Configure evaluation and moderation¶
Availability information
Evaluation and moderation guardrails are off by default. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flag: Enable Moderation Guardrails, Enable Global Models in the Model Registry (Premium), Enable Additional Custom Model Output in Prediction Responses
Evaluation and moderation guardrails help your organization block prompt injection and hateful, toxic, or inappropriate prompts and responses. It can also prevent hallucinations or low-confidence responses and, more generally, keep the model on topic. In addition, these guardrails can safeguard against the sharing of personally identifiable information (PII). Many evaluation and moderation guardrails connect a deployed text generation model (LLM) to a deployed guard model. These guard models make predictions on LLM prompts and responses, and then report these predictions and statistics to the central LLM deployment. To use evaluation and moderation guardrails, first, create and deploy guard models to make predictions on an LLM's prompts or responses; for example, a guard model could identify prompt injection or toxic responses. Then, when you create a custom model with the Text Generation target type, define one or more evaluation and moderation guardrails.
Important considerations
Before you configure evaluation and moderation guardrails, you should follow these guidelines while deploying guard models, creating your custom model, and configuring your LLM deployment:
- Create the LLM custom model using larger resource bundles with more memory and CPU resources.
- Deploy the central LLM on a different prediction environment than the deployed guard models.
- Set an association ID and enable prediction storage before you start making predictions through the deployed LLM.
To select and configure evaluation and moderation guardrails:
-
In the Model workshop, open the Assemble tab of a custom model with the Text Generation target type and assemble a model, either manually from a custom model you created outside of DataRobot or automatically from a model built in a Use Case's LLM playground:
When you assemble a text generation model with moderations, ensure you configure any required runtime parameters (for example, credentials) or resource settings (for example, public network access). Finally, set the Base environment to [GenAI] Python 3.11 with Moderations:

-
After you've configured the custom model's required settings, navigate to the Evaluation and Moderation section and click Configure:
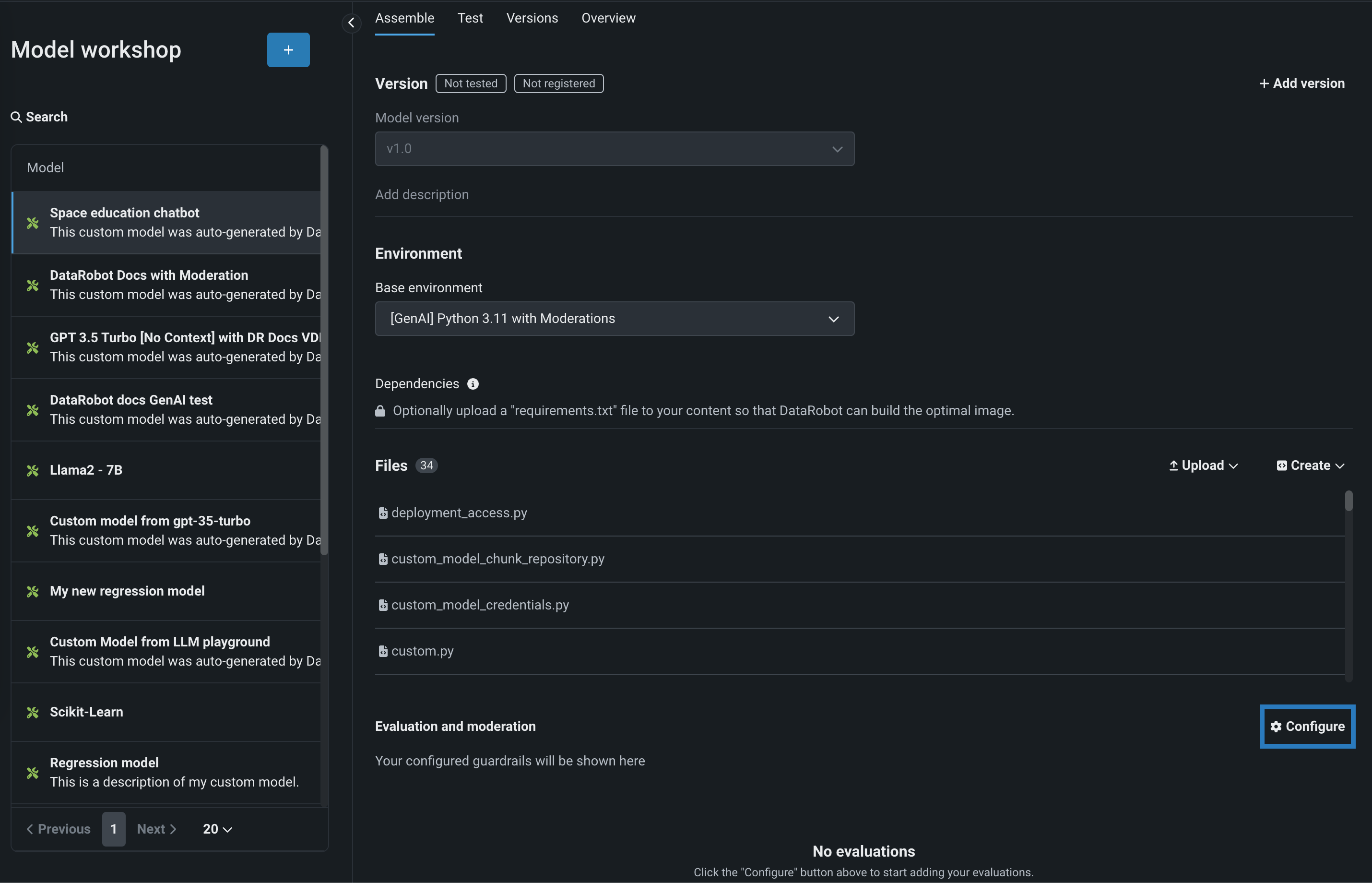
-
In the Configure evaluation and moderation panel, on the Evaluation tab, click one of the following metric cards to configure the required properties:
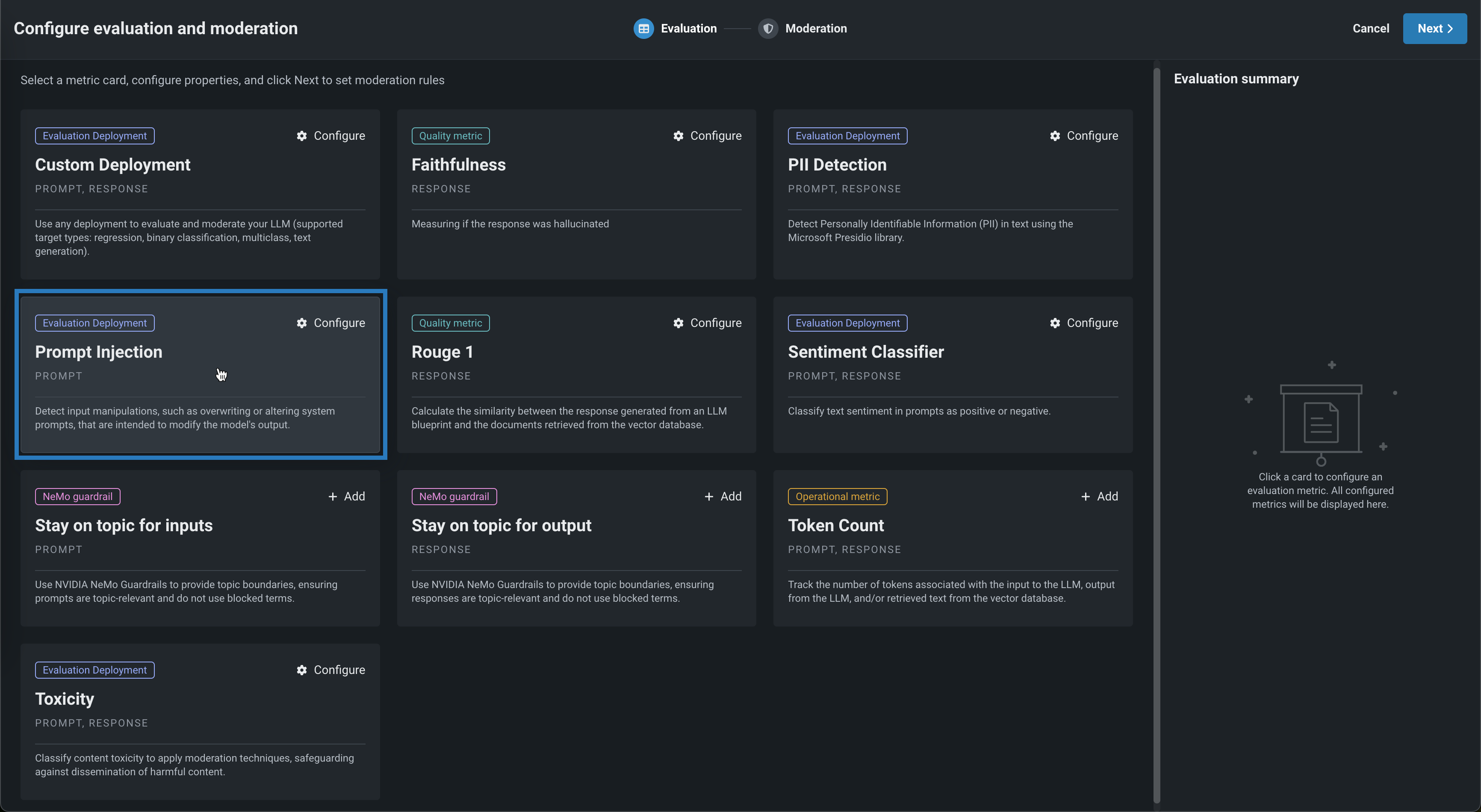
