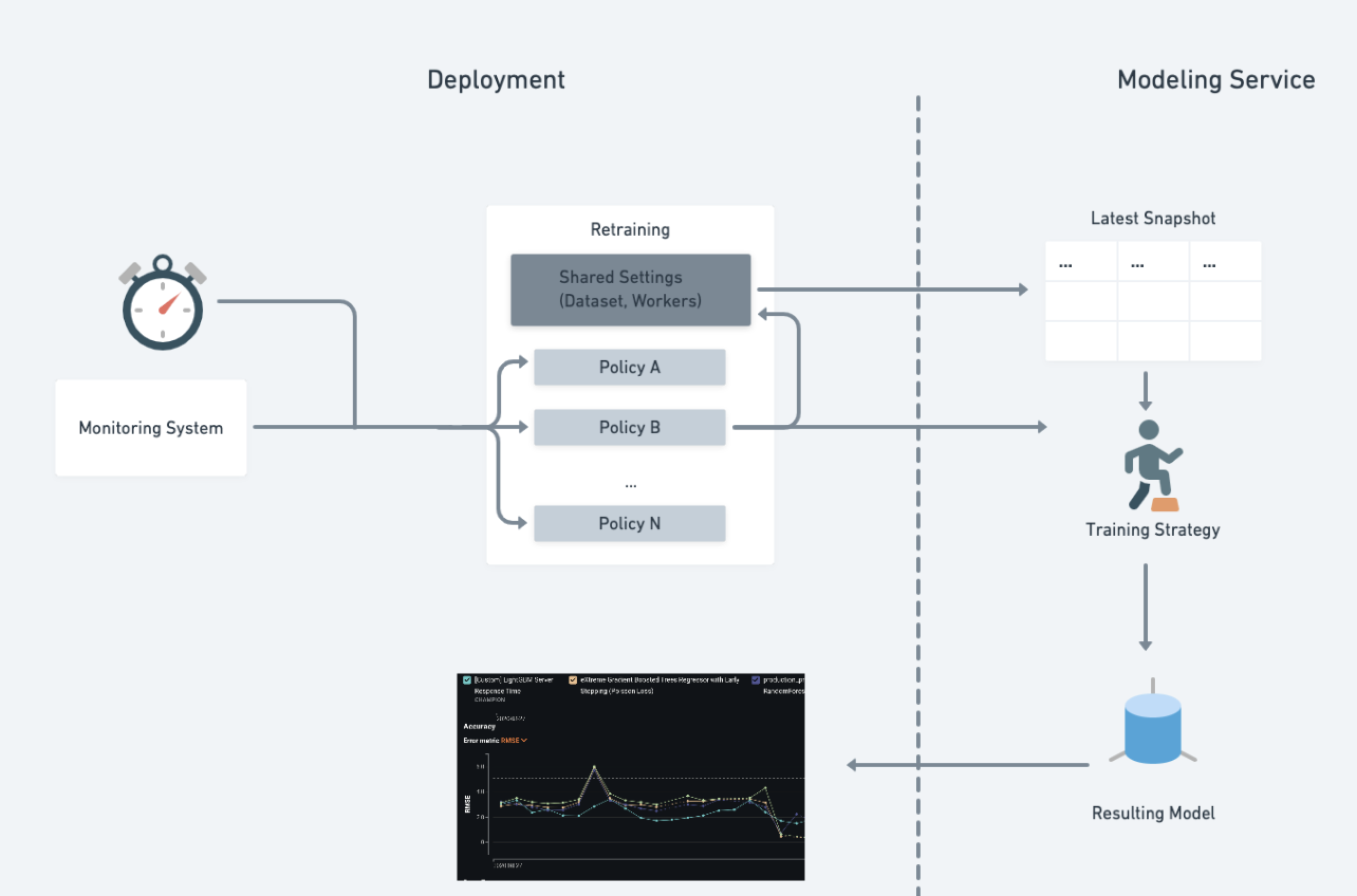
Retraining¶
To maintain model performance after deployment without extensive manual work, DataRobot provides an automatic retraining capability for deployments. On the Mitigation > Retraining tab, upon providing a retraining dataset registered in the Data Registry, you can define up to five retraining policies on each deployment. Each policy consists of a trigger, a modeling strategy, modeling settings, and a replacement action. When triggered, retraining will produce a new model based on these settings and notify you to consider promoting it.
