed via optical character recognition (OCR) —text cannot be searched or selected in your PDF viewer. This is because the text is part of an image within the PDF.
Embedded text¶
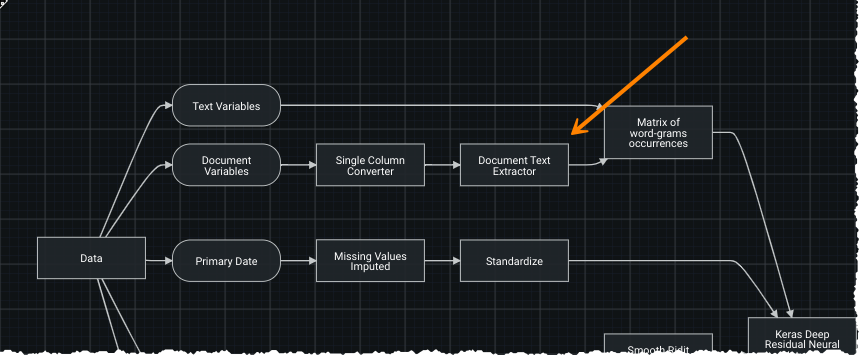
The blueprints available in the Repository are the same as those that would be available for a text variable. While text-based blueprints use text directly, in a blueprint with document variables, you can see the addition of a Document Text Extractor task. It takes the PDF files, extracts the text, and provides the text to all subsequent tasks.
Scanned text (OCR)¶
Because PDF documents with scans do not have the text embedded, the text is not directly machine-readable. DataRobot runs optical character recognition (OCR) on the PDF in an attempt to identify and extract text. Blueprints using OCR use the Tesseract OCR task:

The Tesseract OCR task opens the document, converts each page to an image and then processes the images with the Tesseract library to extract the text from them. The Tesseract OCR task then passes the text to the next blueprint task.
Use the Document Insights visualization after model building to see example pages and the detected text. Because the Tesseract engine can have issues with small fonts, use Advanced Tuning to adjust the resolution.
Base64 strings¶
DataRobot also supports base64-encoded strings. For document (and image) datasets, DataRobot converts PDF files to base64 strings and includes them in the dataset file during ingest. After ingest, instead of a ZIP file there is a single CSV file that includes the images and PDF files as base64 strings.