Evaluation metric Deployment or API connection Description Custom Deployment Custom deployment Use any deployment to evaluate and moderate your LLM (supported target types: regression, binary classification, multiclass, text generation). Faithfulness OpenAI API Measure if the LLM response matches the source to identify possible hallucinations. PII Detection Presidio PII Detection Detect Personally Identifiable Information (PII) in text using the Microsoft Presidio library. Prompt Injection Prompt Injection Classifier Detect input manipulations, such as overwriting or altering system prompts, intended to modify the model's output. Rouge 1 N/A Calculate the similarity between the response generated from an LLM blueprint and the documents retrieved from the vector database. Sentiment Classifier Sentiment Classifier Classify text sentiment as positive or negative. Stay on topic for inputs NVIDIA NeMo Guardrails API Use NVIDIA NeMo Guardrails to provide topic boundaries, ensuring prompts are topic-relevant and do not use blocked terms. Stay on topic for output NVIDIA NeMo Guardrails API Use NVIDIA NeMo Guardrails to provide topic boundaries, ensuring responses are topic-relevant and do not use blocked terms. Token Count N/A Track the number of tokens associated with the input to the LLM, output from the LLM, and/or retrieved text from the vector database. Toxicity Toxicity Classifier Classify content toxicity to apply moderation techniques, safeguarding against dissemination of harmful content. Global models
The deployments required for PII detection, prompt injection detection, sentiment classification, and toxicity classification are available as global models in the registry.