Important
To configure an automated retraining policy, the deployment's retraining settings must be configured.
Create an automated retraining policy¶
To create and define a retraining policy for a deployment, navigate to the deployment's Mitigation > Retraining tab:
-
On the Retraining Summary page, click + Add Retraining Policy.
If you haven't set up retraining, click Configure Retraining and configure the retraining settings.
-
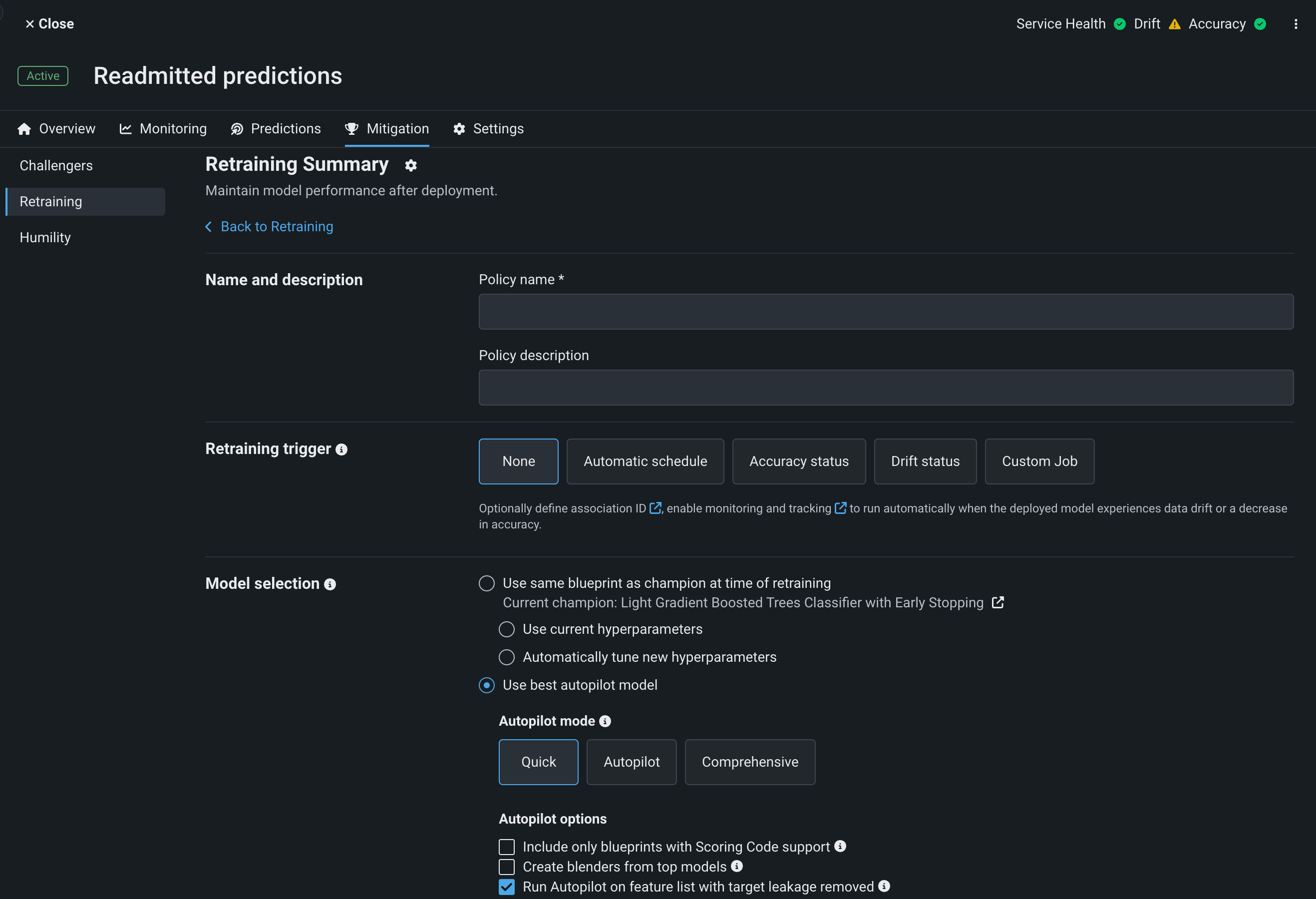
Enter a policy name and, optionally, a policy description.
