Advanced experiment setup¶
To apply more advanced modeling criteria before training, you can:
- Modify partitioning.
- Configure incremental learning
- Configure additional settings.
- Change configuration settings.
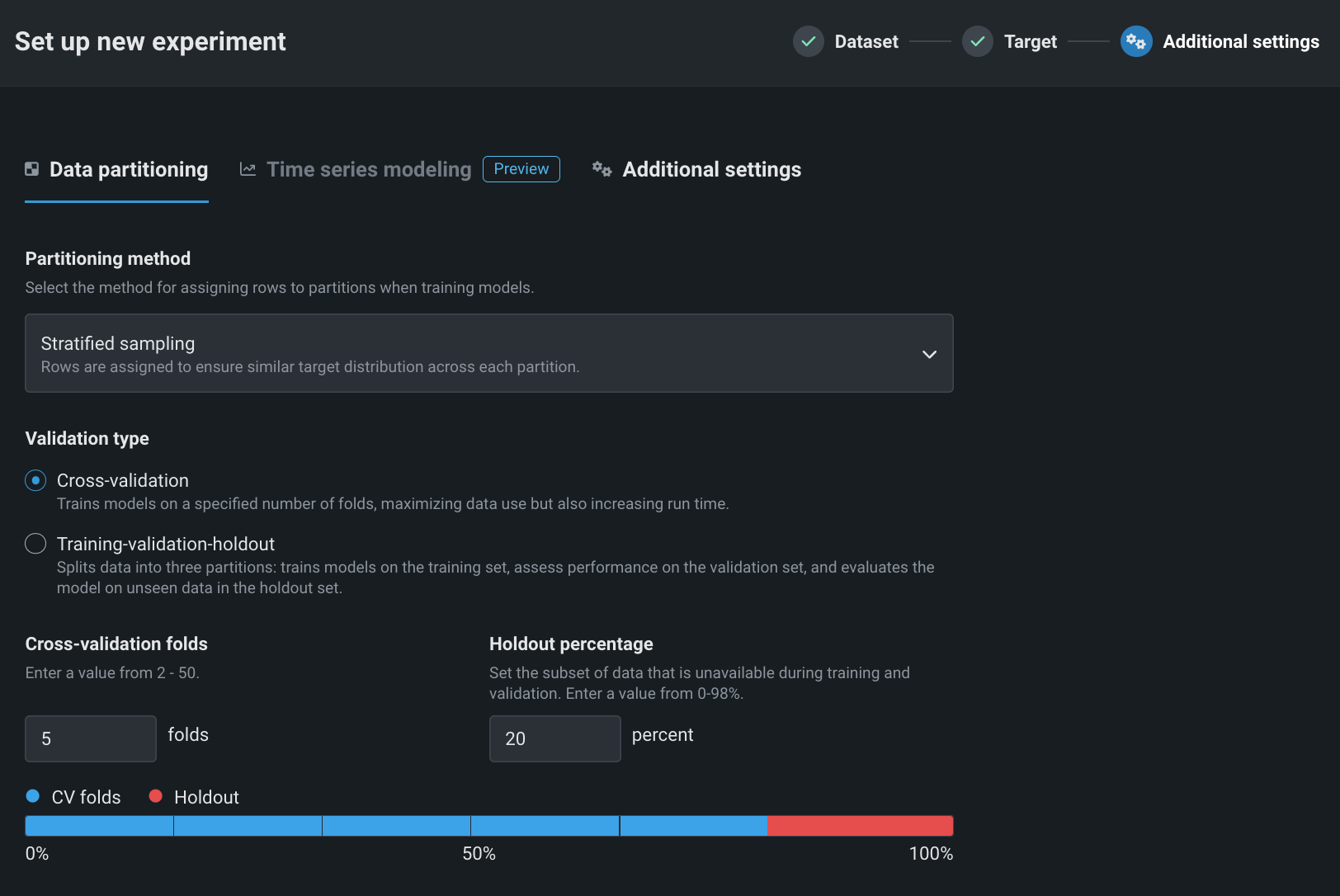
Data partitioning tab¶
Partitioning describes the method DataRobot uses to “clump” observations (or rows) together for evaluation and model building. Workbench defaults to five-fold cross-validation with stratified sampling (for binary classification experiments) or random (for regression experiments) and a 20% holdout fold.