-
Depending on the metric selected above, configure the following fields:
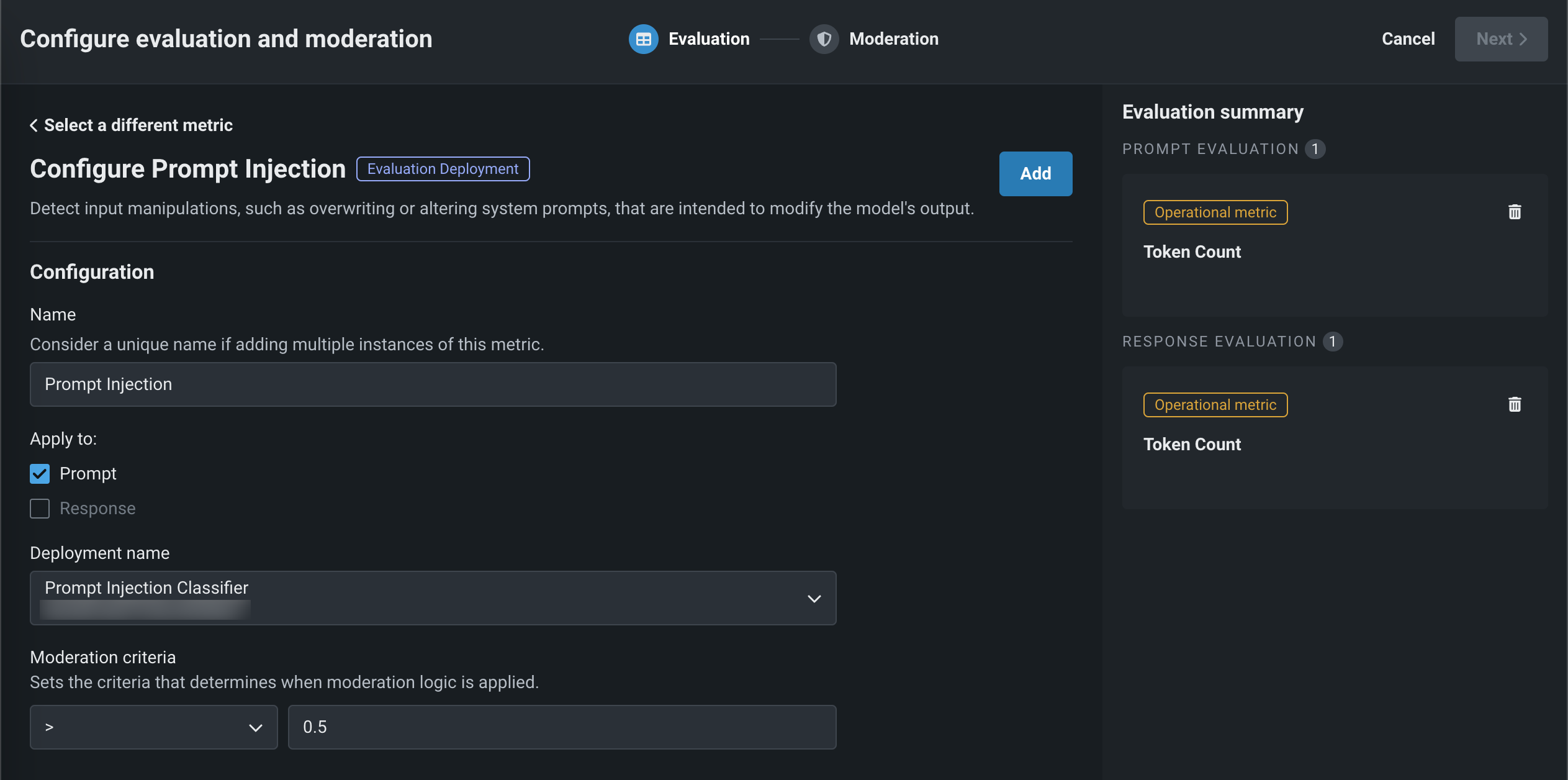
Field Description Name Enter a unique name if adding multiple instances of the evaluation metric. Apply to Select one or both of Prompt and Response, depending on the evaluation metric. Deployment name For evaluation metrics calculated by a guard model, select the model deployment. For a Custom Deployment, you must also configure the Input column name and Output column name. The column names should be suffixed with _PREDICTION, as they rely on the CSV data exported from the deployment. You can confirm the column names by exporting and viewing the CSV data from the custom deployment.OpenAI API For the Faithfulness evaluation metric, enter an OpenAI API base URL, OpenAI API key, and OpenAI API Deployment. NVIDIA API For the Stay on topic evaluations, enter an NVIDIA NeMo Guardrails API key. Files For the Stay on topic evaluations, modify the NeMo guardrails configuration files. Moderation criteria Define the criteria that determines when moderation logic is applied. -
After configuring the required fields, click Add to save the evaluation and return the Evaluation tab. Select and configure another metric, or click Next to proceed to the Moderation tab to configure a moderation strategy.