-
Configure the following retraining policy settings:
-
Retraining trigger: Select the time or deployment status event DataRobot will use to determine when to run retraining.
-
Model selection: Configure the methods DataRobot will use to build the new model on the updated data.
-
Model action: Select the replacement strategy DataRobot will use for the model trained during a successful retraining policy run.
-
Modeling strategy: Configure how DataRobot will set up the new Autopilot project.
-
-
Click Save policy.
Retraining trigger¶
Retraining policies can be triggered manually or in response to three types of conditions:

-
Automatic schedule: Sets the time for the retraining policy to trigger. Choose from increments ranging from every three months to every day. Note that DataRobot uses your local time zone.
-
Accuracy status: Initiates retraining when the deployment's accuracy status changes from a better status to the levels you select (green to yellow, yellow to red, etc.).
-
Drift status: Initiates retraining when the deployment's data drift status declines to the level(s) you select.
-
Custom job (Preview): Initiates retraining based on the conditions defined in the retraining custom job's code.
Availability information
Code-based retraining custom jobs are off by default and require custom jobs and environments. Contact your DataRobot representative or administrator for information on enabling this feature.
Feature flags: Enable Custom Job Based Retraining Polices, Enable Custom Jobs, Enable Notebooks Custom Environments
Drift and accuracy trigger definitions
Data drift and accuracy triggers are based on the definitions configured on the Settings > Data drift and Settings > Accuracy tabs.
Once initiated, a retraining policy cannot be triggered again until it completes. For example, if a retraining policy is set to run every hour but takes more than an hour to complete, it will complete the first run rather than start over or queue with the second scheduled trigger. Only one trigger condition can be chosen for each retraining policy.
Model selection¶
Choose a modeling strategy for the retraining policy. The strategy controls how DataRobot builds the new model on the updated data.
-
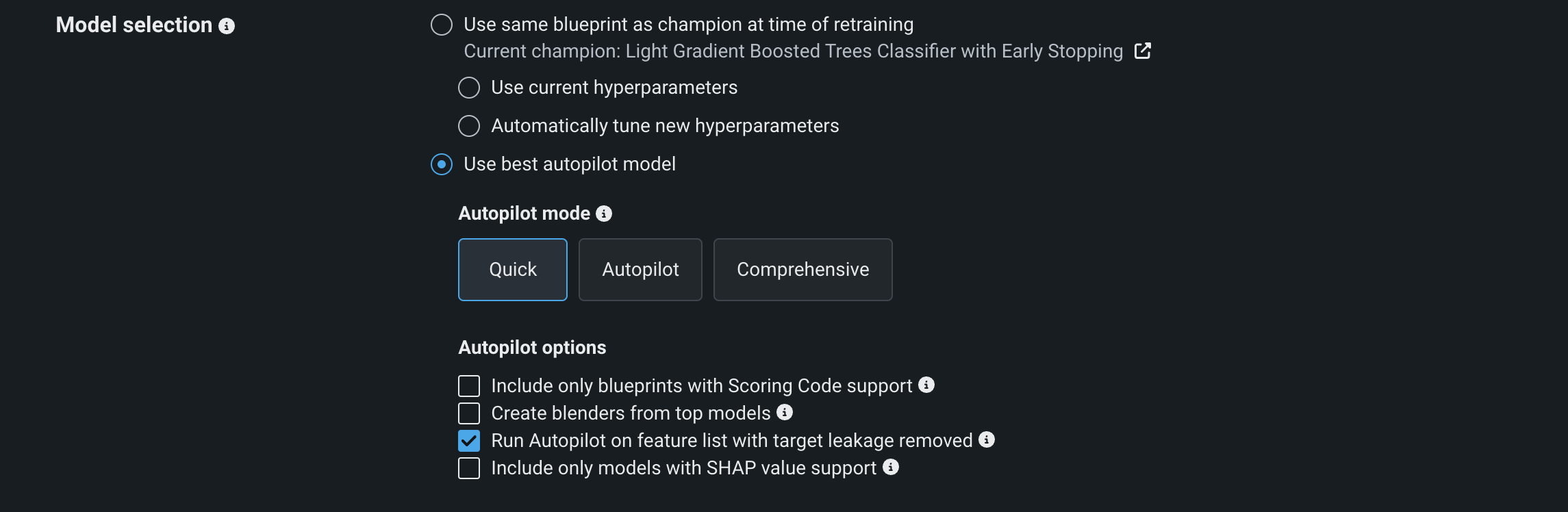
Use same blueprint as champion at time of retraining: At the time of triggering, fits the champion model's blueprint on the new data snapshot. Select one of the following options:
-
Use current hyperparameters: Use the same hyperparameters and blueprint as the champion model. Uses the champion's hyperparameter search and strategy for each task in the blueprint. Note that if you select this option, the champion model's feature list is used for retraining. The Informative Features list cannot be used.