Note
If there is a date feature available, your experiment is eligible for Date/time partitioning, which assigns rows to backtests chronologically instead of, for example, randomly. This is the only valid partitioning method for time-aware projects. See the time-aware modeling documentation for more information.
Change the partitioning method or validation type from Additional settings or by clicking the Partitioning field in the summary:
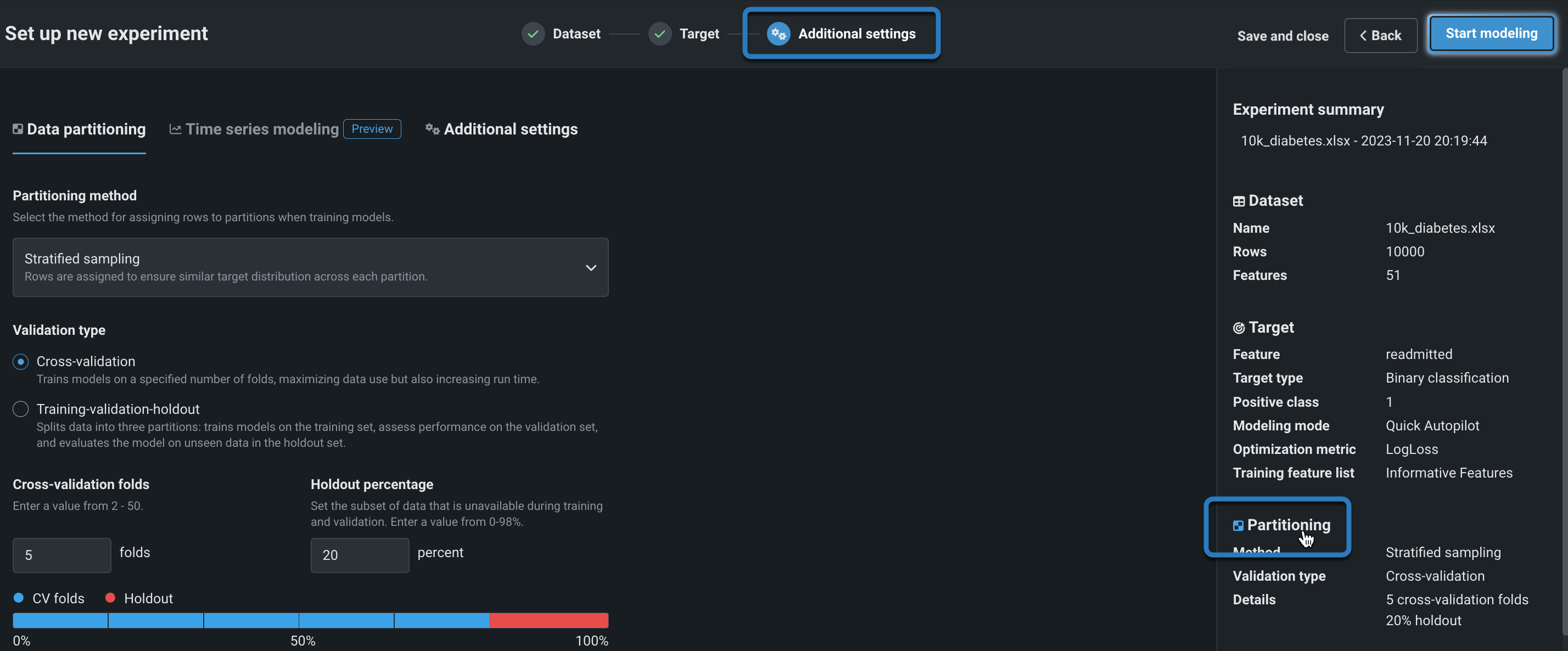
Set the partitioning method¶
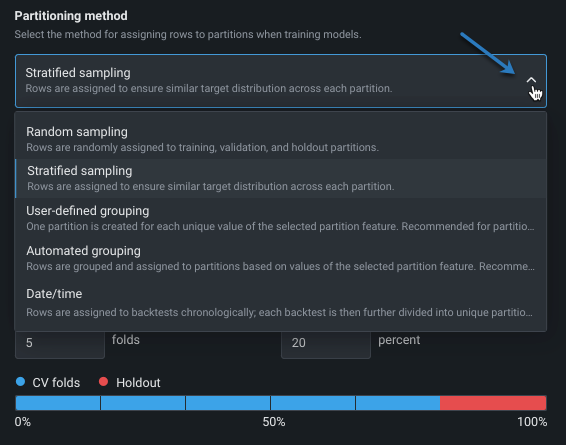
The partitioning method instructs DataRobot on how to assign rows when training models. Note that the choice of partitioning method and validation type is dependent on the target feature and/or partition column. In other words, not all selections will always display as available. The following table briefly describes each method; see also this section for more partitioning details.