-
On Moderation tab, set a Moderation strategy for Prompt moderation and Response moderation. For each evaluation metric, select a Moderation method—either Report or Block (if applicable).
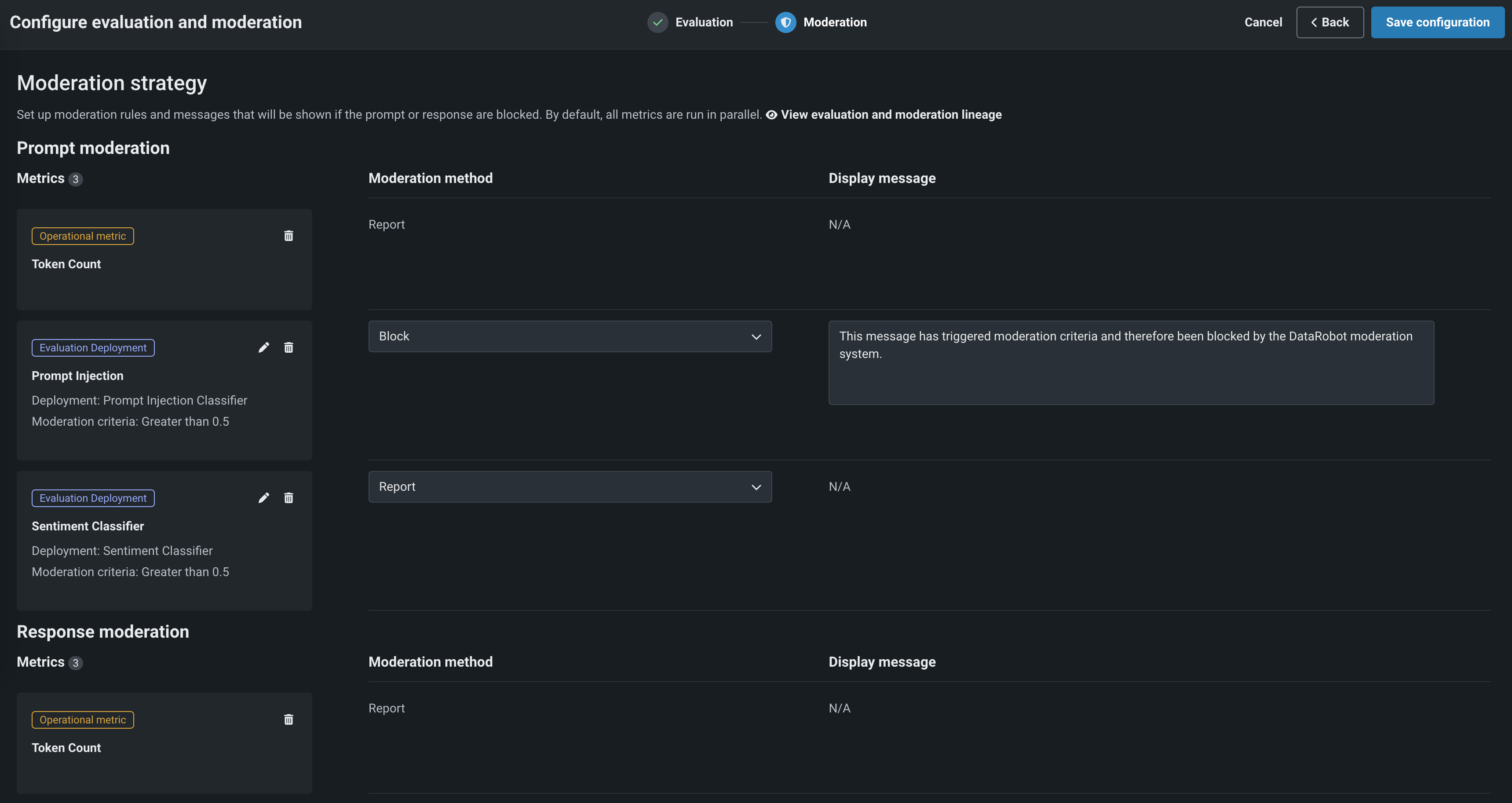
When you select Block, you can optionally configure the default Display message.