-
Automatically tune hyperparameters: Use the same blueprint but optimize the hyperparameters for retraining.
-
-
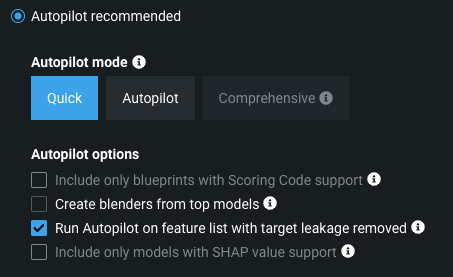
Use best Autopilot model (recommended): Run Autopilot on the new data snapshot and use the resulting recommended model. Choose from Datarobot's three modeling modes: Quick, Autopilot, and Comprehensive.
If selected, you can also toggle additional Autopilot options:
- Only include blueprints that support Scoring Code.
- Create blenders from top-performing models.
- Run Autopilot on a feature list with target leakage removed.
- Only include models that support SHAP values.
Model action¶
The model action determines what happens to the model produced by a successful retraining policy run. In all scenarios, deployment owners are notified of the new model's creation and the new model is added as a model package to the Registry. Apply one of three actions for each policy:

-
Add new model as a challenger model: If there is space in the deployment's five challenger models slots, this action—which is the default—adds the new model as a challenger model. It replaces any model that was previously added by this policy. If no slots are available, and no challenger was previously added by this policy, the model will only be saved to the Registry. Additionally, the retraining policy run fails because the model could not be added as a challenger.
-
Initiate model replacement with new model: Suitable for high-frequency (e.g., daily) replacement scenarios, this option automatically requests a model replacement as soon as the new model is created. This replacement is subject to defined approval policies and their applicability to the given deployment, based on its owners and importance level. Depending on that approval policy, reviewers may need to approve the replacement manually before it occurs.
-
Save model: In this case, no action is taken with the model other than adding it to the Registry.
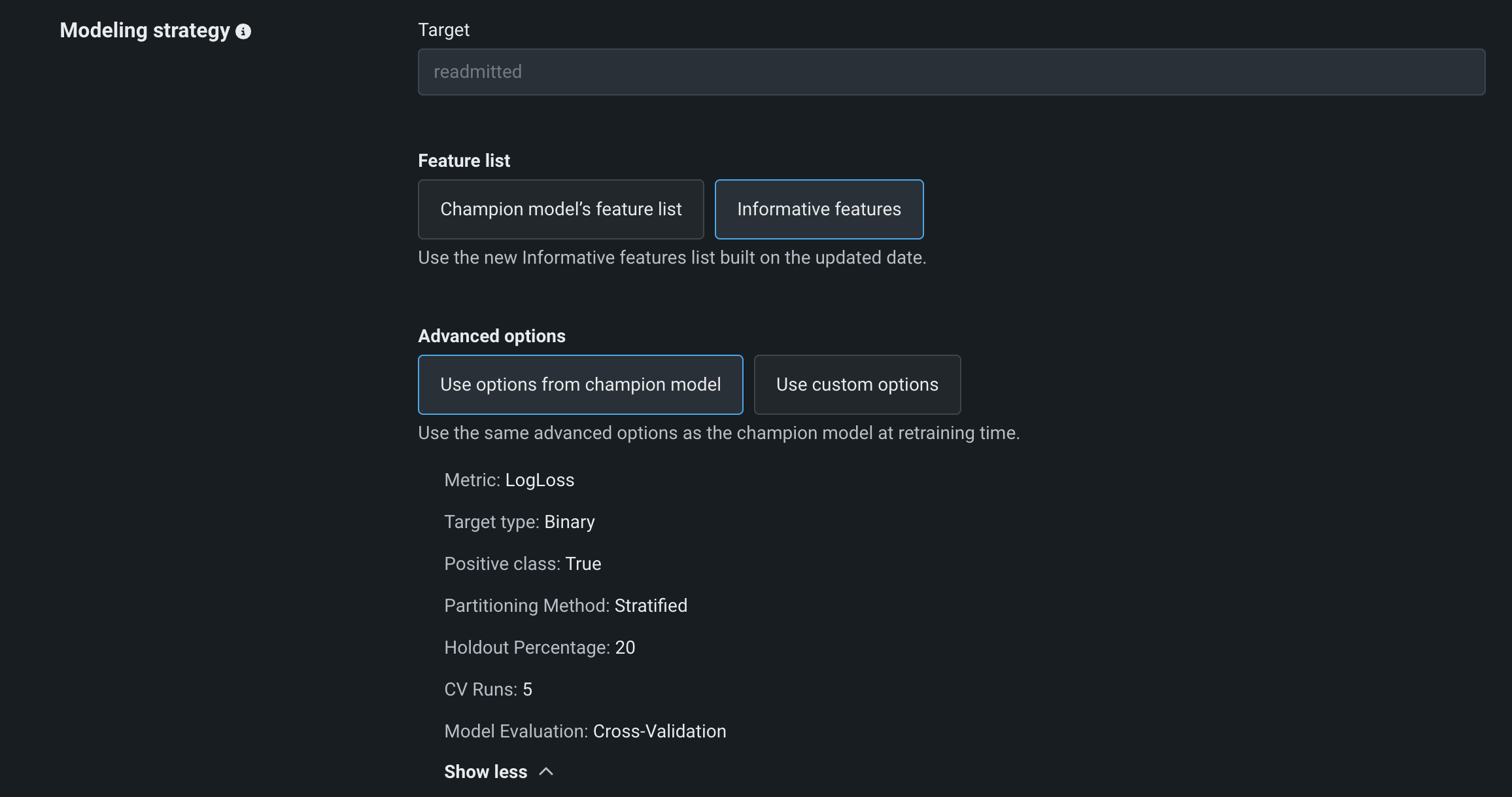
Modeling strategy¶
The retraining modeling strategy defines how DataRobot sets up the new modeling run. Define the features, optimization metric, partitioning strategies, sampling strategies, weights, and other advanced settings that instruct DataRobot on how to build models for a given problem.
You can either build using the same features as the champion model (when the trigger initiates) or allow DataRobot to identify informative features from the new data.
By default, DataRobot reuses the same settings as the champion model (at the time of the trigger initiating). Alternatively, you can define new partitioning settings, choosing from a subset of options that are available when building a new experiment.
Manage retraining policies¶
After creating a retraining policy, you can start it manually, cancel it, or update it, as explained in the table below.

| Element | Definition | |
|---|---|---|
| 1 | Policy | Click the retraining policy row to view information about all previous runs of a training policy, successful or failed, including the start time, end time, duration, and—if the run succeeded—links to the resulting project and model package. |
| 2 | Edit | Click the edit button to edit the policy definition. |
| 3 | Run | Click the run button to start a policy manually. Alternatively, edit the policy by clicking the policy row and scheduling a run using the retraining trigger. |
| 4 | Remove | Click the remove button to delete a policy. Click Remove in the confirmation window. Policies cannot be removed while they are running. |
| 5 | Cancel | Click the cancel button to cancel a policy that is in progress or scheduled to run. You can't cancel a policy if it has finished successfully, reached the "Creating challenger" or "Replacing model" step, failed, or has already been canceled. |
Note
If the retraining user and organization have sufficient workers, multiple policies on the same deployment can be running at once.
Retraining strategies¶
The Challengers and Retraining tabs allow for simple performance comparison, meaning retraining strategies can be evaluated empirically and customized for different use cases. You may benefit from initial experimentation, using various time frames for the "same-blueprint" and Autopilot strategies. For example, consider running "same-blueprint" retraining strategies using both a nightly and a weekly pattern and comparing the results.
Typical strategies for implementing automatic retraining policies in a deployment include:
- High-frequency automatic schedule: Frequently (e.g., daily) retrain the currently deployed blueprint on the newest data to stabilize the deployed model selection.