| Method | Description |
|---|---|
| Stratified | Rows are randomly assigned to training, validation, and holdout sets, preserving (as close as possible to) the same ratio of values for the prediction target as in the original data. This is the default method for binary classification problems. |
| Random | DataRobot randomly assigns rows to the training, validation, and holdout sets. This is the default method for regression problems. |
| User-defined grouping | Creates a 1:1 mapping between values of this feature and validation partitions. Each unique value receives its own partition, and all rows with that value are placed in that partition. This method is recommended for partition features with low cardinality. See partition by grouping, below. |
| Automated grouping | All rows with the same single value for the selected feature are guaranteed to be in the same training or test set. Each partition can contain more than one value for the feature, but each individual value will be automatically grouped together. This method is recommended for partition features with high cardinality. See partition by grouping, below. |
| Date/time | See time-aware experiments. |
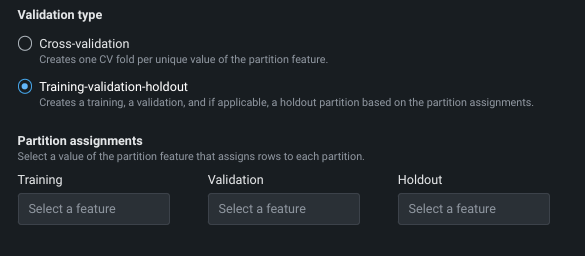
Set the validation type¶
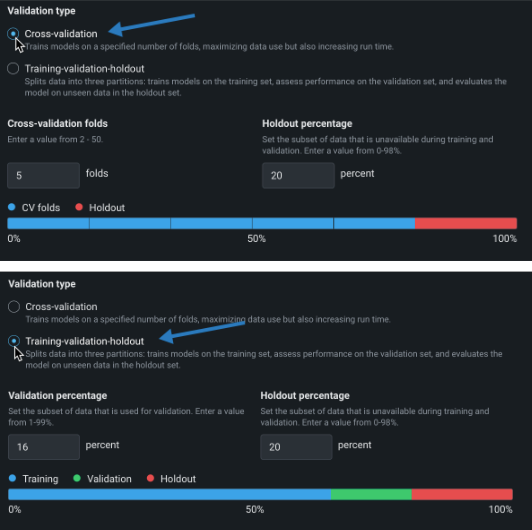
Validation type sets the method used on data to validate models. Choose a method and set the associated fields. A graphic below the configuration fields illustrates the settings. See the description of validation type when using user-defined or automated group partitioning.
| Field | Description |
|---|---|
| Cross-validation: Separates the data into two or more “folds” and creates one model per fold, with the data assigned to that fold used for validation and the rest of the data used for training. | |
| Cross-validation folds | Sets the number of folds used with the cross-validation method. A higher number increases the size of training data available in each fold; consequently increasing the total training time. |
| Holdout percentage | Sets the percentage of data that Workbench “hides” when training. The Leaderboard shows a holdout value, which is calculated using the trained model's predictions on the holdout partition. |
| Training-validation-holdout: For larger datasets, partitions data into three distinct sections—training, validation, and holdout— with predictions based on a single pass over the data. | |
| Validation percentage | Sets the percentage of data that Workbench uses for validation of the trained model. |
| Holdout percentage | Sets the percentage of data that Workbench “hides” when training. The Leaderboard shows a Holdout value, which is calculated using the trained model's predictions on the holdout partition. |
Note
If the dataset exceeds 800MB, training-validation-holdout is the only available validation type for all partitioning methods.
Partition by grouping¶
While less common, user-defined and automated group partitioning provides a method for partitioning by partition feature—a feature from the dataset that is the basis of grouping.