-
Click Save configuration.
The guardrails you selected appear in the Evaluation and moderation section of the Assemble tab.
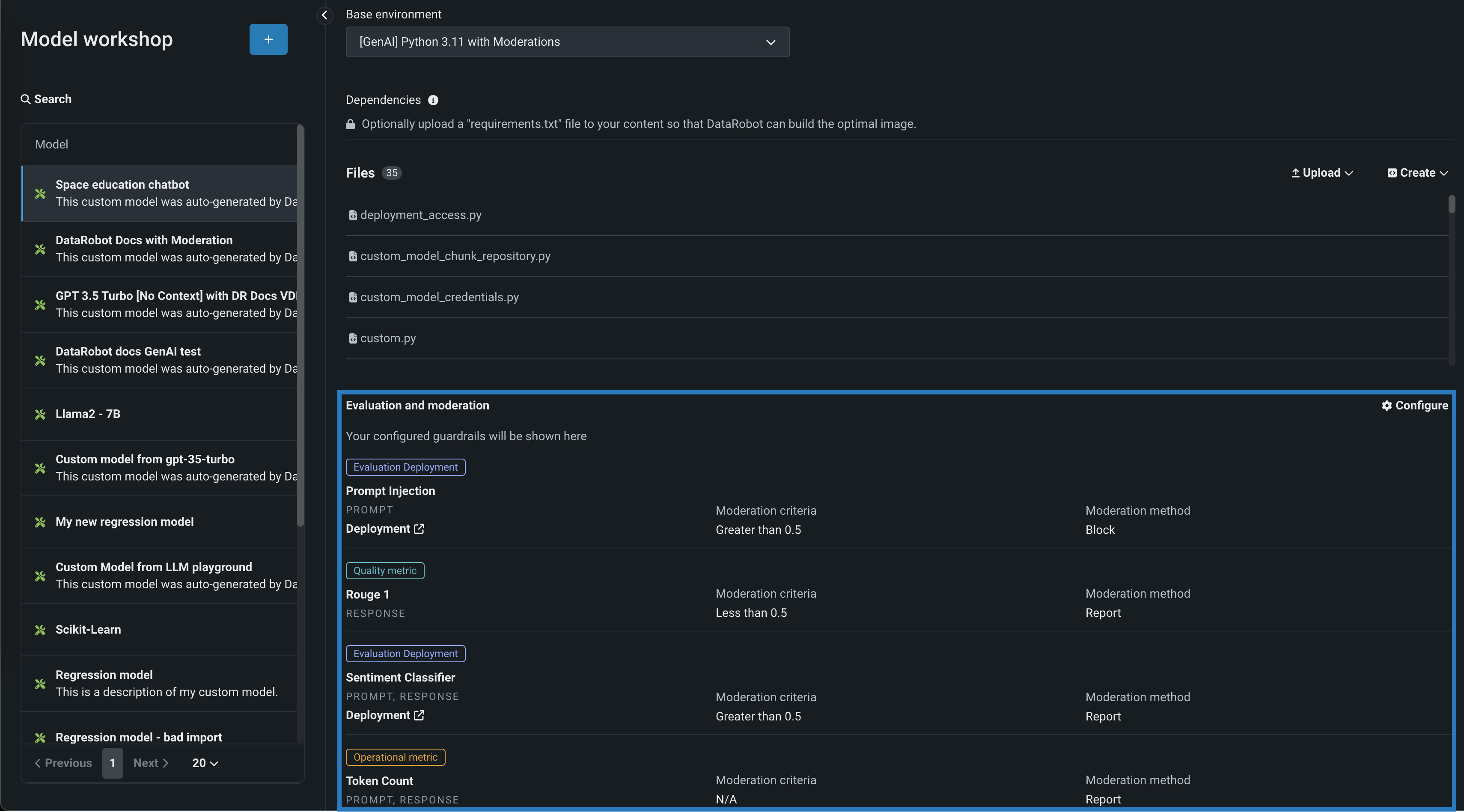
After you add guardrails to a text generation custom model, you can test, register, and deploy the model to make predictions in production. After making predictions, you can view the evaluation metrics on the Custom metrics tab and prompts, responses, and feedback (if configured) on the Data exploration tab.