- Low-frequency automatic schedule: Periodically (e.g., weekly, monthly) run Autopilot to explore alternative modeling techniques and potentially optimize performance. You can restrict this process to only Scoring Code-supported models if that is how you deploy. See the Include only blueprints with Scoring Code support advanced option for more information.
- Drift status trigger: Monitor data drift and trigger Autopilot to prepare an alternative model when the champion model has shown data drift due to changing situations.
- Accuracy status trigger: Monitor accuracy drift and trigger Autopilot to search for a better-performing model after the champion model has shown accuracy decay. This strategy is most effective for use cases with fast access to actuals.
Retraining availability¶
Only binary, multiclass, and regression target types support retraining. The Retraining tab doesn't appear when a deployment's champion has a multilabel target type. See also the handling of time series retraining.
Unsupported models and projects¶
Retraining is not supported for the following DataRobot models and project types. In those cases, the Retraining tab doesn't appear when a deployment's champion uses any of the listed functionality:
- Multilabel modeling projects
- Feature Discovery-based projects
- Unsupervised learning projects (including anomaly detection and clustering)
- Unstructured custom inference models
- Multilabel modeling projects
- Feature Discovery-based projects
- Unsupervised learning projects (including anomaly detection and clustering)
- Unstructured custom inference models
- Imported model packages
Partially supported models¶
The following model types partially support retraining. For each partially supported model, only the supported (✔) options are available in retraining policies on the Retraining tab:
Note
Only some retraining policy options are model-dependent. If the support matrix below doesn't include a model type, all options of a retraining policy are available for configuration.
| Model type | Same blueprint as champion | Champion model's feature list | Project options from champion model | Custom project options |
|---|---|---|---|---|
| Custom inference | ✔ | |||
| External (agent) | ✔ | |||
| Blender* | ✔ | ✔ | ||
| Time series | ✔ | ✔ | ✔ |
* Blender models are not available in Workbench.
Retraining for time series¶
Time series deployments support retraining, but there are limitations when configuring policies due to the time series feature derivation process. This process generates features such as lags and moving averages and creates a new modeling dataset.
Time series model selection¶
Same blueprint as champion: The retraining policy uses the same engineered features as the champion model's blueprint. The search for newly derived features does not occur because it could potentially generate features that are not captured in the champion's blueprint.
Autopilot: When using Autopilot instead of the same blueprint, the time series feature derivation process does occur. However, Comprehensive Autopilot mode is not supported. Additionally, time series Autopilot does not support the option to only include Scoring Code blueprints or models with SHAP value support.
Time series modeling strategy¶
Same blueprint as champion: When creating a "same-blueprint" retraining policy for a time series deployment, you must use the champion model's feature list and advanced modeling options. The only option that you can override is the calendar used because, for example, a new holiday or event may be included in an updated calendar that you want to account for during retraining.
Autopilot: When creating an Autopilot retraining policy for a time series deployment, you must use the informative features modeling strategy. This strategy allows Autopilot to derive a new set of feature lists based on the informative features generated by new or different data. You cannot use the model's original feature list because time series Autopilot uses a feature extraction and reduction process by default. You can, however, override additional modeling options from the champion's project:
| Option | Description |
|---|---|
| Treat as exponential trend | Apply a log-transformation to the target feature. |
| Exponentially weighted moving average (EWMA) | Set a smoothing factor for EWMA. |
| Apply differencing | Set DataRobot to apply differencing to make the target stationary prior to modeling. |
| Add calendar | Upload, add from the catalog, or generate an event file that specifies dates or events that require additional attention. |
Time-aware retraining¶
For time-aware retraining, if you choose to reuse options from the champion model or override the champion model's project options, consider the following:
- If the champion's project used the holdout start date and end date, the retraining project does not use these settings but instead uses holdout duration, the difference between these two dates.
- If the champion project used the holdout duration with either the holdout start date or end date, the holdout start/end date is dropped, and holdout duration is used in the retraining project. A new holdout start date is computed (the end of the retraining dataset minus the holdout duration).
Your customizations to backtests are not retained; however, the number of backtests is retained. At retraining time, the training start and end dates will likely differ from the champion's start and end dates. The data used for retraining might have shifted so that it no longer contains all of the data from a specific backtest on the champion model.