-
With user-defined grouping, one partition is created for each unique value of the selected partition feature. That is, rows are assigned to partitions using the values of the selected partition feature, one partition for each unique value. When this method is selected, DataRobot recommends specifying a feature that has fewer than 10 unique values of the partition feature.
-
With automated grouping, all rows with the same single (specified) value of the partition feature are assigned to the same partition. Each partition can contain multiple values of that feature. When this method is selected, DataRobot recommends specifying a feature that has six or more unique values.
Once either of these methods are selected, you are prompted to enter the partition feature. Help text provides information on the number of values the partition feature must contain; click in the dropdown to view features with a unique value count.
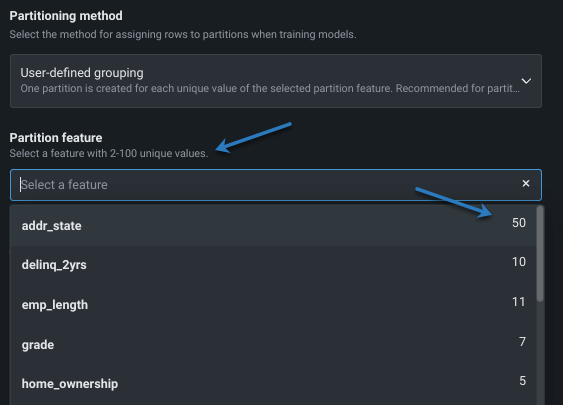
After choosing a partition feature, set the the validation type. The applicability of validation type is dependent on the unique values for the partition features, as illustrated in the following chart.

Automated grouping uses the same validation settings as described above. User-defined grouping, however, prompts for values specific to the partition feature. For cross-validation, setting holdout is optional. If you do set it, you select a value of the partition feature instead of a percentage. For training-validation-holdout, select a value of the partition feature for each section, again instead of a percentage.
Configure incremental learning¶
Availability information
Incremental learning for large datasets is off by default. Contact your DataRobot representative or administrator for information on enabling the feature.
Feature flags:
- Enable Incremental Learning
- Enable Data Chunking
Incremental learning (IL) is a model training method specifically tailored for large datasets—those between 10GB and 100GB—that chunks data and creates training iterations. After model building begins, you can compare trained iterations and optionally assign a different active version or continue training. The active iteration is the basis for other insights and is used for making predictions.
Using the default settings, DataRobot trains the most accurate model on all iterations and all other models on only the first iteration. From the Model Iterations you can train additional increments once models have been built.
IL experiment setup¶
IL is automatically enabled (required) for any dataset larger than 10GB. To begin configuration:
-
From within a Use Case, add a static or snapshotted dataset.
-
After the dataset registers (this can take significantly longer than non-IL experiments), set a binary classification or regression target, which enables IL and makes the settings available.
Tip
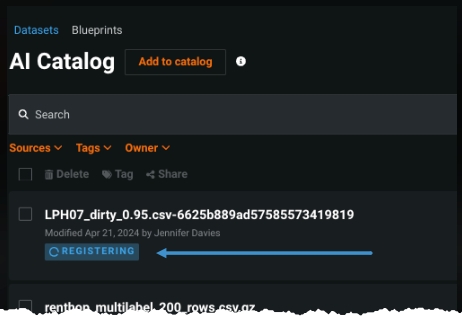
Do not navigate away from the experiment configuration tab before you begin modeling. Otherwise, DataRobot will register the dataset again (which may be time consuming based on size) and the draft that results will not support incremental learning due to the incomplete configuration.
If there is a longer-than-expected delay, you can check the registration status in the AI Catalog:
-
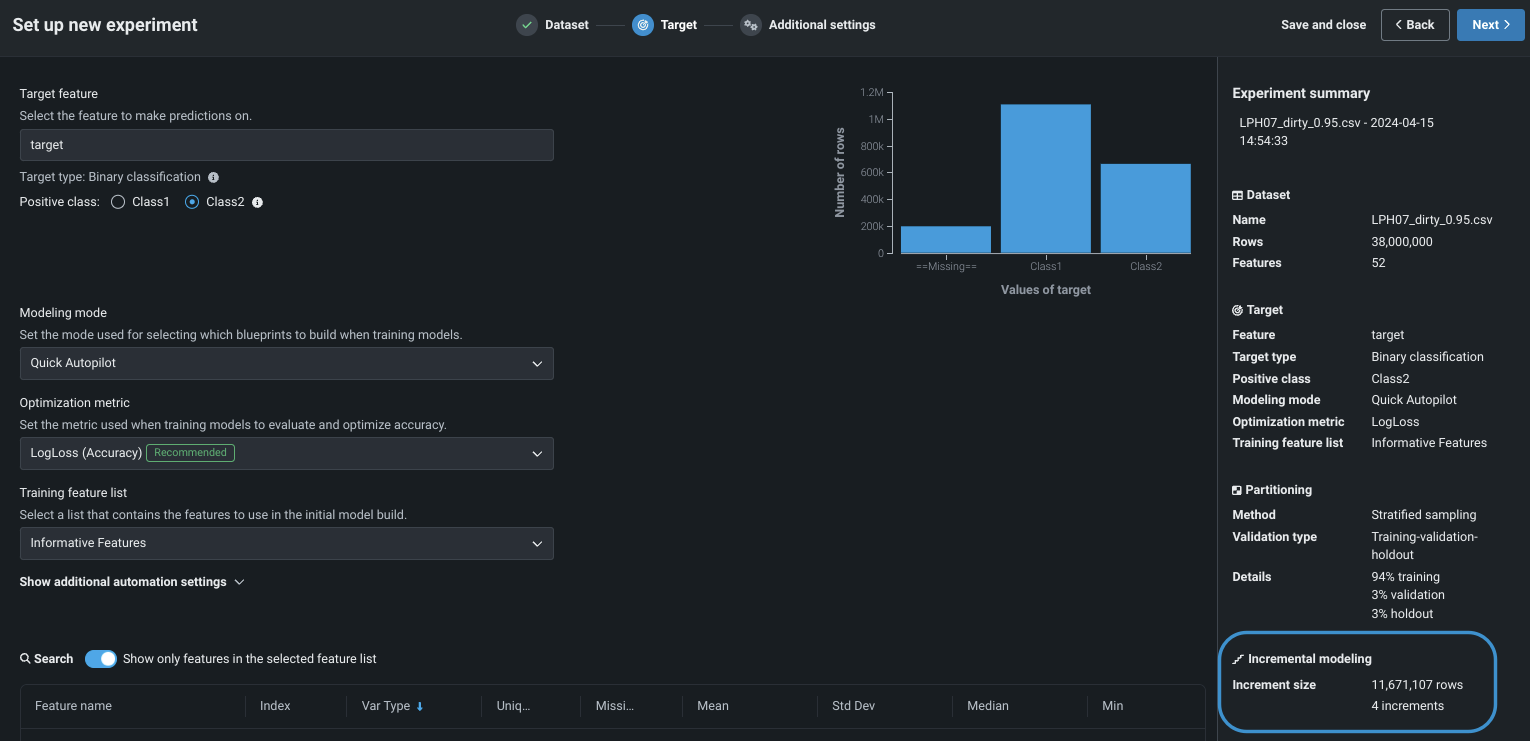
Choose a modeling mode—either Quick Autopilot (the default) or Manual. Comprehensive mode is not available in IL. Notice that the experiment summary updates to show incremental modeling has been activated.
-
Click the Additional settings > Incremental modeling tab:
-
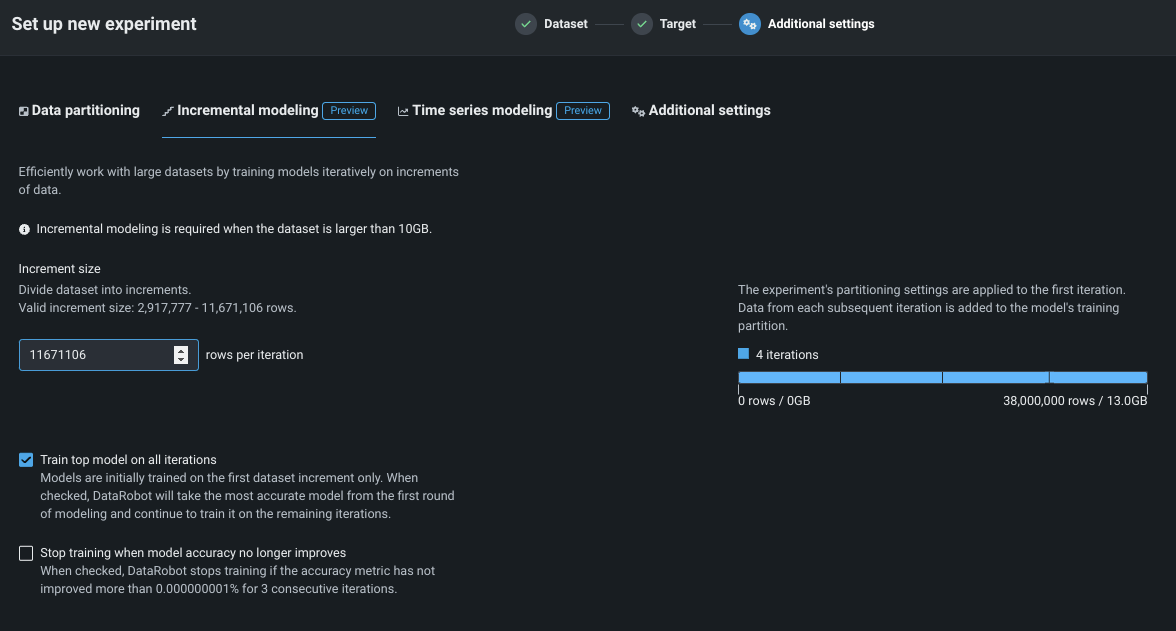
Configure the settings for your project:
Setting Description Increment size Sets the number of rows to assign to each iteration. DataRobot provides the valid range per increment. Train top model on all iterations Sets whether training continues for the top-performing model. When checked, the top-performing model is trained on all increments; other Leaderboard models are trained on a single increment. When unchecked, all models are trained on a single increment. This setting is disabled when manual modeling mode is selected. Stop training when model accuracy no longer improves Sets whether to stop training new model iterations when model accuracy, based on the validation partition, plateaus. Specifically, training ceases when the accuracy metric has not improved more than 0.000000001% over the 3 preceding iterations. A graphic to the right of the settings illustrates the number and size of the increments DataRobot broke the experiment data into. Notice that the graphic changes as the number of increments change.

IL partitioning
Note the following about IL partitioning:
- The experiment’s partitioning settings are applied to the first iteration. Data from each subsequent iteration is added to the model’s training partition.
- Because the first iteration is used for all partitions—training, validation, and holdout—it is smaller than subsequent iterations which only hold training data.
-
Click Start modeling.
-
When the first iteration completes, the Model Iterations insight becomes available on the Leaderboard.
IL considerations¶
Incremental learning is activated automatically when datasets are 10GB or larger. Consider the following when working with IL:
- IL is available for non-time aware binary classification and regression experiments only.
- You cannot restart a draft from a Use Case. You must create a new experiment.
- Default increment size is 4GB.
- Datasets must be either static or snapshots, registered in the AI Catalog. They cannot be directly uploaded from a local computer.
- Datasets must be between 10GB and 100GB.
- IL does not support user-defined grouping, automated grouping, or date/time partitioning methods.
- Comprehensive modeling mode is disabled for IL experiments.
- Cross-validation is not available.
- Monotonic feature constraints, assigning weights, and insurance-specific settings are not supported.
- Sharing is only available at the Use Case level; experiment-level sharing is not supported. When sharing, changing the active iteration is the only available option for any user but the experiment creator. If a user with whom a project was shared trains new iterations, all iterations will error.
- To model on datasets over 10GB, the organization's AI Catalog file size limit must be increased. Contact your administrator.
- Feature Discovery is available on AWS multi-tenant SaaS only. Primary datasets are limited to a maximum of 20GB; secondary datasets can be up to 100GB.
- The following blueprint families are available:
- GBM (Gradient Boosting Machine), such as Light Gradient Boosting on ElasticNet Predictions, eXtreme Gradient Boosted Trees Classifier
- GLMNET (Lasso and ElasticNet regularized generalized linear models), such as Elastic-Net Classifier, Generalized Additive2
- NN (Neural Network), such as Keras
- By default, Feature Effects generates insights for the top 500 features (ranked by feature impact). In consideration of runtime performance, Feature Effects generates insights for the top 100 features in IL experiments.
Configure additional settings¶
Choose the Additional settings tab to set more advanced modeling capabilities. Note that the Time series modeling tab will be available or greyed out depending on whether DataRobot found any date/time features in the dataset.
Configure the following, as required by your business use case.
Monotonic feature constraints¶
Monotonic constraints control the influence, both up and down, between variables and the target. In some use cases (typically insurance and banking), you may want to force the directional relationship between a feature and the target (for example, higher home values should always lead to higher home insurance rates). By training with monotonic constraints, you force certain XGBoost models to learn only monotonic (always increasing or always decreasing) relationships between specific features and the target.
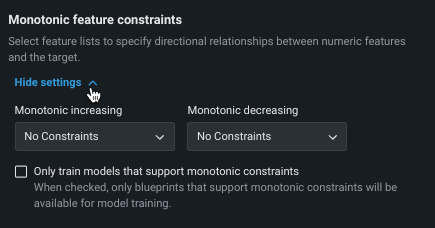
Using the monotonic constraints feature requires creating special feature lists, which are then selected here. Note also that when using Manual mode, available blueprints are marked with a MONO badge to identify supporting models.
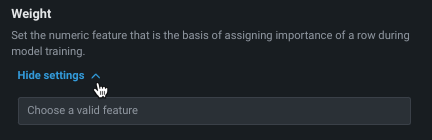
Weight¶
Weight sets a single feature to use as a differential weight, indicating the relative importance of each row. It is used when building or scoring a model—for computing metrics on the Leaderboard—but not for making predictions on new data. All values for the selected feature must be greater than 0. DataRobot runs validation and ensures the selected feature contains only supported values.
Insurance-specific settings¶
Several features are available that address frequent weighting needs of the insurance industry. The table below describes each briefly, but more detailed information can be found here.
| Setting | Description |
|---|---|
| Exposure | In regression problems, sets a feature to be treated with strict proportionality in target predictions, adding a measure of exposure when modeling insurance rates. DataRobot handles a feature selected for Exposure as a special column, adding it to raw predictions when building or scoring a model; the selected column(s) must be present in any dataset later uploaded for predictions. |
| Count of Events | Improves modeling of a zero-inflated target by adding information on the frequency of non-zero events. |
| Offset | Adjusts the model intercept (linear model) or margin (tree-based model) for each sample; it accepts multiple features. |
Change the configuration¶
You can make changes to the project's target or feature list before you begin modeling by returning to the Target page. To return, click the target icon, the Back button, or the Target field in the summary:
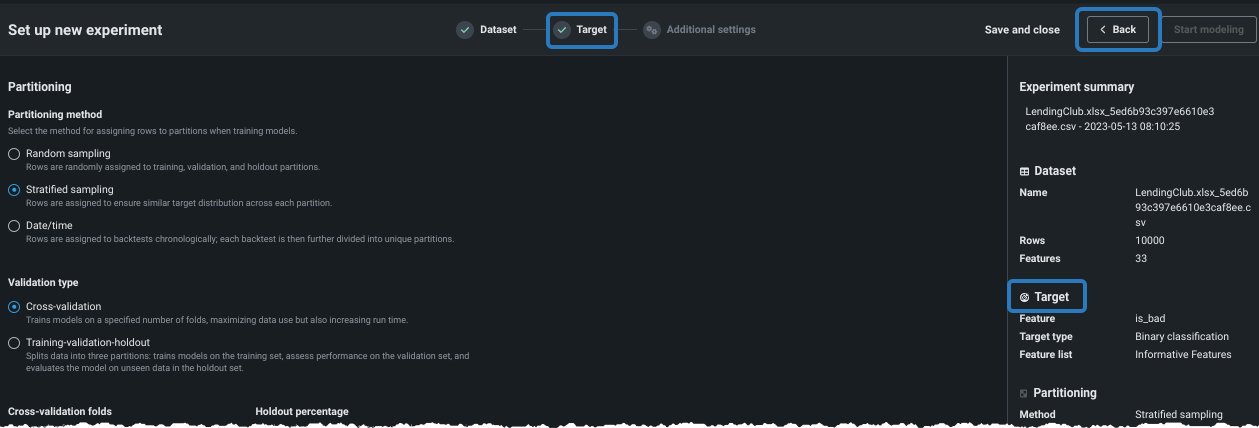
What's next?¶
After you start modeling, DataRobot populates the Leaderboard with models as they complete. You can:
- Use the View experiment info option to view a variety of information about the experiment.
- Begin model evaluation on any available model.