Data quality tab
When you add moderations to an LLM deployment, you can't view custom metric data by row on the Data exploration > Data quality tab.
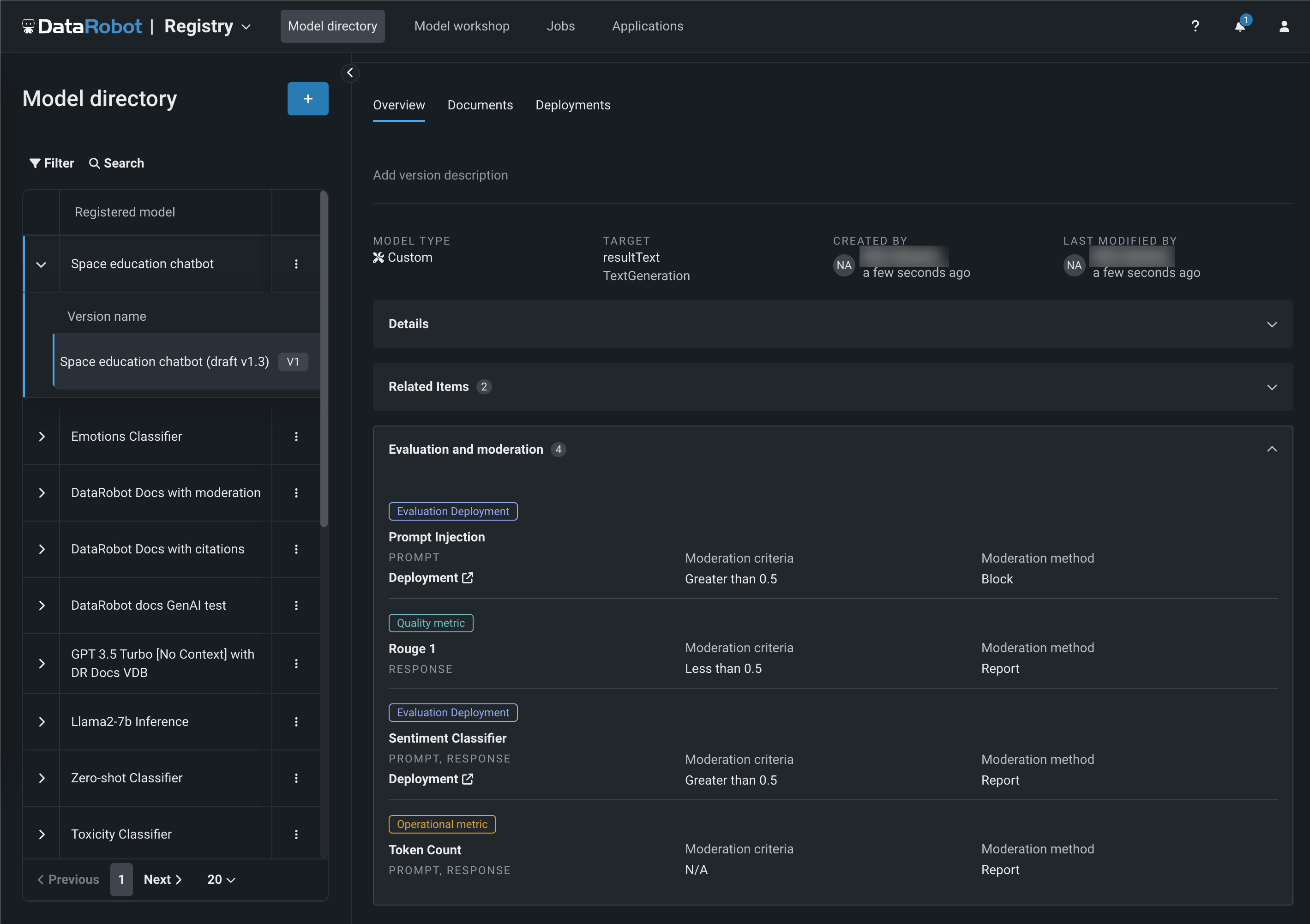
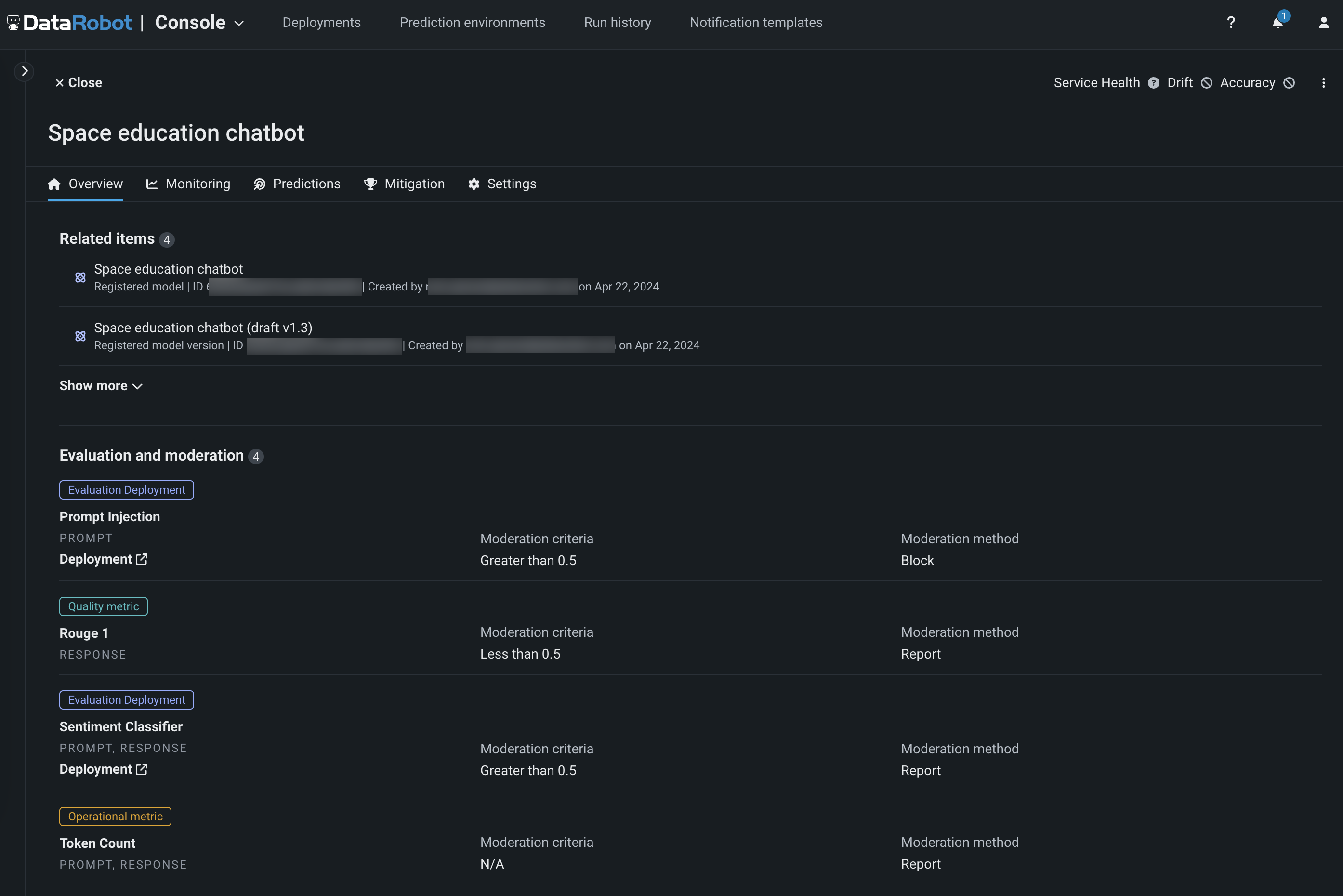
View evaluation and moderation guardrails¶
When a text generation model with guardrails is registered and deployed, you can view the configured guardrails on the registered model's Overview tab and the deployment's Overview tab: